









本文基于Hugging Face的2.6.0版本的Transformers包进行解析,不同版本间略有差异,但无伤大雅。

I. Self-attention的Hugging Face实现
(I). 多头自注意力的实现原理
关于Transformer的讲解不胜其数,这里就不多写了。
本文主要写一下多头自注意力机制的操作。我们知道,多头自注意力是要分多个head分别进行自注意力操作,然后将每个head的计算结果concate在一起,然后进行全连接层、LayerNorm等操作,最终得到MHA的输出。
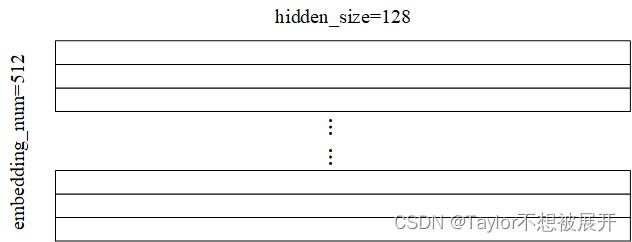
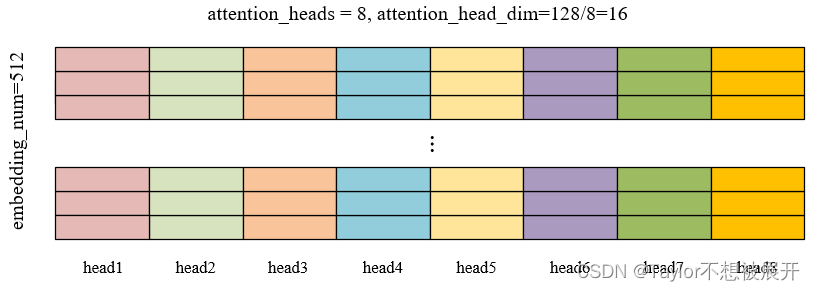
那么,很多人困惑的点在于,如何将输入特征图(或者说输入序列)转换为多头的输入呢?假设batchsize=1,embedding数量为512,embedding维度(即代码中的hidden_size)为128,即输入序列的维度是[1, 512, 128],head的数量为8个。代码中的操作是将这个[1, 512, 128]直接进行投影变换
,投影矩阵的维度均为128×128,得到Q, K, V,如图(2)所示。
然后通过view函数将其变形为[1, 512, 8, 16],再通过premute函数交换维度,得到[1, 8, 512, 16],具体来看就是图(2)中8个不同颜色的512×16的张量,然后就可以进行多头自注意力计算了。算完之后并不需要concate函数进行拼接,因为是一直在进行矩阵运算,并没有将其切开,本身就是拼在一起的。
其实可以想一想,
中前第1-16列是同一种颜色的,17-32列是另外同一种颜色……以此类推,这就是矩阵运算的魅力。
另外为什么要先用view后用permute来得到[1, 8, 512, 16]这个维度呢?直接view或者reshape不行吗?那绝对是不行的,这个涉及到按行还是按列展开的问题,感兴趣的可以搜一下。
(II). 代码实现及解析
BertAttention类的实现:
class BertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = BertSelfAttention(config) # self-attention
self.output = BertSelfOutput(config) # self-attention后的FC层、DropOut、残差连接和LayerNorm
self.pruned_heads = set() # set()函数创建一个无序不重复元素集
def prune_heads(self, heads):
"""剪枝, 一般用不到"""
if len(heads) == 0:
return
mask = torch.ones(self.self.num_attention_heads, self.self.attention_head_size)
heads = set(heads) - self.pruned_heads # Convert to set and remove already pruned heads
for head in heads:
# Compute how many pruned heads are before the head and move the index accordingly
head = head - sum(1 if h < head else 0 for h in self.pruned_heads)
mask[head] = 0
mask = mask.view(-1).contiguous().eq(1)
index = torch.arange(len(mask))[mask].long()
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
):
self_outputs = self.self(
hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask
) # 计算self-attention
attention_output = self.output(self_outputs[0], hidden_states) # 计算self-attention后的FC层、Norm等
# 下面这行有个点要注意:self_outputs[1:]和self_outputs[1]不一样, 若self_outputs[1]不存在, 前者返回的是(), 而后者则会报错
# 另外, 关于元组的定义中, 若要定义一个单元素的元组, 必须加逗号, 即(1,)才为tuple, 而(1)为int
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputsBertSelfAttention类的实现:
class BertSelfAttention(nn.Module):
"""self-attention计算
返回值: 若config.output_attentions为默认值(False), 返回的outputs即为self-attention的计算结果
若config.output_attentions设置为True, outputs里是self-attention的计算结果和attention weight"""
def __init__(self, config):
super().__init__()
# hidden_size为每条embedding的维度, 必须是num_attention_heads的整数倍
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
# config传参教程:https://www.cnblogs.com/douzujun/p/13572694.html or https://www.zhihu.com/question/493902475
self.output_attentions = config.output_attentions # 默认为False, 若config.output_attentions设置为True, 会返回注意力权重
self.num_attention_heads = config.num_attention_heads # attention head数量
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
# self.all_head_size这个参数看起来多此一举, 但是仔细观察会发现它和config.hidden_size未必是相等的
# 主要原因是上面采用了剪枝函数。一般不会采用剪枝, 因此两个参数一般是相等的
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size) # WQ
self.key = nn.Linear(config.hidden_size, self.all_head_size) # WK
self.value = nn.Linear(config.hidden_size, self.all_head_size) # WV
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
# x的维度为[batchsize, 512, 128], x.size[:-1]的维度为[batchsize, 512]
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size) # new_x_shape的维度为[batchsize, 512, 8, 16]
x = x.view(*new_x_shape) # x的新维度为[batchsize, 512, self.num_attention_heads, self.attention_head_size]=[batchsize, 512, 8, 16]
return x.permute(0, 2, 1, 3) # 将self.num_attention_heads调整为channel, [batchsize, 8, 512, 16]
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None, # 用于将某些头的注意力计算无效化, 一般用不到
encoder_hidden_states=None,
encoder_attention_mask=None,
):
mixed_query_layer = self.query(hidden_states) # Query
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
# 如果传入了encoder_hidden_states, 说明是作为cross-attention来用, 那么Key、Value和Query的来源就不同了
if encoder_hidden_states is not None:
mixed_key_layer = self.key(encoder_hidden_states)
mixed_value_layer = self.value(encoder_hidden_states)
attention_mask = encoder_attention_mask
else:
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
# 下面三个的维度均为(batchsize, num_attention_heads, embedding_num(512), attention_head_size)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2)) # 计算attention weight
attention_scores = attention_scores / math.sqrt(self.attention_head_size) # scale
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
# 为什么是+而不是×,详见:https://zhuanlan.zhihu.com/p/360988428
# +和×实现的效果是一样的,无非一个是加一个极小的负数, 一个是乘极小的整数, 都是为了让attention weight在softmax后接近于0
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
# attention_probs不但做了softmax,还用了一次dropout,这是担心attention矩阵太稠密吗?
# 这里也提到很不寻常, 但是原始Transformer论文就是这么做的
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
# context_layer即为self-attention的计算结果
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape) # 恢复input的形状, 即[batchsize, embedding_num(512), hidden_size(128)]
# 一般self.output_attentions不会设置为True, 默认为False
# 若设置为True, outputs是一个含两个元素的元组, 第一个元素是self-attention的计算结果, 第二个元素是attention weights
outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
return outputsBertSelfOutput类的实现:
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states参考:BERT源码详解(一)——HuggingFace Transformers最新版本源码解读 - 知乎 (zhihu.com)
















 1924
1924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











