







《LLM数据工程》停了半个来月,会马上恢复更新的,这两天在搞一个相关论文投稿。回想起来也接触了一段时间科研圈,发现这个领域有点过于封闭了,像是古代拜山头一样,技巧和经验只在同门内流通,感觉有点奇怪,所以尝试科普一些东西
一、arXiv id的含义是什么?
一篇文章有一个唯一id,比如:2407.04694,代表的是24年7月的编号为04694的文章
一篇文章id相关相关的链接有:https://arxiv.org/pdf/2407.04694,中间为pdf则直接是pdf页面。
https://arxiv.org/abs/2407.04694,中间为abs则是详情页
二、 arXiv每日论文在哪里查看?
可以在arxiv首页点击进入感兴趣的主题
每一个小专题的原始路径均为https://arxiv.org/list/xxx/recent,比如https://arxiv.org/list/cs.CL/recent则是cs.CL板块最近的文章
打开某个板块的首页,我们可以看到所有的文章都排列在这里,列出了基本信息:id、名字、作者等信息,而其他例如arxiv_daily、各种知乎、推特等关于arxiv论文的KOL推荐都是从这每日自动爬取的论文。

所以就此我们有了衍生的小trick:
三、如何投稿可以更好地被关注到?
基本的投稿方式可以自己搜索,这里不做赘述。
LLM时代其实会议中不中没那么重要了,因为技术和认知更迭太快,期刊动辄三五个月的时间让很多在科研前沿的人士很大程度上放弃了投稿,期刊就更不用说了,一年的时间过去黄花菜都凉了。
而与此同时arXiv的优势就显示出来了,最快一天就可以见于互联网,方便想快速PR成果的个人和团队,所以很多人都是arXiv战神——成果只挂arXiv,有时间再说投稿的事(比如我)
而arXiv火热的专题每天会有几百甚至上千份投稿,如何才能让自己的稿件脱颖而出?
1. 自荐给KOL
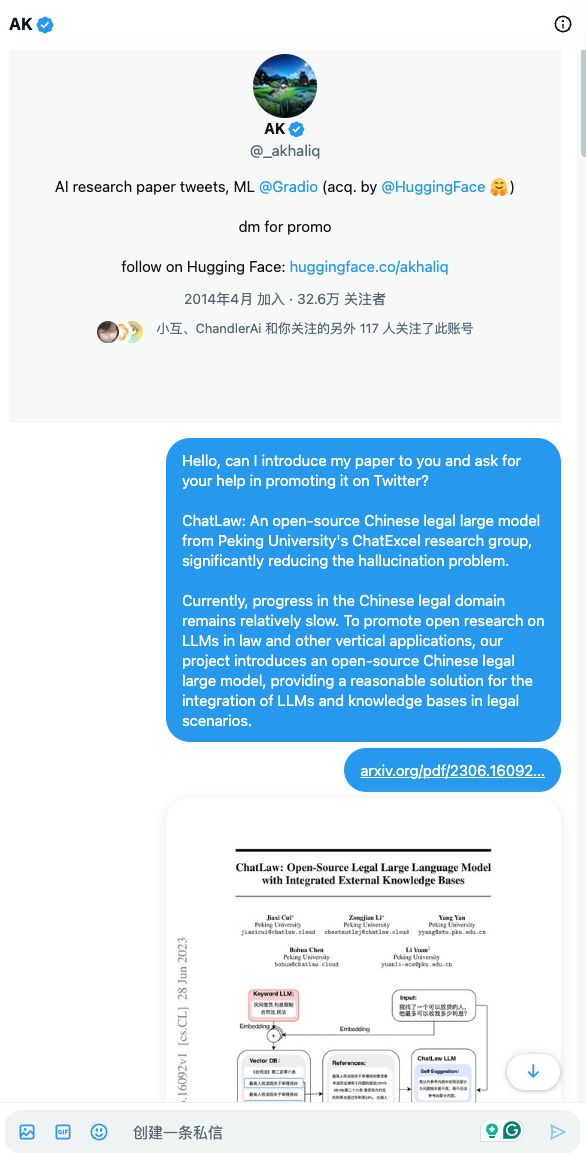
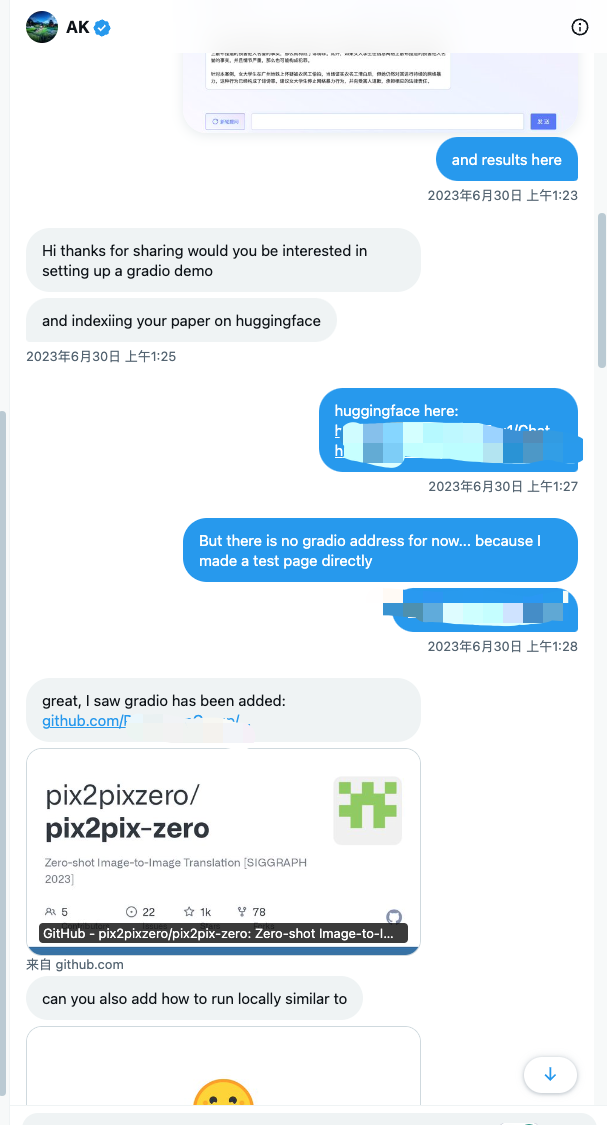
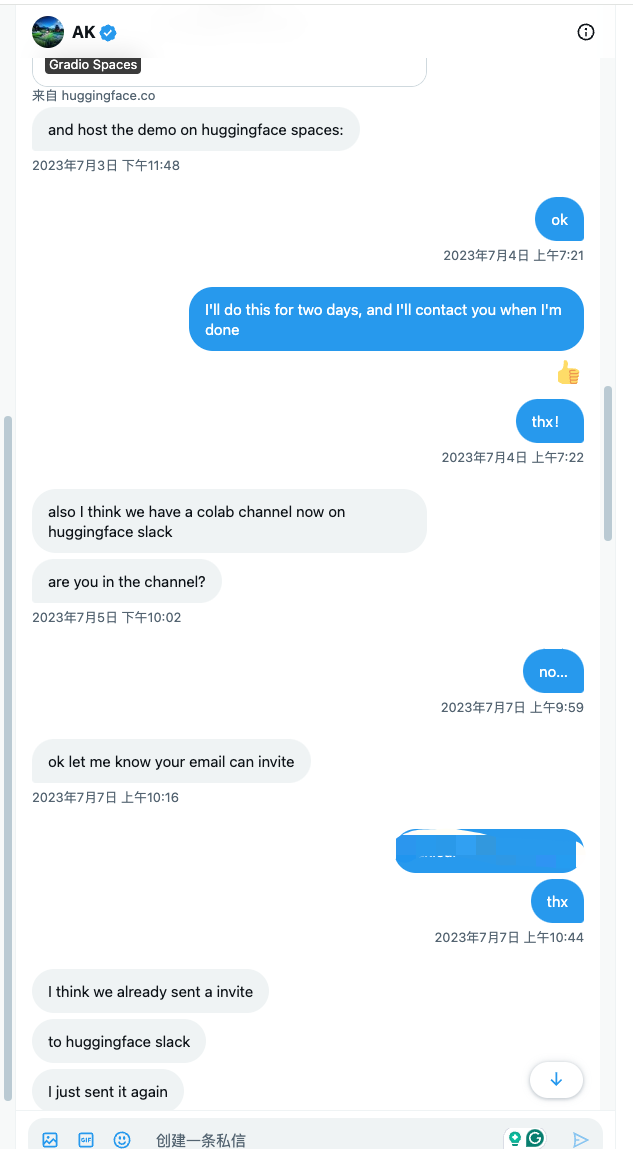
挑选各个平台流量高的kol,将自己刚release的arXiv地址,GitHub地址,最好有demo演示地址、视频等方便外行人可以快速了解你做了什么的东西发给对方,看对方是否愿意帮你做宣传,不需要过度紧张,被拒绝是常事,被接收是幸运。但也要注意基本的社交礼仪,附我早期和他们的交流话术:
有了一次成功经历之后,之后再有其他工作想麻烦他们宣传就很简单了,比如:
2. 自己慢慢做账号
我们会发现很多KOL刚开始对前沿的东西也是一知半解,但是流量高,可以帮助自己起粉丝,所以我们其实可以慢慢培育自己的账号,有几千粉丝之后自己就逐渐变为小KOL了。
而且亲测起号速度也没那么慢
3. arXiv系统排序规则
这条是比较实用的小技巧,首先有一个小认知,和学术界工业界都打过交道的人会发现一个事情:像arXiv这种学术系统一般不会有复杂的工程设计,意思就是他的各种规则和功能一定很简单,根本不会有什么高并发、分布式、雪花算法、容器等东西。
而list页面最上面的文章总是更容易被各个kol和爬虫获取到的,那么问题就变为了:如何让我们的文章尽量排到最上面?
我们观察页面,可以发现一个简单的规律:arXiv的文章展示结果是把arXiv id最大的放在最上面
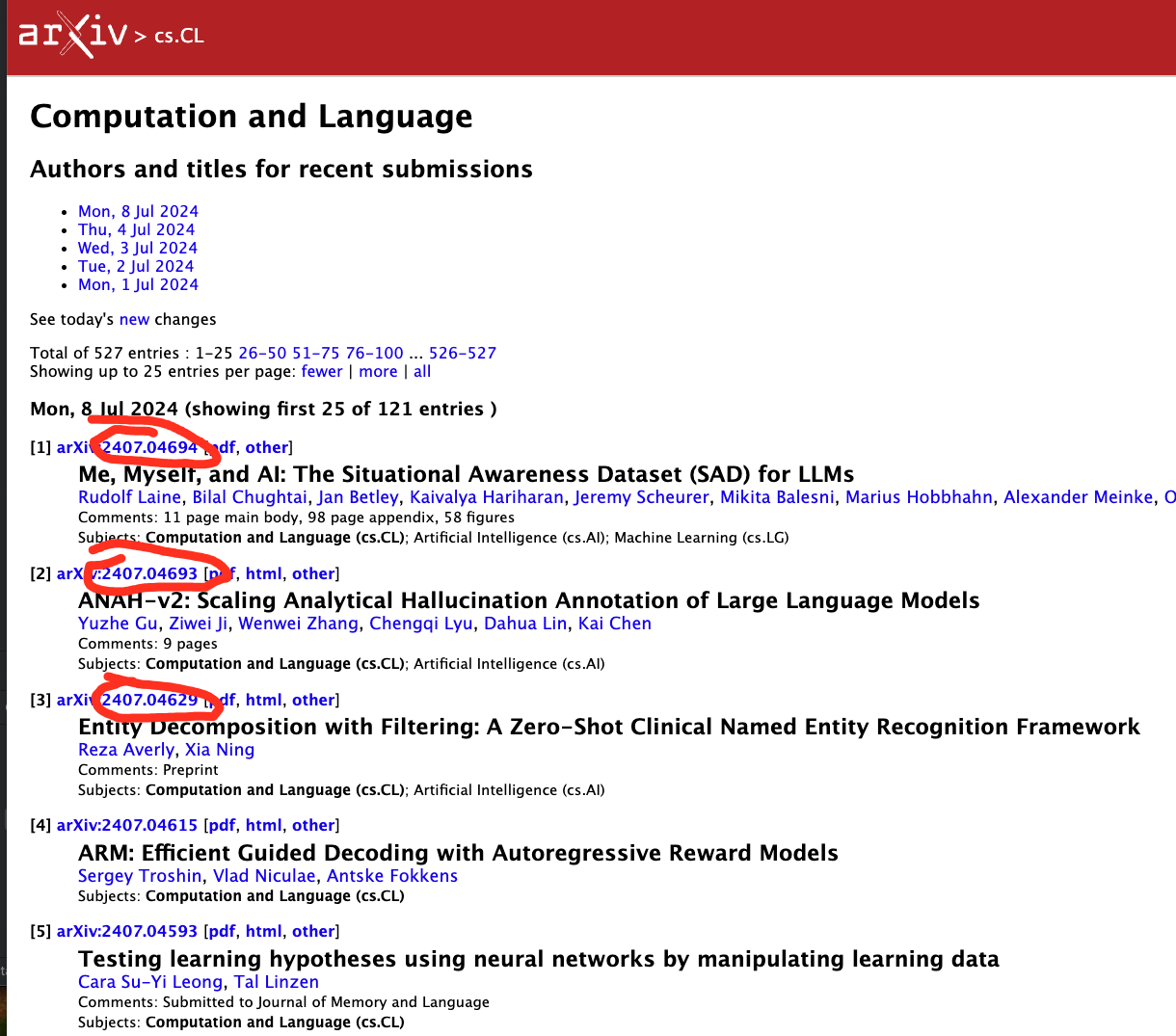
所以问题变为了:如何让我们的arXiv id在每次更新的所有id中,尽可能地大?
4. arXiv卡点提交
通过研究它的所有文档,我发现了这么一个页面:https://info.arxiv.org/help/availability.html
里面详细列出了arXiv每期的截稿时间和更新时间
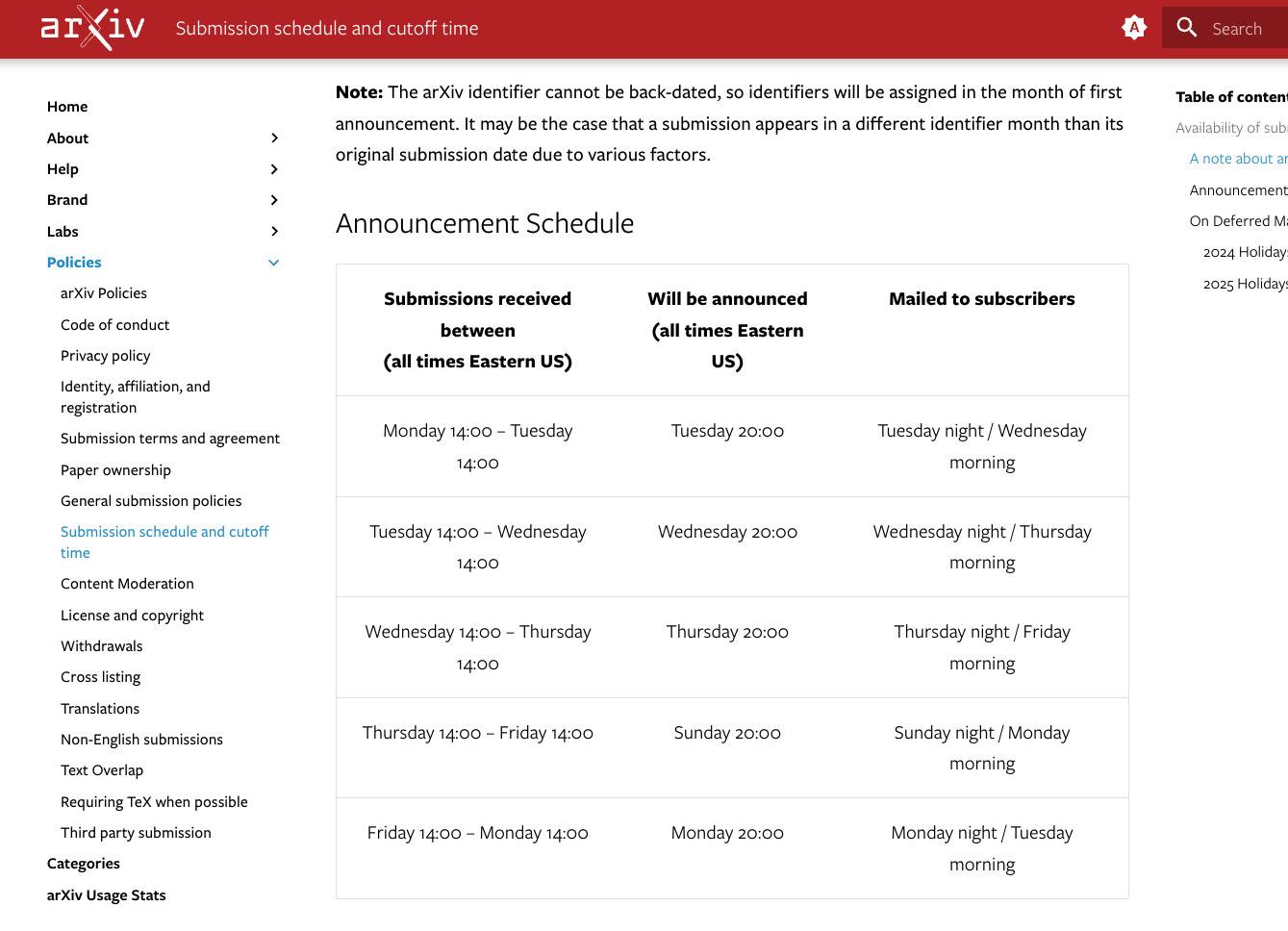
也就是周日一二三四的晚上八点会更新之前一次时间截止到当天时间下午两点的论文
而简单建立多个提交请求之后,我们可以发现arXiv是自增id的逻辑,也就是系统每有一个新提交request,就id+1,那么答案自然就来了:尽量在截稿时间前几秒提交,也就是比如周二下午两点截稿,可以卡在13:59:59提交,这样理论上当前周期的id就会最大,文章自然在最前列。(不过建议不要这么极限)
当然,以上时间是美东时间,我们需要把美东时间时间换算为北京时间或你当地的时间,同时要注意美国从3月的第二个星期日开始,到11月的第一个星期日结束是夏令时,其他为冬令时。夏令时和北京时间相差12小时,而冬令时比北京时间晚13小时
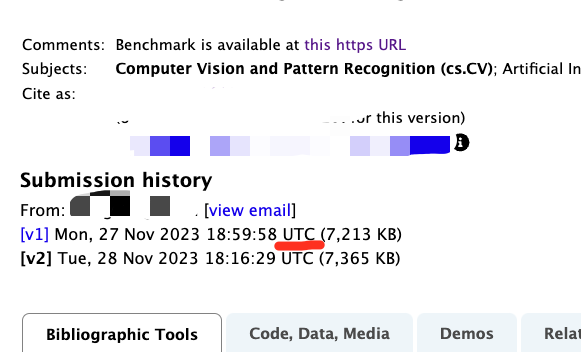
PS:arxiv提交之后显示的是UTC时间,可以自己做一下换算
祝大家万事顺意~

















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









