






此篇文章主要分析游双老师的TinyWebServer里http_conn里的逻辑
其中项目中使用的是主从状态机,先来看看流程图:
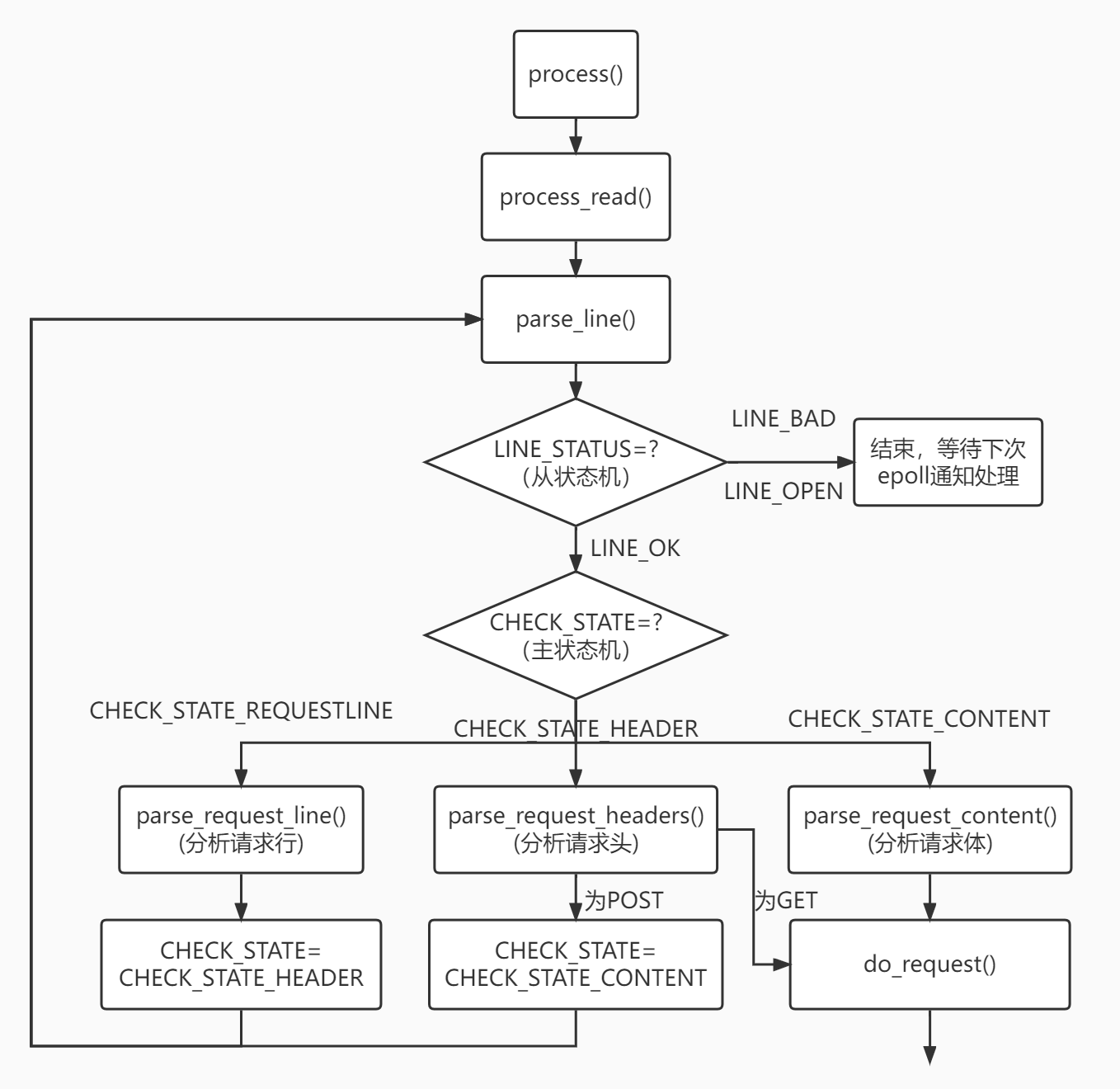
应该是比较清晰的,主状态机三个状态,REQUESTLINE,HEADER,CONTENT,从状态机三个状态,LINE_OK,BAD,OPEN,依照不同的状态做出不同的反应,现在看不懂不要紧,先来看看介绍
状态信息(http_conn.h)
HTTP请求方法
enum METHOD
{
GET = 0,//向服务器获取资源,常见的查询请求
POST,//向服务器提交数据的请求
HEAD,//与get类似,返回的相应没有具体内容,用于获取报头
PUT,//一般用于更新请求
DELETE,//删除资源
TRACE,//回显服务器收到的请求,主要用于测试
OPTIONS,//获取服务器支持的http请求方法,服务器性能,跨域检查等
CONNECT,//让服务器代替用户去访问其它网页,之后把数据返回给用户,一般用于http代理
PATCH//对put方法的补充,对指定资源进行局部更新
};其中GET,POST,HEAD这三种是HTTP1.0版本的,功能如上述
HTTP1.1更新了六种HTTP请求方法,PUT,DELETE,TRACE,OPTIONS,CONNECT,PATCH。
这里要说明一下,游双老师的TinyWebServer最后一个写的是PATH但实际上此项目只用上了GET和POST,而HTTP1.1版本最后一个是PATCH,所以我改成PATCH了。还有一点是虽然规定是写的这些方法应该是这些功能,但实际上服务器的方法判定可以随意编写,你把GET方法写成删除资源,DELETE写成提交数据都是没问题的,只是会严重减低代码的可读性罢了。当然没必要这样恶搞,如果要实现新功能自命名写好注释就好了。
主状态机,用于分析当前分析的状态:
enum CHECK_STATE
{
CHECK_STATE_REQUESTLINE = 0,//解析请求行
CHECK_STATE_HEADER,//清晰请求头
CHECK_STATE_CONTENT//解析请求体,仅用于post
};主状态机主要体现在process_read()中
响应状态如下:
enum HTTP_CODE
{
NO_REQUEST,//请求不完整,需要继续请求
GET_REQUEST,//get,跳转do_request()
BAD_REQUEST,//语法有误
NO_RESOURCE,//请求不存在
FORBIDDEN_REQUEST,//禁止访问,无权限
FILE_REQUEST,//可以正常访问文件,跳转process_write()
INTERNAL_ERROR,//服务器内部错误
CLOSED_CONNECTION//关闭连接
};从状态机用来判断当前行的状态:
enum LINE_STATUS
{
LINE_OK = 0,//当前行读取正常完成
LINE_BAD,//当前行读取出错,如结束不为/r/n
LINE_OPEN//读取行不完整,需要继续读
};从状态机体现在parse_line()中
逻辑流程
1、分析请求是线程池里的一个线程执行process()开始
void http_conn::process()
{
HTTP_CODE read_ret = process_read();
if (read_ret == NO_REQUEST)//请求不完整
{
modfd(m_epollfd, m_sockfd, EPOLLIN);//注册并监听读事件
return;
}
bool write_ret = process_write(read_ret);
if (!write_ret)
{
close_conn();
}
//触发EPOLLOUT事件让主线程处理
modfd(m_epollfd, m_sockfd, EPOLLOUT);
}2、process()里面第一步是process_read()读取请求
/*此时从状态机已提前将一行的末尾字符\r\n变为\0\0,
所以text可以直接取出完整的行进行解析*/
http_conn::HTTP_CODE http_conn::process_read()
{
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char *text = 0;
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK))
{//双判断是因为消息体末尾没有\r\n,所以需要额外判断
text = get_line();//m_read_buf + m_start_line
//m_start_line是每一个数据行在m_read_buf中的起始位置
//m_checked_idx表示从状态机在m_read_buf中读取的位置
m_start_line = m_checked_idx;
LOG_INFO("%s", text);//生成日志信息
Log::get_instance()->flush();
//主状态机的三种状态转移逻辑
switch (m_check_state)
{
case CHECK_STATE_REQUESTLINE://解析请求行
{
ret = parse_request_line(text);
if (ret == BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER://解析请求头
{
ret = parse_headers(text);
if (ret == BAD_REQUEST)//根本没有BAD状态
return BAD_REQUEST;
else if (ret == GET_REQUEST)
{
return do_request();
}
break;
}
case CHECK_STATE_CONTENT://解析消息体
{
ret = parse_content(text);
if (ret == GET_REQUEST)
return do_request();
line_status = LINE_OPEN;
break;
}
default:
return INTERNAL_ERROR;
}
}
return NO_REQUEST;
}这里已经到了主状态机的部分了,主状态机会分析m_check_state的状态判断现在是在分析请求行还是分析请求头或是请求体。而每次在主状态机判断之前都会调用parse_line()判断当前读取行的状态,也就是到了从状态机的范畴了。
3、process_read()中主状态机中每一次循环都会执行parse_line(),也就是每次判断主状态之前都会先进行从状态机的判断
http_conn::LINE_STATUS http_conn::parse_line()
{
char temp;
for (; m_checked_idx < m_read_idx; ++m_checked_idx)
{
temp = m_read_buf[m_checked_idx];
if (temp == '\r')
{
if ((m_checked_idx + 1) == m_read_idx)//已经到尾了,没有\n,说明读取未完整,数组下表范围为0-(m_read_idx-1)
return LINE_OPEN;
else if (m_read_buf[m_checked_idx + 1] == '\n')
{
m_read_buf[m_checked_idx++] = '\0';//把\r\n换成\0\0,下同
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
else if (temp == '\n')
{
if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r')
{
m_read_buf[m_checked_idx - 1] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
return LINE_OPEN;
}从状态机的逻辑比较简单,移动指针判断是否到达了结束边界(\r\n),如果正常抵达并无溢出则从状态机的状态为LINE_OK成功读取一行,若结束边界不同则返回LINE_BAD读取行错误,若指针到头了还没有找到边界则返回LINE_OPEN证明还没有读取到完整的一行,需要继续读取。
4、在从状态机成功读取一行后再进行主状态机的判断,进行请求行/头/体的分析,这三个函数我们来一个个分析
(1)parse_request_line()//分析请求行
//解析http请求行,获得请求方法,目标url及http版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{
m_url = strpbrk(text, " \t");//指向第一个出现的空格
if (!m_url)
{
return BAD_REQUEST;
}
*m_url++ = '\0';//将请求方式和路径间隔开
char *method = text;
if (strcasecmp(method, "GET") == 0)//比较,两字符串相等返回0
m_method = GET;
else if (strcasecmp(method, "POST") == 0)
{
m_method = POST;
cgi = 1;
}
else
return BAD_REQUEST;
m_url += strspn(m_url, " \t");//跳过额外的空格
m_version = strpbrk(m_url, " \t");
if (!m_version)
return BAD_REQUEST;
*m_version++ = '\0';
m_version += strspn(m_version, " \t");
if (strcasecmp(m_version, "HTTP/1.1") != 0)//只处理1.1版本
return BAD_REQUEST;
if (strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7;
m_url = strchr(m_url, '/');//指向/,下同
}
if (strncasecmp(m_url, "https://", 8) == 0)
{
m_url += 8;
m_url = strchr(m_url, '/');
}
if (!m_url || m_url[0] != '/')
return BAD_REQUEST;
//当url为/时,显示判断界面
if (strlen(m_url) == 1)//如果没有选择路径,则返回judge页面
strcat(m_url, "judge.html");
m_check_state = CHECK_STATE_HEADER;//主状态由分析请求行转变为分析请求头!!!
return NO_REQUEST;//分析未完成,继续分析
}将请求方法,路径,版本单独提取出来,成功的话将主状态由分析请求行转变为分析请求头
(2)parse_headers()//分析请求头
//解析http请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{
if (text[0] == '\0')//判断是空行还是请求头
{
if (m_content_length != 0)//如果是空行则判断有无消息体(是否是post)
{
m_check_state = CHECK_STATE_CONTENT;//主状态机改变,跳转到消息体处理状态
return NO_REQUEST;
}
return GET_REQUEST;
}
else if (strncasecmp(text, "Connection:", 11) == 0)//判断是否为长连接
{
text += 11;
text += strspn(text, " \t");
if (strcasecmp(text, "keep-alive") == 0)
{
m_linger = true;
}
}
else if (strncasecmp(text, "Content-length:", 15) == 0)//头部的内容长度
{
text += 15;
text += strspn(text, " \t");
m_content_length = atol(text);
}
else if (strncasecmp(text, "Host:", 5) == 0)//解析host字段
{
text += 5;
text += strspn(text, " \t");
m_host = text;
}
else
{
//printf("oop!unknow header: %s\n",text);
LOG_INFO("oop!unknow header: %s", text);
Log::get_instance()->flush();
//这里疑似少了return BAD_REQUEST
}
return NO_REQUEST;
}此处就分析了长连接,长度和host三个请求头,需要注意的是GET最后一行是空行,而POST最后一行还有消息体。如果是GET则主状态机分析完毕结束,如果是POST还需将状态转为分析请求体继续分析。
(3)parse_content()//分析请求体
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{
if (m_read_idx >= (m_content_length + m_checked_idx))//判断是否读入了消息体
{
text[m_content_length] = '\0';
//POST请求中最后为输入的用户名和密码
m_string = text;
return GET_REQUEST;
}
return NO_REQUEST;
}判断进入了请求体中则直接获取信息,退出主状态机。
5、退出主状态机后此时的HTTP_CODE为GET_REQUEST(并非都是GET,通过cgi判断是get还是post),进入do_request()进行响应处理
http_conn::HTTP_CODE http_conn::do_request()
{
strcpy(m_real_file, doc_root);
int len = strlen(doc_root);
//printf("m_url:%s\n", m_url);
const char *p = strrchr(m_url, '/');//从右开始找/
//处理cgi
if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3'))//若为post
{
//根据标志判断是登录检测还是注册检测
char flag = m_url[1];
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/");
strcat(m_url_real, m_url + 2);
strncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1);
free(m_url_real);
//将用户名和密码提取出来
//假设user=123&password=123
char name[100], password[100];
int i;
for (i = 5; m_string[i] != '&'; ++i)//下标0-4为‘user=’,所以从5开始
name[i - 5] = m_string[i];
name[i - 5] = '\0';//此时name为123
int j = 0;
for (i = i + 10; m_string[i] != '\0'; ++i, ++j)//接下来十个是password=,跳过就好
password[j] = m_string[i];//password为123
password[j] = '\0';
//同步线程登录校验
if (*(p + 1) == '3')//注册检验
{
//如果是注册,先检测数据库中是否有重名的
//没有重名的,进行增加数据
char *sql_insert = (char *)malloc(sizeof(char) * 200);
strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES(");
strcat(sql_insert, "'");
strcat(sql_insert, name);
strcat(sql_insert, "', '");
strcat(sql_insert, password);
strcat(sql_insert, "')");
if (users.find(name) == users.end())//若没找到对应的账号
{
m_lock.lock();
int res = mysql_query(mysql, sql_insert);//成功返回0!!!失败才是非0
users.insert(pair<string, string>(name, password));
m_lock.unlock();
if (!res)
strcpy(m_url, "/log.html");
else
strcpy(m_url, "/registerError.html");
}
else//若数据库里存在账号
strcpy(m_url, "/registerError.html");
}
//如果是登录,直接判断
//若浏览器端输入的用户名和密码在表中可以查找到,返回1,否则返回0
else if (*(p + 1) == '2')//登入检测
{
if (users.find(name) != users.end() && users[name] == password)
strcpy(m_url, "/welcome.html");
else
strcpy(m_url, "/logError.html");
}
}
if (*(p + 1) == '0')//注册
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/register.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '1')//登录
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/log.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '5')//请求图片
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/picture.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '6')//请求视频
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/video.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '7')//小小测试
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/fans.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else
strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);
if (stat(m_real_file, &m_file_stat) < 0)//stat是获得文件状态的函数
return NO_RESOURCE;
if (!(m_file_stat.st_mode & S_IROTH))//如果没有可读权限,S_IROTH是可读权限
return FORBIDDEN_REQUEST;
if (S_ISDIR(m_file_stat.st_mode))//判断文件类型,S_ISDIR是否为目录,是则有误
return BAD_REQUEST;
int fd = open(m_real_file, O_RDONLY);//以只读方式打开文件描述符
m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
//将文件描述符映射到内存里,访问内存不再需要IO操作用于提高性能
//start(开始地址,0则有系统自动分配),size,prot(打开方式,此处只读),flag(类型,私有映射),fd,offset(被映射内容起点)
close(fd);
return FILE_REQUEST;
}逻辑有点长,但总体来说并不难,判断是get或post,判断登录请求还是注册请求,判断请求的是哪个页面,最后的mmap是映射内存,访问内存文件不需要IO操作提高了性能。值得注意的是你会发现数据库只是走个形式,你直接通过网页输入路径的话也可以直接获取其它页面,为了解决这个问题可以直接加个登录状态检测即可,用Cookie和Session来实现保持登陆状态的功能即可。
6、do_request()完后基本上请求分析就完成了,剩下该做的事情就是根据请求内容进行反馈,也就是响应事件了,回到process运行到了process_write()
bool http_conn::process_write(HTTP_CODE ret)
{
switch (ret)
{
case INTERNAL_ERROR://内部错误,500
{
add_status_line(500, error_500_title);//添加响应行
add_headers(strlen(error_500_form));//响应头
if (!add_content(error_500_form))
return false;
break;
}
case BAD_REQUEST://找不到,404
{
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if (!add_content(error_404_form))
return false;
break;
}
case FORBIDDEN_REQUEST://无权限,403
{
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
if (!add_content(error_403_form))
return false;
break;
}
case FILE_REQUEST://正常,200
{
add_status_line(200, ok_200_title);
if (m_file_stat.st_size != 0)//如果请求的资源存在
{
add_headers(m_file_stat.st_size);
//第一个iovec指针指向响应报文缓冲区,长度指向m_write_idx
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
//第二个iovec指针指向mmap返回的文件指针,长度指向文件大小
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
//发送的全部数据为响应报文头部信息和文件大小
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
}
else//如果资源大小为0,则返回空白html文件
{
const char *ok_string = "<html><body></body></html>";
add_headers(strlen(ok_string));
if (!add_content(ok_string))
return false;
}
}
default:
return false;
}
//除FILE_REQUEST状态外,其余状态只申请一个iovec,指向响应报文缓冲区
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv_count = 1;
bytes_to_send = m_write_idx;
return true;
}根据响应状态进行添加响应行,响应头,值得注意的是iov(iovector,IO向量)是个结构体,共有两个元素,一个指针,一个长度。剩余的一些响应函数如(add_status_line)并不难且大同小异,相信大家看一看就能理解了。
最后可以再把一开始的流程图看一看,或者自己画一画,我也不清楚这样画算不算对,如果有更好的欢迎讨论。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









