







和MySQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
size: 结果数,默认10
from: 跳过开始的结果数,默认0如果想每页显示5个结果,页码从1到3,那请求如下:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10注意:应该多注意分页太深或者一次请求太多的结果。结果在返回前会被排序。但是记住一个搜索请求常常涉及多个分片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
当前数据库中的数据如下:
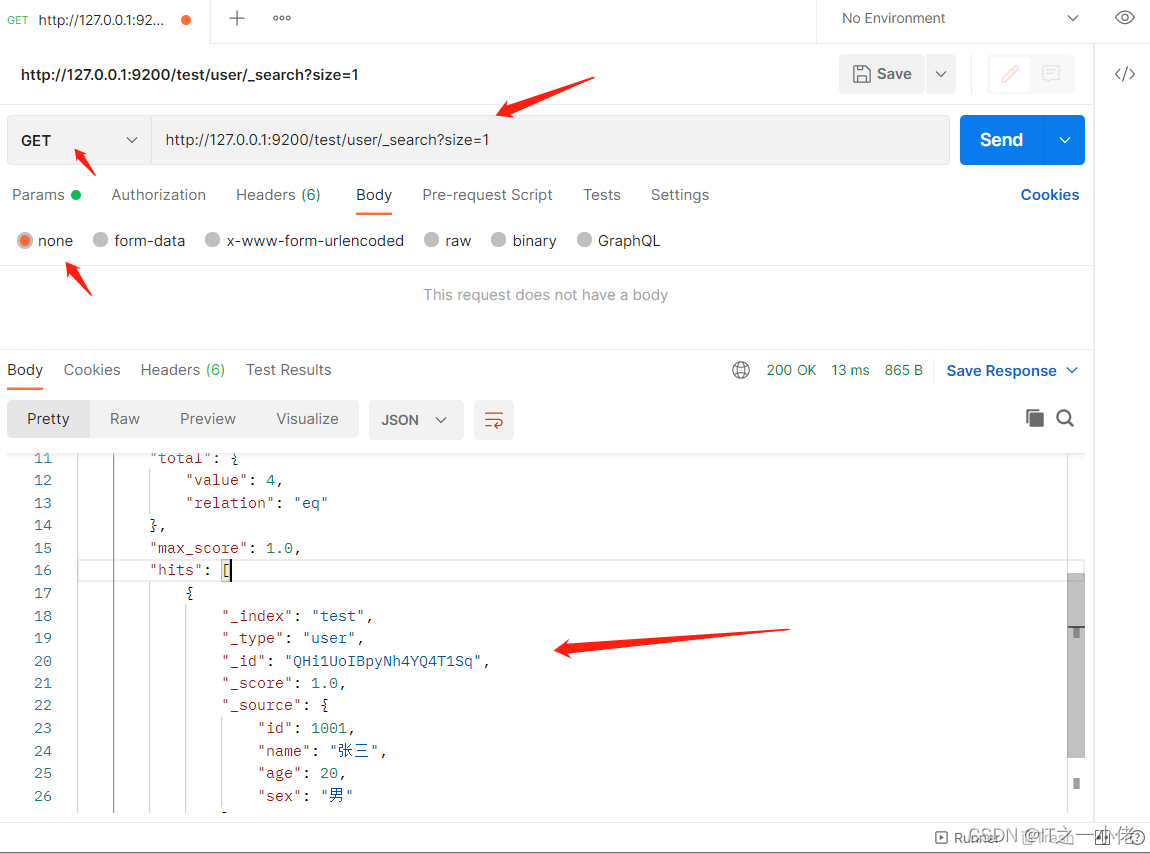
GET http://127.0.0.1:9200/test/user/_search?size=1
#响应结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "user",
"_id": "QHi1UoIBpyNh4YQ4T1Sq",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "张三",
"age": 20,
"sex": "男"
}
}
]
}
}
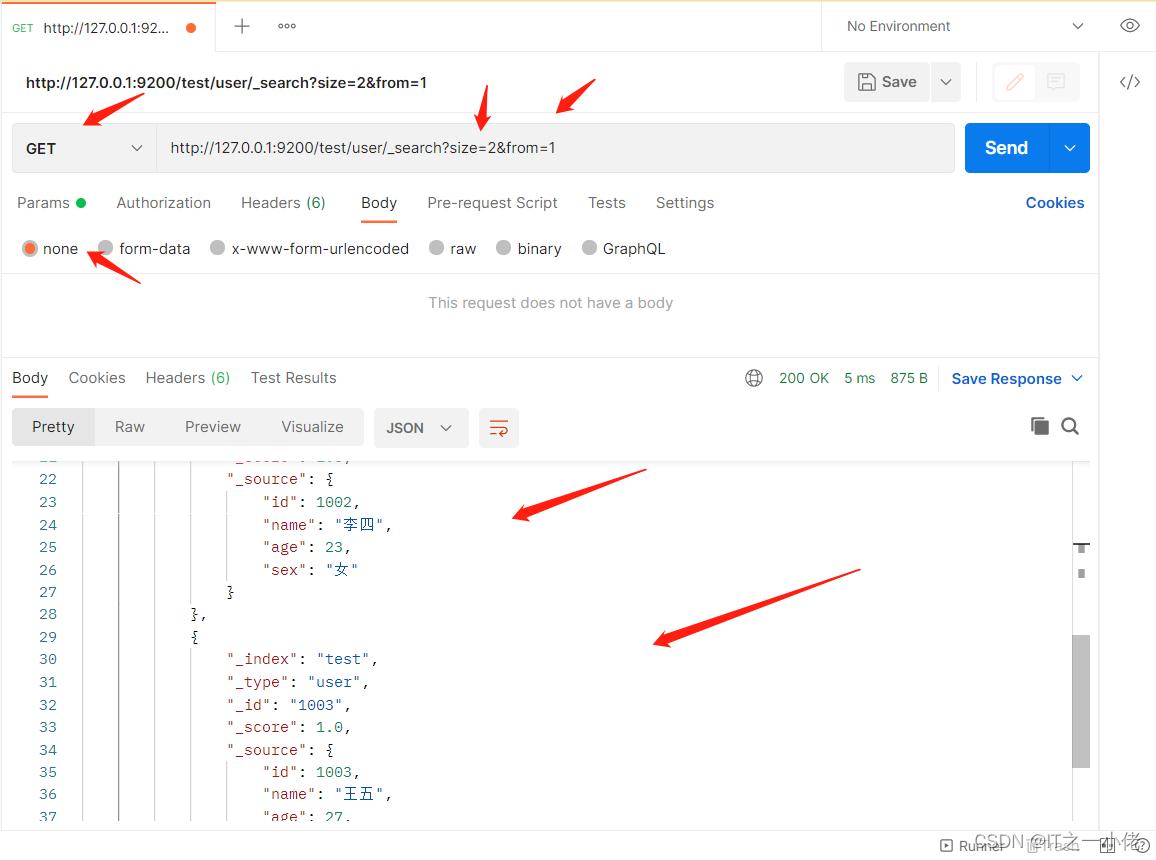
GET http://127.0.0.1:9200/test/user/_search?size=2&from=1
# 响应数据
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "user",
"_id": "1002",
"_score": 1.0,
"_source": {
"id": 1002,
"name": "李四",
"age": 23,
"sex": "女"
}
},
{
"_index": "test",
"_type": "user",
"_id": "1003",
"_score": 1.0,
"_source": {
"id": 1003,
"name": "王五",
"age": 27,
"sex": "男"
}
}
]
}
}
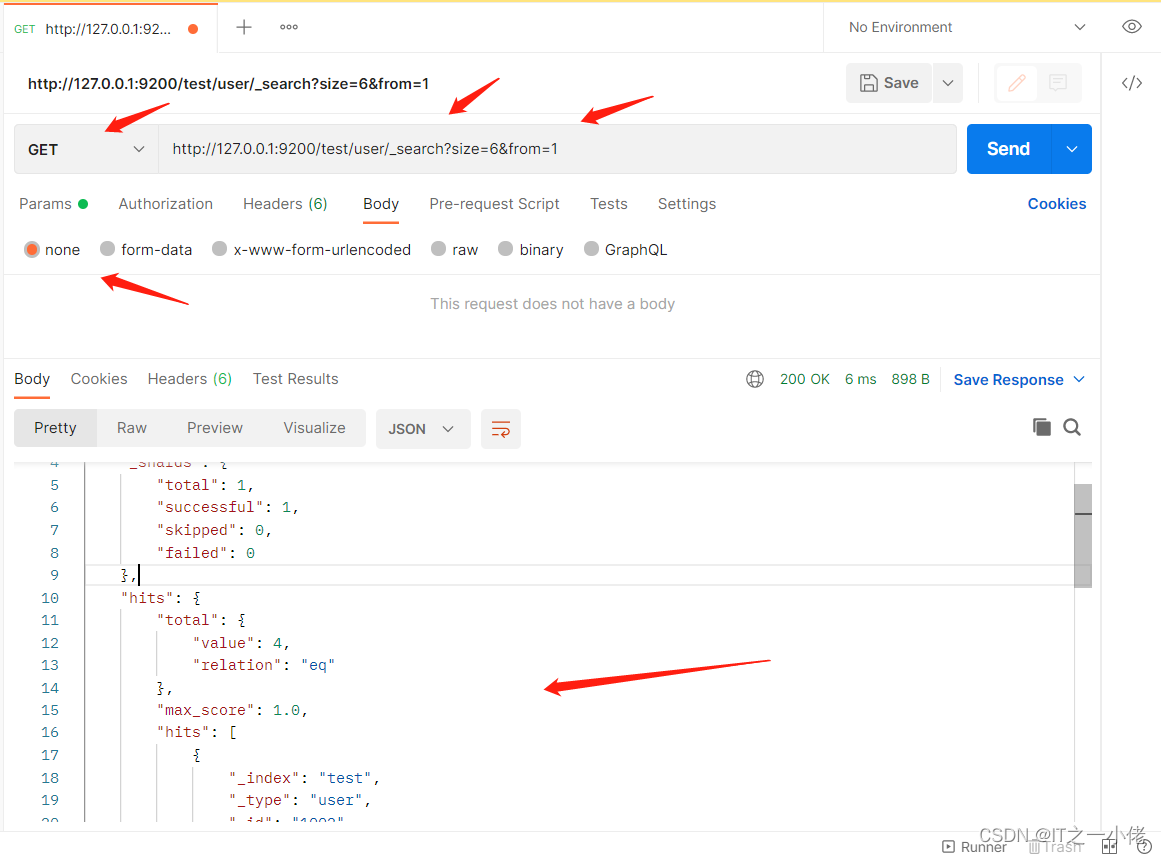
# 当数据量不够时
GET http://127.0.0.1:9200/test/user/_search?size=6&from=1
#响应数据
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "user",
"_id": "1002",
"_score": 1.0,
"_source": {
"id": 1002,
"name": "李四",
"age": 23,
"sex": "女"
}
},
{
"_index": "test",
"_type": "user",
"_id": "1003",
"_score": 1.0,
"_source": {
"id": 1003,
"name": "王五",
"age": 27,
"sex": "男"
}
},
{
"_index": "test",
"_type": "user",
"_id": "1004",
"_score": 1.0,
"_source": {
"id": 1004,
"name": "赵六",
"age": 29,
"sex": "女"
}
}
]
}
}
在集群系统中深度分页
为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当请求结果的第一 页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。
现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的 10010个结果。然后请求节点排序这50050个结果并丢弃50040个!
可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。如微博前端页面返回的页数只有50页,用工具是可以拿到50页以后的数据的。














 7223
7223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









