







目录
模型并行
并行化概述
在现代机器学习中,使用各种并行化方法的目的是:
- 克服GPU内存限制。例如:
- 适应非常大的模型 - 例如,t5-11b仅在模型参数方面就达到了45GB
- 适应非常长的序列
- 显著加快训练速度 - 例如,完成原本需要一年的训练工作只需几小时
我们将首先深入讨论各种一维并行化技术及其优缺点,然后看看它们如何结合成二维和三维并行化,以实现更快的训练速度并支持更大的模型。将介绍各种其他强大的替代方法。
为了实现比加速器内存更大的模型的训练和推断,通常使用两种主要方法:
- 三维并行化 - 网络效率非常高,但可能对建模代码产生很大影响,需要更多工作才能正确运行
- ZeRO并行化 - 网络效率不高,但几乎不需要对建模代码进行任何更改,非常容易使其正常工作。
可扩展性概念
以下是将在本文中后续深入描述的主要概念。
- Data Parallelism(DP)- 多次复制相同的设置,并且每个设置都被提供数据的一个切片。处理是并行进行的,所有设置在每个训练步骤结束时进行同步。
- TensorParallelism(TP)- 每个张量被分割成多个块,因此不是整个张量驻留在单个GPU上,而是每个张量的碎片分布在其指定的GPU上。在处理过程中,每个片段在不同的GPU上分别并行处理,并在步骤结束时进行同步。这可以称为水平并行化,因为分割发生在水平级别。
- Pipeline Parallelism(PP)- 模型在垂直(层级)上跨多个GPU进行分割,因此模型的一层或几层仅放置在单个GPU上。每个GPU并行处理管道的不同阶段,并在批次的小块上工作。
- Zero Redundancy Optimizer (ZeRO)- 也执行张量分片,与TP有些相似,但整个张量在前向或后向计算时重新构建,因此无需修改模型。它还支持各种卸载技术来弥补有限的GPU内存。分片的DDP是基本ZeRO概念的另一个名称,被各种其他ZeRO实现所使用。
- Sequence Parallelism - 对长输入序列进行训练需要大量的GPU内存。这种技术将单个序列的处理分割到多个GPU上。
这篇论文Breadth-First Pipeline Parallelism对并行化技术的进行了很好的解释。
Data Parallelism
DDP
如果只有2个gpu,完全可以享受到由于数据并行(DP)和分布式数据并行(DDP)的加速训练的成果。这两种技术都是Pytorch的内置功能。使用起来很简单。更多详情pytorch官方参考。
ZeRO Data Parallelism
下面的图表描述了ZeRO-powered data parallelism(ZeRO-DP),来自微软博文blog post。
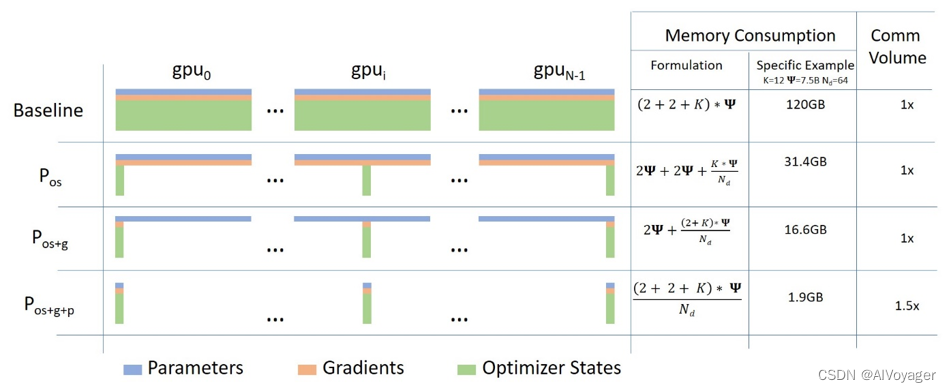
这可能很难让人理解,但实际上这个概念很简单。类似于常见的 DataParallel(DP),但有一个关键区别:每个GPU只存储模型的部分参数,而不是完整的模型参数、梯度和优化器状态。在运行时,当需要某一层的完整参数时,各个GPU会同步以相互提供它们所缺少的部分。这种方法可以帮助减少每个GPU需要存储的参数量,从而降低内存占用并提高效率。这种方式可以在需要时动态地共享参数,而不是静态地复制参数。
假如有一个简单的3层模型,每层有3个参数:
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
层 La 的权重为 a0, a1 and a2.
假如我们有3个gpu, the Sharded DDP (= Zero-DP) 按照如下形式切分整个模型:
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
在某种程度上,这和张量并行是一样的horizontal slicing,如果你想象一下典型的深度神经网络图。垂直切片是指将整个层组放在不同的gpu上。但这只是起点。
每一个gpu中就像工作在DP模式下一样,都将获得mini-batch:
x0 => GPU0
x1 => GPU1
x2 => GPU2
输入是未经修改的——它们认为它们将被正常模型处理。
首先,输入到达La层。
让我们只关注GPU0: x0需要a0, a1, a2参数来完成它的前向路径,但GPU0只有a0——它从GPU1发送a1,从GPU2发送a2,将模型的所有部分放在一起。
并行时,GPU1获得mini-batch x1,它只有a1参数,但需要a0和a2参数,因此它从GPU0和GPU2获取这些参数。同样的事情发生在输入x2的GPU2上。它从GPU0和GPU1得到a0和a1,用a2重建整个张量。所有3个gpu都得到了重建的全部张量,并进行正向计算。一旦计算完成,不再需要的数据就会被丢弃——只在计算过程中使用。重构通过预取有效地完成。
Lb层重复整个过程,然后正向Lc,然后反向Lc -> Lb -> La。
对我来说,这听起来像是一个有效的背包客重量分配策略:
- 一个人扛着帐篷
- B拿着炉子
- C拿着斧头
现在每天晚上他们都和别人分享他们拥有的东西,从别人那里得到他们没有的东西,早上他们打包好配给的装备,继续他们的旅程。这就是Sharded DDP / Zero DP。
将这种策略与每个人都必须自己携带帐篷、炉子和斧头的简单策略进行比较,后者的效率要低得多。这是Pytorch中的DataParallel (DP和DDP)。
在阅读有关此主题的文献时,你可能会遇到以下同义词: Sharded(分片), Partitioned(分区)。
如果您密切关注ZeRO划分模型权重的方式——它看起来非常类似于稍后将讨论的张量并行性。这是因为它对每层的权重进行了分区,而不像下面讨论的vertical model parallelism。
Implementations of ZeRO-DP stages 1+2+3:
- DeepSpeed
- PyTorch (originally it was implemented in FairScale and later it was upstreamed into the PyTorch core)
Deepspeed ZeRO Integration:
FSDP Integration:
Important papers:
Deepspeed:
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
- DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
PyTorch:
Main DeepSpeed ZeRO Resources:
ZeRO with multiple replicas
默认情况下,ZeRO将使用所有GPU创建单个模型副本,即模型分布在所有GPU上。这导致了各种限制,例如:
-
全局批量大小不够灵活 - 它始终是 total_gpus*micro_batch_size 的函数,这在大型集群上可能导致一个巨大的global batch size,这可能对有效收敛不利。固然,可以使用tiny micro batch size来控制global batch size,但这会导致每个GPU上的矩阵更小,从而导致计算效率降低。
-
更快的节点内部网络未能受益,因为更慢的节点间网络定义了通信的整体速度。
ZeRO++通过为ZeRO引入分层权重划分(Hierarchical Weight Partition for ZeRO,hpZ)来解决第二个限制。在这种方法中,不是将整个模型权重分布在所有GPU上,而是将每个模型副本限制在单个节点上。这会增加总节点数量的内存使用量,但现在对于聚合分片组件的2倍 all_gather 调用是在更快的节点内部连接上执行的。只有用于聚合和重新分发梯度的 reduce_scatter 是通过较慢的节点间网络执行的。
第一个限制并没有得到完全解决,因为整体全局批量大小仍然保持不变,但由于每个副本更有效,并且由于额外的内存压力可能限制每个GPU上可能的微批量大小,因此整体应该会提高系统的吞吐量。
PyTorch FSDP 可以实现 shardingStrategy.HYBRID_SHARD
Papers:
- ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
ZeRO variations
Published papers that propose modifications to the ZeRO protocol:
- MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud (2022)
- AMSP: Super-Scaling LLM Training via Advanced Model States Partitioning (2023)
Pipeline Parallelism methods
Naive Model Parallelism (Vertical)
Naive Model Parallelism (MP) 是一种将模型层组分布在多个GPU上的方法。其机制相对简单 - 将所需的层.to()到所需的设备,现在每当数据进出这些层时,将数据切换到与层相同的设备,并保持其余部分不变。
将其称为垂直模型并行,因为如果你记得大多数模型是如何绘制的,我们是垂直切分层。例如,如果以下图表显示一个具有8层的模型:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
gpu0 gpu1
我们只是垂直切分成2部分,将层0-3放在GPU0上,将层4-7放在GPU1上。
当数据从层0传输到1,从1到2,从2到3时,这是正常模型。但是,当数据需要从第3层传输到第4层时,它需要从GPU0传输到GPU1,这引入了通信开销。如果参与的GPU在同一计算节点上(例如同一物理机器),则这种复制速度相当快,但如果GPU位于不同的计算节点上(例如多台机器),通信开销可能会显著增加。
然后,层4到5到6到7就像正常模型一样,当第7层完成时,通常需要将数据发送回第0层,其中包含标签(或者将标签发送到最后一层)。现在可以计算损失并让优化器进行工作。
问题:
主要的不足之处,以及为什么这被称为“天真”MP,是在任何给定时刻除了一个GPU之外的所有GPU都处于空闲状态。因此,如果使用4个GPU,几乎与将单个GPU的内存量增加四倍相同,并忽略其他硬件。此外,存在在设备之间复制数据的开销。因此,使用天真MP,4张6GB的卡将能够容纳与1张24GB卡相同大小的模型,只是后者会更快地完成训练,因为它没有数据复制开销。但是,例如,如果您有40GB的卡并且需要适应一个45GB的模型,您可以使用4张40GB的卡(但可能仅限于梯度和优化器状态)。
共享的嵌入可能需要在GPU之间来回复制。
流水线并行
流水线并行(Pipeline Parallelism,PP)与天真MP几乎相同,但它通过将传入批次分块为微批次并人为创建一个流水线来解决GPU空闲问题,从而使不同的GPU能够同时参与计算过程。
来自GPipe论文的下图说明了顶部是天真MP,底部是PP:
mp-pp
从底部图中很容易看出,PP具有较少的空闲区域,即GPU处于空闲状态的部分被称为“气泡”。
图中的两部分都显示了一个度为4的并行性。也就是说,有4个GPU参与流水线。因此,有4个管道阶段F0、F1、F2和F3的正向路径,然后是逆向路径B3、B2、B1和B0。
PP引入了一个新的超参数需要调整,即chunks,它定义了在同一管道阶段中连续发送多少个数据块。例如,在底部图中,您可以看到chunks=4。GPU0在块0、1、2和3(F0,0、F0,1、F0,2、F0,3)上执行相同的正向路径,然后它等待其他GPU完成他们的工作,只有当他们的工作开始完成时,GPU0才开始工作,对块3、2、1和0(B0,3、B0,2、B0,1、B0,0)执行逆向路径。
请注意,概念上,这与梯度累积步骤(GAS)是相同的概念。Pytorch使用chunks,而DeepSpeed将同一超参数称为GAS。
由于chunks,PP引入了微批次(MBS)的概念。DP将全局数据批次大小分成小批次,因此如果您的DP度为4,全局批次大小为1024,则将其分成4个每个256的小批次(1024/4)。如果chunks(或GAS)的数量为32,我们最终得到一个微批次大小为8(256/32)。每个管道阶段一次处理一个微批次。
要计算DP + PP设置的全局批次大小,我们进行以下计算:mbschunksdp_degree(8324=1024)。
回到图表。
当chunks=1时,您最终得到天真MP,这是非常低效的。当chunks值很大时,您最终得到微小的微批次大小,这可能也不是很有效。因此,人们必须进行实验,找到能够最高效利用GPU的值。
虽然图表显示存在一个“死”时间气泡,因为最后一个forward阶段必须等待backward完成流水线,但是找到最佳的chunks值的目的是实现所有参与GPU的高并发利用,从而最小化气泡的大小。
选择调度方式对于高效性能至关重要:
- sequential Gpipe: Efficient training of giant neural networks using pipeline parallelism
- interleaved 1F1B Pipedream: Fast and efficient pipeline parallel dnn training
- looped, depth-first Efficient large-scale language model training on gpu clusters using Megatron-LM
- breadth-first Breadth-First Pipeline Parallelism
待更新。。。
如何选择使用哪种策略
下面是在什么情况下使用并行策略的大致提纲。每个列表中的第一个通常更快。
⇨ Single GPU
-
模型可以放入一个GPU:
- 正常使用
-
模型可以无法放入一个GPU:
- ZeRO + Offload CPU and optionally NVMe
- as above plus Memory Centric Tiling (see below for details) if the largest layer can’t fit into a single GPU
-
最大层无法放入单个GPU:
- ZeRO - Enable Memory Centric Tiling (MCT). 可以通过自动拆分并顺序执行任意大型层来运行它们。MCT减少了GPU上的参数数量,但它不影响激活内存。需要手动重写
torch.nn.Linear。
⇨ Single Node / Multi-GPU
-
模型可以放入一个GPU:
- DDP - Distributed DP
- ZeRO - may or may not be faster depending on the situation and configuration used
-
模型可以无法放入一个GPU:
- PP
- ZeRO
- TP
With very fast intra-node connectivity of NVLINK or NVSwitch all three should be mostly on par, without these PP will be faster than TP or ZeRO. The degree of TP may also make a difference. Best to experiment to find the winner on your particular setup.
TP is almost always used within a single node. That is TP size <= gpus per node.
-
最大层无法放入单个GPU:
- If not using ZeRO - must use TP, as PP alone won’t be able to fit.
- With ZeRO see the same entry for “Single GPU” above
⇨ Multi-Node / Multi-GPU
-
If the model fits into a single node first try ZeRO with multiple replicas, because then you will be doing ZeRO over the faster intra-node connectivity, and DDP over slower inter-node
-
节点间通信很快:
- ZeRO - as it requires close to no modifications to the model
- PP+TP+DP - less communications, but requires massive changes to the model
-
当你的节点间通信缓慢和GPU内存小::
- DP+PP+TP+ZeRO-1
参考:
- https://huggingface.co/docs/transformers/perf_train_gpu_many#efficient-training-on-multiple-gpus
- https://huggingface.co/transformers/v4.9.2/parallelism.html#














 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









