









1、写入数据
示例代码:
"""
pandas将数据写入excel文件
"""
import pandas
import string
import random
data_list = []
for i in range(20):
data_dict = {"num": i, "title": "".join(random.sample(string.ascii_letters, 2)),
"value": "".join(random.sample(string.digits, 2))}
print(data_dict)
data_list.append(data_dict)
# 创建DataFrame数据对象
df = pandas.DataFrame(data_list)
df.to_excel('./data/pandas_to_excel.xlsx', sheet_name="Sheet1", index=False, header=True)
运行结果:
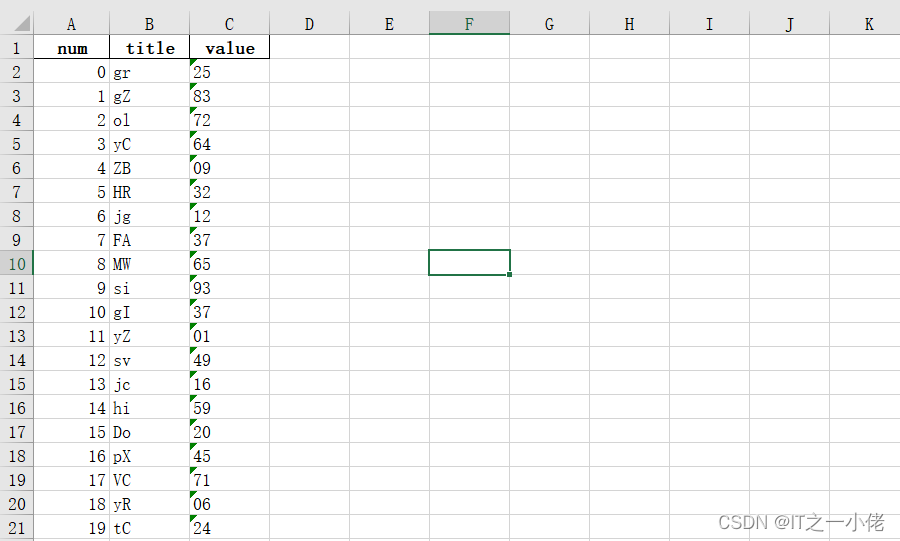
2、读取数据
使用pandas库来读取xlsx格式中的数据。
excel中数据:
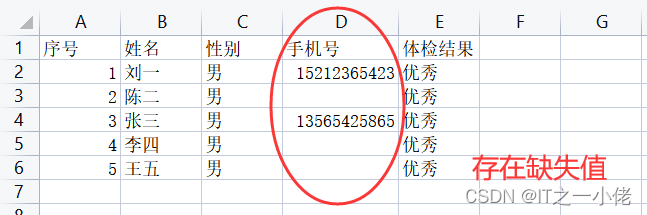
示例代码:
import pandas as pd
# data = pd.read_excel('./data/体检表.xlsx')
# data = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
data = pd.read_excel('./data/体检表.xlsx', sheet_name=0)
print(data)
print("*" * 100)
data = pd.read_excel('./data/体检表.xlsx', sheet_name=0, header=0, usecols=[1, 2, 4])
"""
sheet_name:返回指定的sheet,如果将sheet_name指定为None,则返回全表,如果需要返回多个表,可以将sheet_name指定为一个列表,例如['sheet1', 'sheet2']
header:指定数据表的表头,默认值为0,即将第一行作为表头。
usecols:读取指定的列,例如想要读取第一列和第二列数据
"""
print(data)
运行结果:
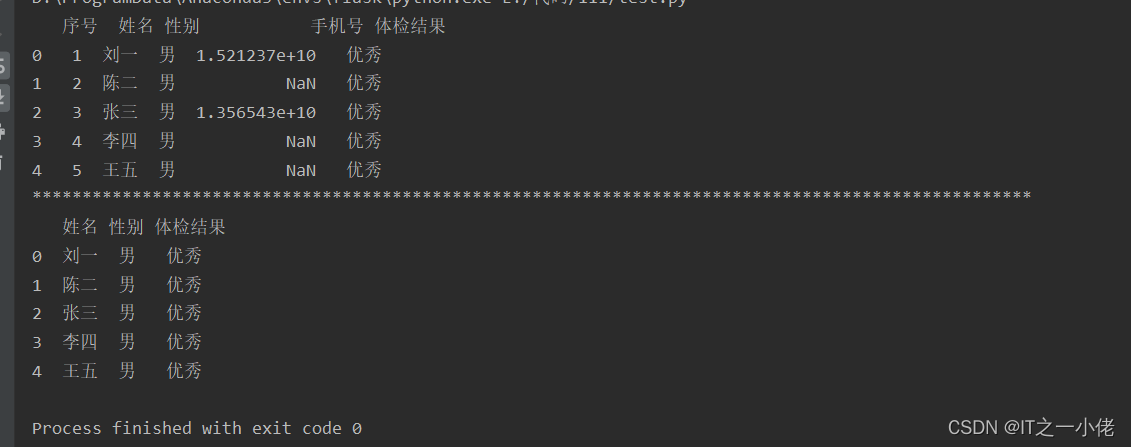
3、修改数据
示例代码1: 【修改xlsx中的数据】
import pandas as pd
from pandas import DataFrame
data = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
print(data)
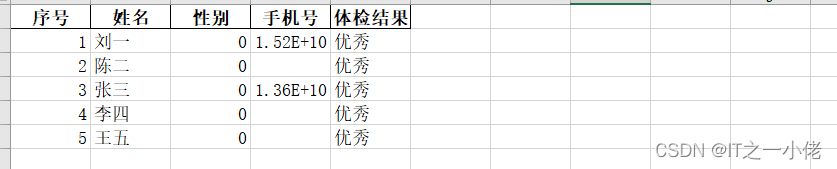
# 将性别中的男修改为数字0,女修改为数字1
data['性别'][data['性别'] == '男'] = 0
data['性别'][data['性别'] == '女'] = 1
print(data)
"""
注意:这里的data为excel数据的一份拷贝,对data进行修改并不会直接影响到我们原来的excel,必须在修改后保存才能够修改excel。
"""
# 下面代码将会新建一个文件,如果存在则会覆盖整个文件,类似于‘w’模式
# DataFrame(data).to_excel('./data/体检表4.xlsx', sheet_name='Sheet1', index=False, header=True)
data.to_excel('./data/体检表2.xlsx', sheet_name='Sheet1', index=False, header=True)运行结果:
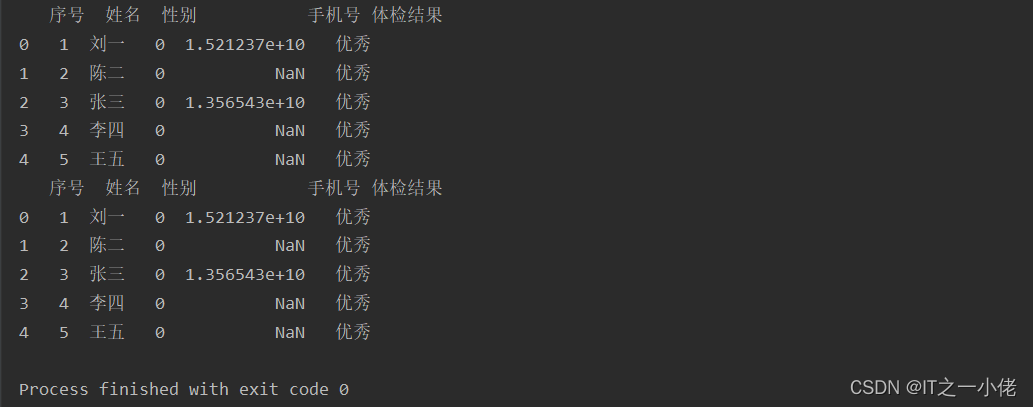
示例代码2: 【对excel文件进行修改,添加某些列】
import pandas as pd
import json
with open('country_info.txt', 'r', encoding='utf-8') as f:
country_data = json.load(f)
"""
{
"AO": ["Angola", "安哥拉", "244"],
"AF": ["Afghanistan", "阿富汗", "93"],
"AL": ["Albania", "阿尔巴尼亚", "355"]
}
"""
df = pd.read_excel('facebook.xlsx')
df['电话代码'] = 0
# 获取excel表格的行列
row, col = df.shape
print(row, col)
for i in range(row):
tmp = df.iloc[i]
print(i, tmp['地区代码'], tmp['whatsapp'])
if pd.isnull(tmp['地区代码']):
break
tmp['城市'] = country_data[tmp['地区代码']][1]
tmp['电话代码'] = country_data[tmp['地区代码']][2]
phone = str(tmp['whatsapp']).replace('+', '').replace('’', '').replace('‘', '').replace("'", "")
if phone[:len(tmp['电话代码'])] != tmp['电话代码']:
phone = "+" + str(tmp['电话代码']) + str(phone)
else:
phone = "+" + str(phone)
df.iloc[i, 2] = phone
df.iloc[i, 6] = tmp['城市']
df.iloc[i, 8] = tmp['电话代码']
df.to_excel('facebook_new.xlsx', sheet_name='Sheet1', index=False, header=True)
















 5438
5438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









