






每种动物都有自己的语言,机器也是!自然语言处理(NLP)就是在机器语言和人类语言之间沟通的桥梁。
NLP通常有情感分析、文本挖掘、信息抽取、信息检索、问答/对话系统(聊天机器人)、语音识别、机器翻译等应用。
最近大火的ChatGPT(Chat Generative Pre-trained Transformer)则是人工智能研究实验室OpenAI新推出的人工智能技术驱动的自然语言处理工具。主要通过使用TransFormer神经网络架构使得ChatGPT具有聊天互动的能力,可以根据特定聊天场景进行交流,还具备撰写邮件、脚本、文案、翻译、代码等不同类型文字的功能。
最近几篇推文我将从Word2Vec→Transformer→BERT出发,从简单到复杂尝试NLP的一些工作。
(BERT与GPT的模型简介可以参考这篇文章:http://t.csdn.cn/c8ZVD)

ChatGPT问答对话系统(图源:自截)
本篇推文为Word2Vec的实现
1.什么是词向量
在自然语言处理任务中,首先需要考虑词如何在计算机中表示,通常有两种表示方式[1]。
1.离散表示(one-hot representation)
1.1 将每个词表示为一个长向量(维度为词表大小),向量中只有一个维度的值为1,其余为0。
例如:
建筑 [0, 0, 0, 0, 1, 0, 0, ……]
景观 [0, 0, 0, 1, 0, 0, 0, ……]
语料库中的每个词都有一个索引,但以这种方式表示,词与词之间无任何关系,同时当词数比较多时,会导致特征空间十分大;
1.2 Bag of Words 表示
将每个单词在语料库中出现的次数加到one-hot编码中,此方法仍未考虑单词的顺序及语义信息。
2.分布式表示(distribution representation)
将词通过词嵌入(word embedding)转换为一种分布式表示,即词向量。
比如我们将词汇表里的词用"Royalty",“Masculinity”, "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是[0.99,0.99,0.05,0.7]。大致可以理解为国王为具有王权的男性,这样就从原来非常稀疏的one hot产生的词向量转变成了现在的稠密向量,大大节约了内存和减少了计算量。
在实际情况中,我们需要自定词向量的维度[2]。
以GloVe词向量为例,glove.6B.50d.txt中,每个词有50维:
of: 0.70853 0.57088 -0.4716 0.18048 0.54449 0.72603 0.18157 -0.52393 0.10381 -0.17566 0.078852 -0.36216 -0.11829 -0.83336 0.11917 -0.16605 0.061555 -0.012719 -0.56623 0.013616 0.22851 -0.14396 -0.067549 -0.38157 -0.23698 -1.7037 -0.86692 -0.26704 -0.2589 0.1767 3.8676 -0.1613 -0.13273 -0.68881 0.18444 0.0052464 -0.33874 -0.078956 0.24185 0.36576 -0.34727 0.28483 0.075693 -0.062178 -0.38988 0.22902 -0.21617 -0.22562 -0.093918 -0.80375
glove.6B.100d.txt中,每个词有100维:
of: -0.1529 -0.24279 0.89837 0.16996 0.53516 0.48784 -0.58826 -0.17982 -1.3581 0.42541 0.15377 0.24215 0.13474 0.41193 0.67043 -0.56418 0.42985 -0.012183 -0.11677 0.31781 0.054177 -0.054273 0.35516 -0.30241 0.31434 -0.33846 0.71715 -0.26855 -0.15837 -0.47467 0.051581 -0.33252 0.15003 -0.1299 -0.54617 -0.37843 0.64261 0.82187 -0.080006 0.078479 -0.96976 -0.57741 0.56491 -0.39873 -0.057099 0.19743 0.065706 -0.48092 -0.20125 -0.40834 0.39456 -0.02642 -0.11838 1.012 -0.53171 -2.7474 -0.042981 -0.74849 1.7574 0.59085 0.04885 0.78267 0.38497 0.42097 0.67882 0.10337 0.6328 -0.026595 0.58647 -0.44332 0.33057 -0.12022 -0.55645 0.073611 0.20915 0.43395 -0.012761 0.089874 -1.7991 0.084808 0.77112 0.63105 -0.90685 0.60326 -1.7515 0.18596 -0.50687 -0.70203 0.66578 -0.81304 0.18712 -0.018488 -0.26757 0.727 -0.59363 -0.34839 -0.56094 -0.591 1.0039 0.20664
有了用Distributed Representation表示的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:


图1 有趣的词向量(图源:CSDN 前行的zhu)
2.词向量的表示
Word2Vec文章介绍了两个词向量模型:连续词袋模型(Continuous Bag-of-Words,简称CBOW) 与和跳字模型(Skip-Gram)。对于在语义上有意义的表示,它们的训练依赖于条件概率,条件概率可以被看作是使用语料库中⼀些词来预测另⼀些单词。由于是不带标签的数据,因此跳元模型和连续词袋都是自监督模型。

对二者的讲解资料十分多,详细了解推荐在此查看:http://t.csdn.cn/zkciu
3.Word2Vec的代码实现
我们使用Penn Tree Bank(PTB)数据集进行实验,该语料库取⾃“华尔街⽇报”的文章,分为训练集、验证集和测试集。
3.1 文本预处理
%matplotlib inline
import math
import os
import random
import torch
from d2l import torch as d2l
import collections
from torch import nn将文本作为字符串加载到内存中并将字符串拆分为词元(如单词和字符)
d2l.DATA_HUB['ptb'] = (d2l.DATA_URL + 'ptb.zip','319d85e578af0cdc590547f26231e4e31cdf1e42')
def read_ptb():
"""将PTB数据集加载到文本行的列表中"""
data_dir = d2l.download_extract('ptb')
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split('\n')] #进行分词操作
def count_corpus(tokens):
if len(tokens)==0 or isinstance(tokens[0],list):
tokens=[token for line in tokens for token in line]
print(tokens)
return collections.Counter(tokens)构建词表,其中出现次数少于10次的任何单词都将由“<unk>”词元替换。
class Vocab:
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens=[]
if reserved_tokens is None:
reserved_tokens=[]
counter=count_corpus(tokens)
self._token_freqs=sorted(counter.items(), key=lambda x: x[1], reverse=True)
self.idx_to_token=['<unk>']+reserved_tokens
self.token_to_idx={token:idx for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq<min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token]=len(self.idx_to_token)-1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self,tokens):
if not isinstance(tokens,(list,tuple)):
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self,indices):
if not isinstance(indices,(list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def unk(self):
return 0
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens):
if len(tokens)==0 or isinstance(tokens[0],list):
tokens=[token for line in tokens for token in line]
return collections.Counter(tokens)
sentences = read_ptb()
vocab=Vocab(sentences,min_freq=10)
subsampled, counter=subsample(sentences,vocab)下采样,将高频词wi“a”、“the”、“of”等进行丢弃,其被丢弃的概率为:
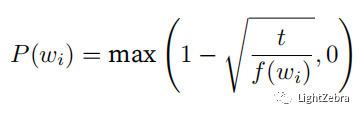
def subsample(sentences,vocab):
sentences=[[token for token in line if vocab[token]!=vocab.unk] for line in sentences]
counter=count_corpus(sentences)
# print(counter)
num_tokens=sum(counter.values())
# print(num_tokens)
def keep(token):
return(random.uniform(0,1)<math.sqrt(1e-4/counter[token]*num_tokens))
return([[token for token in line if keep(token)] for line in sentences],counter)提取中心词和上下文词,随机采样1到max_window_size之间的整数作为上下⽂窗⼝。对于任⼀中⼼词,与其距离不超过采样上下⽂窗⼝⼤⼩的词为其上下⽂词。
def get_centers_and_contexts(corpus, max_window_size):
centers,contexts=[],[]
for line in corpus:
# print(line)
if len(line)<2:
continue
centers+=line
for i in range(len(line)):
window_size=random.randint(1,max_window_size)
indices=list(range(max(0,i-window_size),min(len(line),i+1+window_size)))
indices.remove(i)
contexts.append([line[idx] for idx in indices])
return centers,contexts整合代码:读取PTB数据集并返回数据迭代器和词表。
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):
"""下载PTB数据集,然后将其加载到内存中"""
num_workers = d2l.get_dataloader_workers()
sentences = read_ptb()
vocab = Vocab(sentences, min_freq=10)
subsampled, counter = subsample(sentences, vocab)
corpus = [vocab[line] for line in subsampled]
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
all_negatives = get_negatives(
all_contexts, vocab, counter, num_noise_words)
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
data_iter = torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True,
collate_fn=batchify, num_workers=num_workers)
return data_iter, vocab3.2 预训练word2vec
在前向传播中,跳元语法模型的输入包括形状为(批量大小,1)的中心词索引center和形状为(批量大小,max_len)的上下文与噪声词索引contexts_and_negatives。这两个变量首先通过嵌入层从词元索引转换成向量,然后它们的批量矩阵相乘返回形状为(批量大小,1,max_len)的输出。输出中的每个元素是中心词向量和上下文或噪声词向量的点积。
def skip_gram(center,contexts_and_negtives,embed_v,embed_u):
v=embed_v(center)
u=embed_u(contexts_and_negtives)
pred=torch.bmm(v,u.permute(0,2,1))
return pred计算⼆元交叉熵损失
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduction="none")
return out.mean(dim=1)
loss = SigmoidBCELoss()初始化模型参数
data_iter,vocab=d2l.load_data_ptb(512,5,5)
embed_size=100
net=nn.Sequential(nn.Embedding(num_embeddings=len(vocab),embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),embedding_dim=embed_size))定义训练阶段代码
def train(net,data_iter,lr,num_epochs,device=d2l.try_gpu()):
def init_weights(m):
if type(m)==nn.Embedding:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net=net.to(device)
optimizer=torch.optim.Adam(net.parameters(),lr=lr)
animator=d2l.Animator(xlabel='epoch',ylabel='loss',xlim=[1,num_epochs])
metric=d2l.Accumulator(2)
for epoch in range(num_epochs):
timer,num_batches=d2l.Timer(),len(data_iter)
for i, batch in enumerate(data_iter):
optimizer.zero_grad()
center,context_negative,mask,label=[data.to(device) for data in batch]
pred=skip_gram(center,context_negative,net[0],net[1])
l=(loss(pred.reshape(label.shape).float(),label.float(),mask)/mask.sum(axis=1)*mask.shape[1])
l.sum().backward()
optimizer.step()
metric.add(l.sum(),l.numel())
if (i+1)%(num_batches//5)==0 or i==num_batches-1:
animator.add(epoch+(i+1)/num_batches,(metric[0]/metric[1]))
print(f'loss{metric[0]/metric[1]:.3f},'
f'{metric[1]/timer.stop():.1f} tokens/sec on {str(device)}')开始训练
lr,num_epochs=0.002,100
train(net,data_iter,lr,num_epochs)实验结果如下图
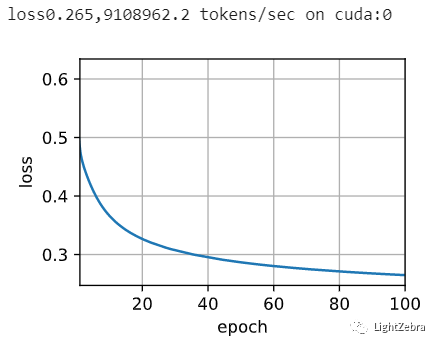
3.3 应用词嵌入
使⽤训练好模型中词向量的余弦相似度来从词表中找到与输⼊单词语义最相似的单词,十分神奇!
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data
x = W[vocab[query_token]]
# 计算余弦相似性。增加1e-9以获得数值稳定性
cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) *
torch.sum(x * x) + 1e-9)
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')
for i in topk[1:]: # 删除输入词
print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')
get_similar_tokens('tour', 3, net[0])例如,我们查找与“chip”相近的词,余弦相似度最高的前三个词为:
cosine sim=0.386: machine
cosine sim=0.383: computer
cosine sim=0.371: equipment
与“university”相近的词,余弦相似度最高的前三个词为:
cosine sim=0.460: graduate
cosine sim=0.408: school
cosine sim=0.440: professor
与“money”相近的词,余弦相似度最高的前三个词为:
cosine sim=0.454: funds
cosine sim=0.408: rely
cosine sim=0.406: investors
·未完待续·
本文的学习基于李沐老师的《动手学深度学习》:















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









