







LLM数据工程3——数据收集魔法:获取顶级训练数据的方法
本文是DataTager团队关于大模型数据的系列文章十万字总结《从数据到AGI:开启大模型智能的秘密》中的数据收集部分,以下是本文的同步链接:
https://huggingface.co/blog/JessyTsu1/data-collect-zh
https://datatager.com/blog/data_collect_zh
https://zhuanlan.zhihu.com/p/700613165
ChatGPT诞生一年多后的今天,人们逐渐理解了大模型的运行逻辑,并在积极探索其落地场景。我们始终坚信大模型是一个以数据为中心的领域(data-centric),而不是以模型为中心(model-centric)。因此,在大模型时代的探索中,我们积累了大量关于数据的经验和思考,并将这些经验汇集成系列文章《从数据到AGI:开启大模型智能的秘密》。基于这些经验,我们还开发了产品DataTager,会在随后上线。
数据在大模型中的作用已经不言而喻。合理地收集数据以及选择收集哪些数据是一个非常重要的话题。接下来,我们将详细探讨几种主要的数据收集方法,分析其优缺点和实际应用情况。
一、爬虫
当我们在某个网站看到很不错的合适的数据的时候,第一想法就是把他们全部下载到本地,以供模型训练,所以便有了爬虫
概念和原理
- 爬虫是一种自动化程序,用于在互联网上系统地浏览和提取数据。它们通过模拟用户行为,访问网页并提取所需的信息。
优点
- 大规模数据获取:网络爬虫能够从大量网站上获取海量数据,为模型训练提供丰富的语料。
- 高频率更新:爬虫可以定期抓取最新的数据,确保数据的时效性和新鲜度。
传统工具
- Scrapy:一个强大的Python爬虫框架,适合大规模爬取项目。
- 特点:模块化设计、支持多线程、强大的抓取和处理能力。
- 使用场景:适用于需要处理大量数据的网站爬取,例如电商、新闻门户。
pip install scrapy
cat > myspider.py <<EOF
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
EOF
scrapy runspider myspider.py
- Beautiful Soup:一个用于解析HTML和XML文档的Python库,适合小规模数据抓取。
- 特点:易于学习和使用、能够快速解析和处理HTML内容。
- 使用场景:适用于结构简单、数据量较小的网站。
- Selenium:一个用于自动化Web浏览的工具,能够处理动态加载的网页内容。
- 特点:支持JavaScript渲染、能够模拟用户操作。
- 使用场景:适用于需要处理动态内容的网站,如实时数据更新的页面。
新型AI爬虫
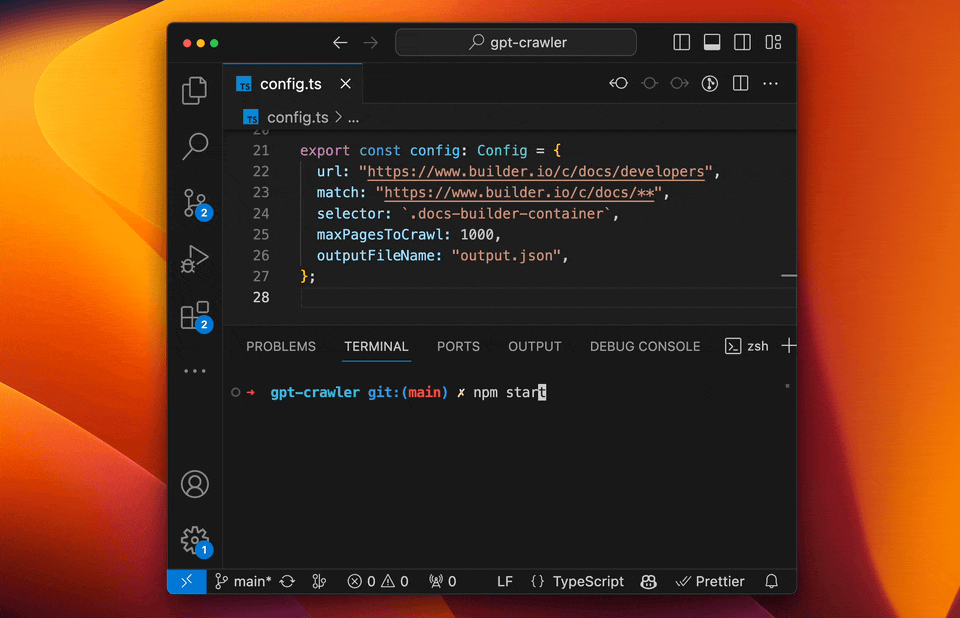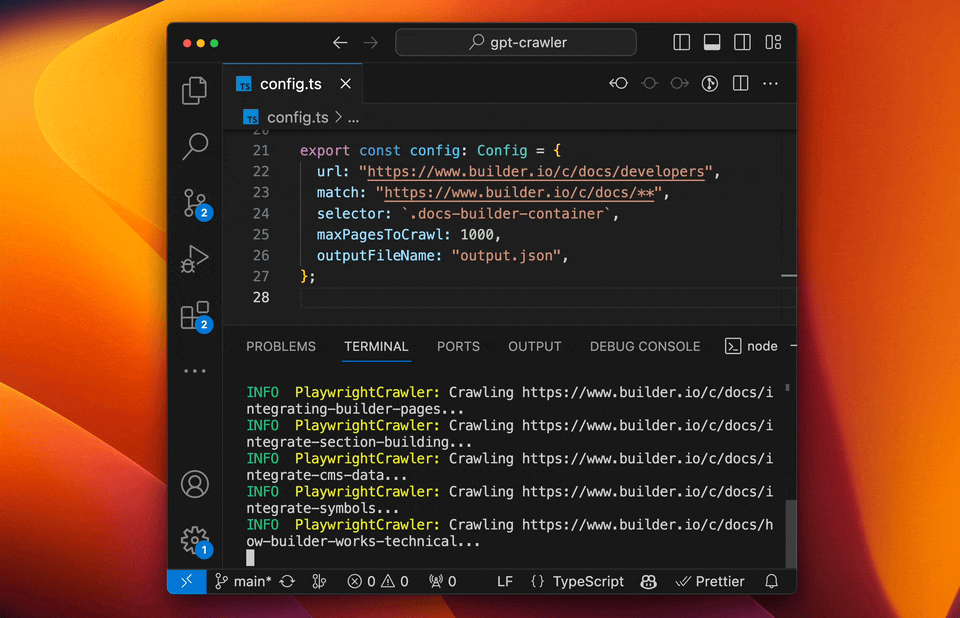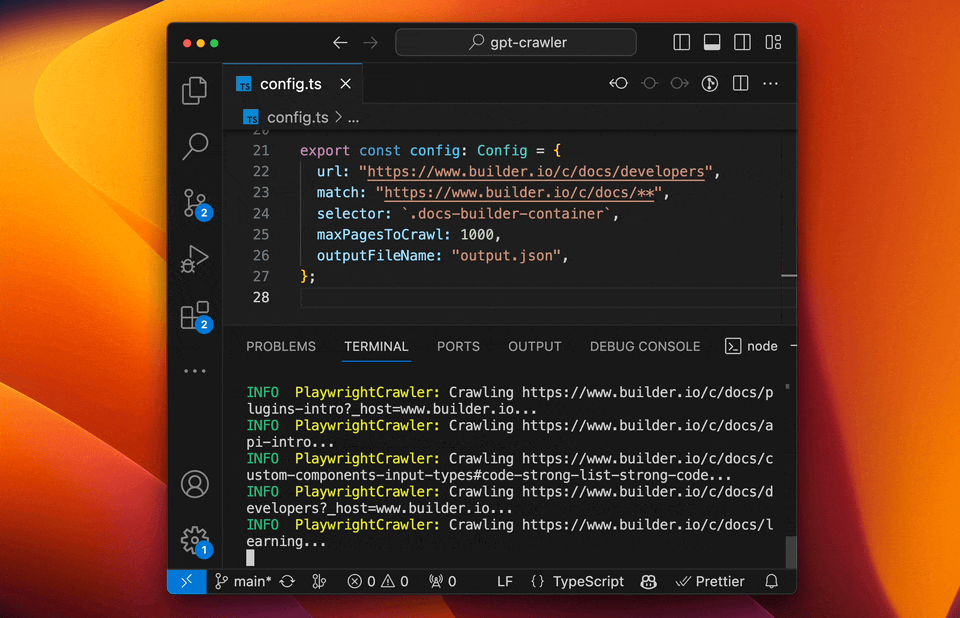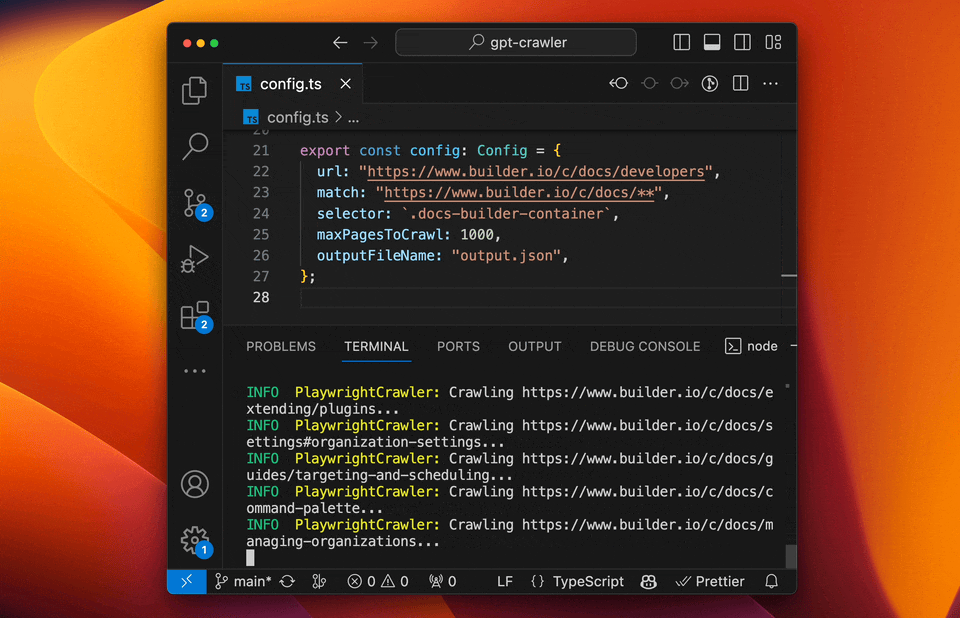
- GPT-Crawler (BuilderIO):结合GPT-3能力的爬虫工具,能够理解和处理复杂的网页结构。
- 特点:自然语言处理能力强、自动化程度高、能够理解上下文。
- 使用场景:适用于复杂结构和需要深度理解的网站。
- 实例:使用GPT-Crawler抓取技术博客,自动分类和总结内容。
- Scrapegraph-AI (VinciGit00):利用图神经网络进行数据提取,适用于结构复杂的数据集成。
- 特点:处理复杂关系型数据、能够高效整合多源数据。
- 使用场景:适用于需要从多源数据中提取关系信息的网站。
- 实例:利用Scrapegraph-AI抓取社交网络数据,分析用户关系和互动。

- MarkdownDown:专注于从网页内容生成结构化Markdown文件,便于数据整理和使用。

- 特点:生成结构化文档、易于编辑和分享。
- 使用场景:适用于需要将网页内容转化为可读文档的网站。
- 实例:用MarkdownDown抓取技术文档网站,将内容转化为Markdown文件,便于内部使用。
- Jina Reader:利用AI技术从网页中提取和总结关键信息,提升数据收集的效率和准确性。

- 特点:自动化信息提取、智能摘要生成。
- 使用场景:适用于需要快速获取和总结信息的网站。
- 实例:使用Jina Reader抓取财经新闻网站,提取并总结市场动态。
| 类别 | Scrapy | Beautiful Soup | Selenium | GPT-Crawler | Scrapegraph-AI | MarkdownDown | Jina Reader |
|---|---|---|---|---|---|---|---|
| 概念和原理 | 一个强大的Python爬虫框架,适合大规模爬取项目。 | 一个用于解析HTML和XML文档的Python库,适合小规模数据抓取。 | 一个用于自动化Web浏览的工具,能够处理动态加载的网页内容。 | 结合GPT-3能力的爬虫工具,能够理解和处理复杂的网页结构。 | 利用图神经网络进行数据提取,适用于结构复杂的数据集成。 | 专注于从网页内容生成结构化Markdown文件,便于数据整理和使用。 | 利用AI技术从网页中提取和总结关键信息,提升数据收集的效率和准确性。 |
| 优点 | 模块化设计、支持多线程、强大的抓取和处理能力。 | 易于学习和使用,快速解析和处理HTML内容。 | 支持JavaScript渲染,能够模拟用户操作。 | 自然语言处理能力强、自动化程度高、能够理解上下文。 | 处理复杂关系型数据、能够高效整合多源数据。 | 生成结构化文档、易于编辑和分享。 | 自动化信息提取、智能摘要生成。 |
| 缺点 | 需要编写大量代码,对初学者不友好。 | 处理大规模数据效率低,不支持异步操作。 | 速度慢,资源消耗大。 | 可能需要更多计算资源和前期配置。 | 技术复杂,前期学习成本高。 | 仅适用于特定格式的数据提取。 | 依赖于AI模型的准确性和性能。 |
| 适用场景 | 大规模数据抓取,如电商、新闻门户。 | 结构简单、数据量较小的网站。 | 动态内容网站,如实时数据更新的页面。 | 复杂结构和需要深度理解的网站。 | 多源数据提取和整合。 | 需要将网页内容转化为可读文档的网站。 | 快速获取和总结信息的网站。 |
| 实际案例 | 利用Scrapy抓取亚马逊商品数据,分析市场趋势。 | 使用Beautiful Soup抓取博客文章内容,用于文本分析。 | 用Selenium抓取动态加载的新闻网站,获取最新的新闻文章。 | 使用GPT-Crawler抓取技术博客,自动分类和总结内容。 | 利用Scrapegraph-AI抓取社交网络数据,分析用户关系和互动。 | 用MarkdownDown抓取技术文档网站,将内容转化为Markdown文件,便于内部使用。 | 使用Jina Reader抓取财经新闻网站,提取并总结市场动态。 |
传统爬虫工具 vs. 新型AI爬虫工具
| 类别 | 传统爬虫工具 | 新型AI爬虫工具 |
|---|---|---|
| 理解能力 | 依赖预定义规则和结构,处理复杂网页可能困难。 优势:高效处理结构简单的网页。 劣势:处理复杂或动态内容能力有限,需要手动配置。 |
利用NLP和图神经网络等技术,更好理解复杂网页结构。 优势:理解能力强,能自动调整抓取策略。 劣势:可能需更多计算资源和前期配置。 |
| 灵活性 | 需要手动编写代码处理不同类型网页,灵活性低。 优势:特定任务优化后执行效率高。 劣势:难适应新类型网站或结构变化。 |
高自适应能力,可根据网页内容自动调整抓取策略。 优势:灵活应对不同网站和内容结构。 劣势:初始设置和训练时间长。 |
| 效率 | 处理大规模数据效率高,但需大量前期配置。 优势:高效处理已知结构数据。 劣势:前期配置工作量大,难应对结构变化。 |
智能分析和自动化流程,提高数据抓取效率和准确性。 优势:自动化程度高,减少人工干预。 劣势:运行时需更多资源。 |
| 易用性 | 需编写和维护大量代码,学习曲线陡峭。 优势:技术文档和社区支持丰富。 劣势:对新手不友好,需前期配置和持续维护。 |
提供用户友好界面和自动化功能,降低使用门槛。 优势:易上手,减少编码需求。 劣势:需理解复杂AI模型和配置。 |
| 成本 | 开源工具通常免费,但需大量开发和维护资源。 优势:使用成本低。 劣势:隐性成本高(如开发时间和维护)。 |
可能需支付使用费或订阅服务,特别是商业解决方案。 优势:降低开发和维护成本。 劣势:初始投资高。 |
| 适用性 | 适用于已知结构和规则网站,特别是静态网页。 优势:高效抓取结构稳定网站。 劣势:对动态或频繁变化网站适应性差。 |
适用复杂结构和动态内容网站,自动适应和调整抓取策略。 优势:适用各种类型网站。 劣势:对简单结构网站可能过于复杂。 |
| 法律和道德 | 需手动确保遵守数据隐私法规和网站爬取规则。 优势:明确的法律边界。 劣势:需大量手动检查和调整。 |
内置合规检查和隐私保护功能,自动遵守法律和道德规范。 优势:减少法律风险和道德问题。 劣势:依赖工具合规性。 |
法律和道德考虑
1、数据隐私问题
在进行数据抓取时,数据隐私是必须要考虑的重要因素。随着全球范围内对数据隐私的重视,各国纷纷出台了相关法律法规,如欧盟的《通用数据保护条例》(GDPR)和加州的《消费者隐私法案》(CCPA)。这些法规旨在保护用户的隐私权,防止未经授权的个人数据收集和使用。
- 遵守隐私法规:在抓取数据时,必须确保遵守所在国家和地区的隐私法规。例如,避免抓取包含个人身份信息(PII)的数据,或在必要时获取用户的明确同意。
- 数据匿名化和去标识化:对抓取到的数据进行匿名化和去标识化处理,以保护用户隐私。在数据处理和存储过程中,确保任何个人信息都无法追溯到具体个人。
2、遵守robots.txt协议
robots.txt协议是一种用于告诉搜索引擎和其他爬虫哪些页面可以被抓取、哪些页面不可以被抓取的文本文件。网站管理员通过在网站根目录下放置robots.txt文件来定义爬虫访问规则。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









