









Datawhale组队学习第27期:集成学习
本次学习的指导老师萌弟
本贴为学习记录帖,有任何问题欢迎随时交流~
部分内容可能还不完整,后期随着知识积累逐步完善。
开始时间:2021年7月29日
最新更新:2021年8月1日(Task8 案例二)
案例二:蒸汽量预测
一、数据来源
- 天池新人实战赛:工业蒸汽量预测
- 从火力发电的基本原理入手,考虑影响锅炉生成蒸汽的效率。
- 数据内容:经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别)
- 赛题任务:根据锅炉的工况,预测产生的蒸汽量。
二、数据信息
- 数据分成训练数据(train.txt)和测试数据(test.txt)
V0到V37总共38个字段是特征变量,target作为目标变量(蒸汽量)。
三、评价指标
- 预测结果以mean square error作为评判标准。
S c o r e = 1 n ∑ i = 1 n ( y i − y ∗ ) 2 Score = \frac{1}{n}\sum\limits_{i=1}^{n}(y_i - y^{*})^2 Score=n1i=1∑n(yi−y∗)2
四、数据读取
- 导入
numpy和pandas包,用于读入数据和展示数据表
import pandas as pd
import numpy as np
data_train = pd.read_csv('train.txt',sep = '\t')
data_test = pd.read_csv('test.txt',sep = '\t')
#合并训练数据和测试数据
data_train["oringin"]="train"
data_test["oringin"]="test"
data_all=pd.concat([data_train,data_test],axis=0,ignore_index=True)
#显示前5条数据
data_all.head()
五、探索数据分布
1. 核密度估计
- 利用核密度估计对数据进行初步分析
- **核密度估计(kernel density estimation)**是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
- 使用
seaborn.kdeplot和matplotlib.pyplot的包进行核密度估计。 - 将训练集数据分布和测试集数据不一致的特征进行删除
import matplotlib.pyplot as plt
import seaborn as sns
for column in ["V5","V9","V11","V17","V22","V28"]:
g = sns.kdeplot(data_all[column][(data_all["oringin"] == "train")], color="Red", shade = True)
g = sns.kdeplot(data_all[column][(data_all["oringin"] == "test")], ax =g, color="Blue", shade= True)
g.set_xlabel(column)
g.set_ylabel("Frequency")
g = g.legend(["train","test"])
plt.show()
data_all.drop(["V5","V9","V11","V17","V22","V28"],axis=1,inplace=True)
2. 相关系数矩阵
-
Spearman相关系数:斯皮尔曼相关系数表明X(独立变量)和Y(依赖变量)的相关方向。如果当X增加时,Y趋向于增加,斯皮尔曼相关系数则为正。如果当X增加时,Y趋向于减少,斯皮尔曼相关系数则为负。斯皮尔曼相关系数为零表明当X增加时Y没有任何趋向性。
-
使用
seaborn.heatmap和ndarray.corr(method="spearman")构建相关系数矩阵及其可视化图像 -
显然,我们主要关注的是与目标变量
target关系紧密的一列,因此将相关性较低的特征去掉。
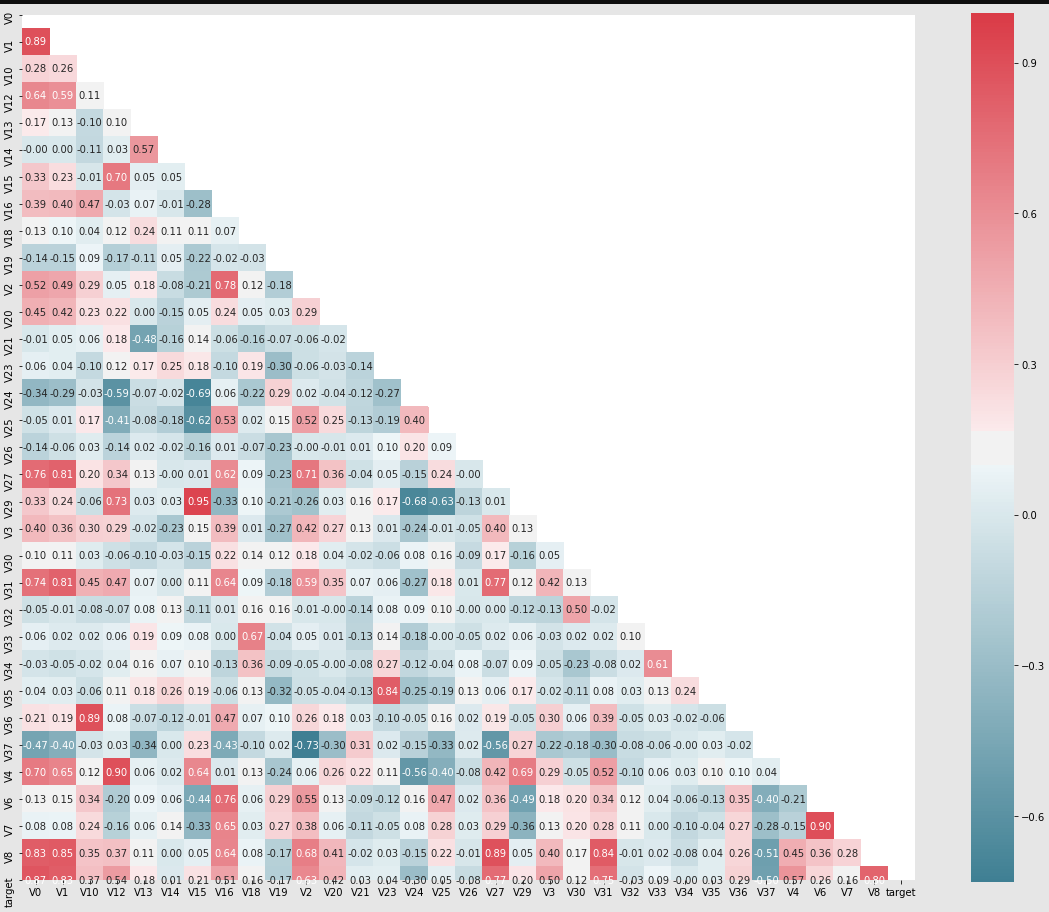
threshold = 0.1
corr_matrix = data_train1.corr().abs()
drop_col=corr_matrix[corr_matrix["target"]<threshold].index
data_all.drop(drop_col,axis=1,inplace=True)
六、特征工程
1. 归一化处理
-
对特征变量进行归一化处理
cols_numeric=list(data_all.columns) cols_numeric.remove("oringin") def scale_minmax(col): return (col-col.min())/(col.max()-col.min()) scale_cols = [col for col in cols_numeric if col!='target'] data_all[scale_cols] = data_all[scale_cols].apply(scale_minmax,axis=0) data_all[scale_cols].describe()
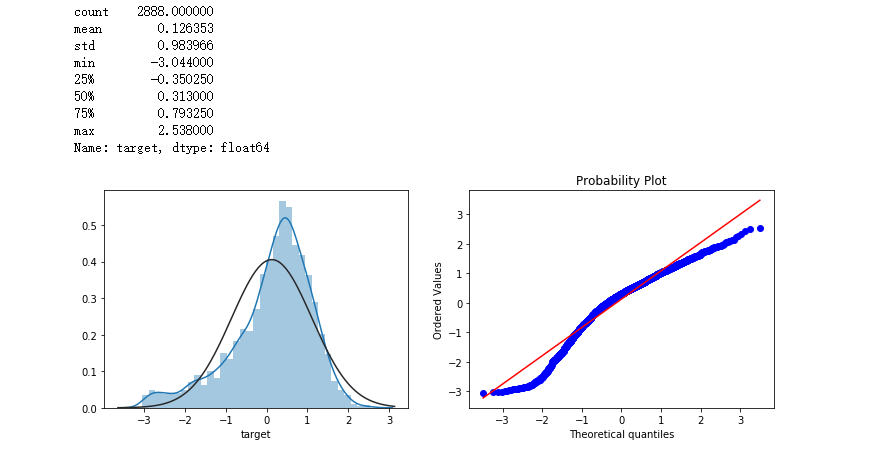
2. Box-Cox变换
-
Box-Cox用于连续的响应变量不满足正态分布的情况。在进行Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。
-
简单来说就是,对于一组原有的数据是不满足正态分布的,但可以经过某种变换(如取对数、取平方等)会满足正态分布。
-
实现方式
# 进行Box-Cox变换 cols_transform=data_all.columns[0:-2] for col in cols_transform: # transform column data_all.loc[:,col], _ = stats.boxcox(data_all.loc[:,col]+1) print(data_all.target.describe()) plt.figure(figsize=(12,4)) plt.subplot(1,2,1) sns.distplot(data_all.target.dropna() , fit=stats.norm); plt.subplot(1,2,2) _=stats.probplot(data_all.target.dropna(), plot=plt)
七、模型构建
1. 构建训练集、验证集和测试集
-
训练集和验证集
def get_training_data(): # extract training samples from sklearn.model_selection import train_test_split df_train = data_all[data_all["oringin"]=="train"] df_train["label"]=data_train.target1 # split SalePrice and features y = df_train.target X = df_train.drop(["oringin","target","label"],axis=1) X_train,X_valid,y_train,y_valid=train_test_split(X,y, test_size=0.3,random_state=100) return X_train,X_valid,y_train,y_valid -
测试集(没有标签,模型融合会用上)
def get_test_data(): df_test = data_all[data_all["oringin"]=="test"].reset_index(drop=True) return df_test.drop(["oringin","target"],axis=1)
2. 构建评价指标
-
RMSE和MSE,采用自定义的方式
from sklearn.metrics import make_scorer # metric for evaluation def rmse(y_true, y_pred): diff = y_pred - y_true sum_sq = sum(diff**2) n = len(y_pred) return np.sqrt(sum_sq/n) def mse(y_ture,y_pred): return mean_squared_error(y_ture,y_pred) # scorer to be used in sklearn model fitting rmse_scorer = make_scorer(rmse, greater_is_better=False) #输入的score_func为记分函数时,该值为True(默认值);输入函数为损失函数时,该值为False mse_scorer = make_scorer(mse, greater_is_better=False)
3. 离群点处理
-
将z值的绝对值大于某个值的点视为离群点
def find_outliers(model, X, y, sigma=3): # 使用模型得到预测值 model.fit(X,y) y_pred = pd.Series(model.predict(X), index=y.index) # 计算残差的均值和标准差 resid = y - y_pred mean_resid = resid.mean() std_resid = resid.std() # 计算z值,当z值的绝对值比给定的sigma大时,则认为是离群点 z = (resid - mean_resid)/std_resid outliers = z[abs(z)>sigma].index # 返回离群点的下标 return outliers # 采用岭回归模型,将离群点删去 outliers = find_outliers(Ridge(), X_train, y_train) X_outliers=X_train.loc[outliers] y_outliers=y_train.loc[outliers] X_t=X_train.drop(outliers) y_t=y_train.drop(outliers)
八、模型训练
1. 模型训练的设计思路
-
训练模型的思路过程(方便重复使用):
- 获取数据(x和y的样本量要相等)
- 设定需要使用的模型
- 设定交叉验证的分割比例(或数量)和重复数(份数)
- 网格搜索
GridSearchCV()获取最优超参数、验证指标(验证均值和标准差) - 定义残差,可视化展示残差图
2. 代码实现
-
训练模型过程的实现
def train_model(model, param_grid=[], X=[], y=[], splits=5, repeats=5): # 获取数据 if len(y)==0: X,y = get_trainning_data_omitoutliers() # 交叉验证 rkfold = RepeatedKFold(n_splits=splits, n_repeats=repeats) # 网格搜索最佳参数 if len(param_grid)>0: gsearch = GridSearchCV(model, param_grid, cv=rkfold, scoring="neg_mean_squared_error", verbose=1, return_train_score=True) # 训练 gsearch.fit(X,y) # 最好的模型 model = gsearch.best_estimator_ best_idx = gsearch.best_index_ # 获取交叉验证评价指标 grid_results = pd.DataFrame(gsearch.cv_results_) cv_mean = abs(grid_results.loc[best_idx,'mean_test_score']) cv_std = grid_results.loc[best_idx,'std_test_score'] # 没有网格搜索 else: grid_results = [] cv_results = cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=rkfold) cv_mean = abs(np.mean(cv_results)) cv_std = np.std(cv_results) # 合并数据 cv_score = pd.Series({'mean':cv_mean,'std':cv_std}) # 预测 y_pred = model.predict(X) # 残差分析(返回值可用于可视化残差) y_pred = pd.Series(y_pred,index=y.index) resid = y - y_pred mean_resid = resid.mean() std_resid = resid.std() z = (resid - mean_resid)/std_resid n_outliers = sum(abs(z)>3) outliers = z[abs(z)>3].index return model, cv_score, grid_results















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









