







匹配多个字符
| 代码 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 【至少出现m次,最多出现n次】【{m,} 省略n,匹配前一个字符中至少出现m次】【注意:,和n之间不能有空格,否则返回结果None】 |
示例1:*
需求:匹配出一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可 有可无
import re
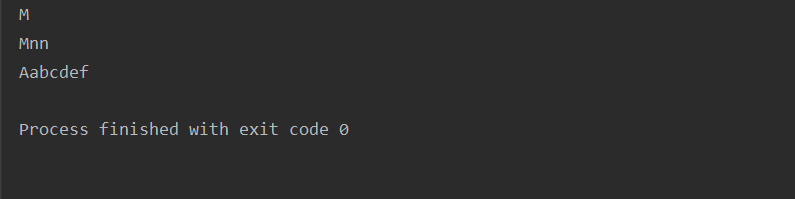
ret = re.match("[A-Z][a-z]*","M")
print(ret.group())
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
运行结果:
示例2:+
需求:匹配一个字符串,第一个字符是t,最后一个字符串是o,中间至少有一个字符
import re
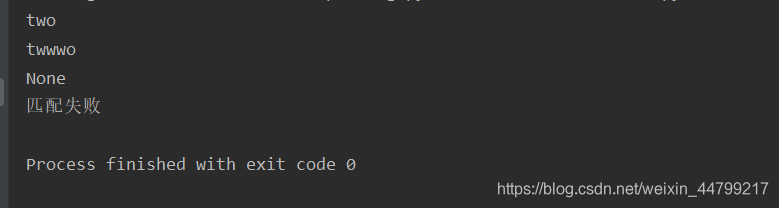
match_obj = re.match("t.+o", "two")
if match_obj:
print(match_obj.group())
else:
print("匹配失败")
match_obj2 = re.match("t.+o", "twwwo")
if match_obj2:
print(match_obj2.group())
else:
print("匹配失败")
match_obj3 = re.match("t.+o", "to")
print(match_obj3)
if match_obj3:
print(match_obj3.group()) # 这种情况会报错
else:
print("匹配失败")
运行结果:
示例3:?
需求:匹配出这样的数据,但是https 这个s可能有,也可能是http 这个s没有
import re
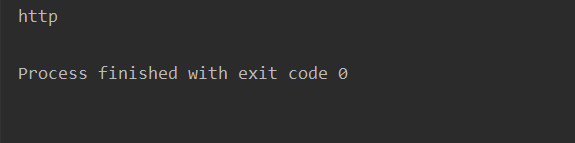
match_obj = re.match("https?", "http")
if match_obj:
print(match_obj.group())
else:
print("匹配失败")
运行结果:
示例4:{m}、{m,n}
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
import re
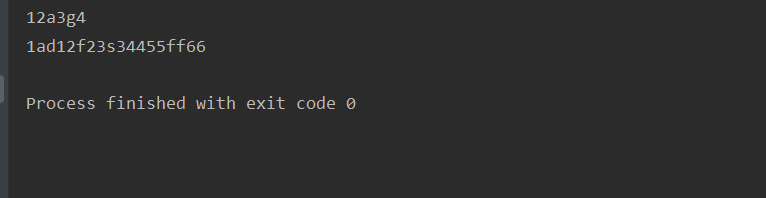
ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
print(ret.group())
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
运行结果:
注意: 上述{m}中m后面不可以有空格,{m,n}中,和n之间不可以有空格!

















 3443
3443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









