







1. 项目介绍
本项目旨在利用先进的YOLOv8深度学习模型对麦穗进行高效、准确的检测。我们采用了GlobalWheat数据集,该数据集包含丰富的麦穗图像,为模型的训练提供了有力的数据支持。通过该实验,实现高准确率的麦穗识别,为农业生产提供智能化的监测手段。这一项目将有助于农民更准确地评估作物生长状况,优化种植策略,提高农业生产的效率和质量。
YOLOv8是目标检测领域的一款先进模型,它继承了YOLO系列的核心思想,即一次性对整个图像进行预测以实现快速目标检测。该模型在多个尺度上提供了不同大小的模型(N/S/M/L/X),以满足不同场景的需求。本实验采用YOLOv8n进行实验。
Swanhub是由极客工作室开发的一个开源模型协作分享社区。它为AI开发者提供了AI模型托管、训练记录、模型结果展示、API快速部署等功能。
-
YOLOv8模型:GitHub - YOLOv8
SwanHub:SwanHub - 创新的AI开源社区
SwanLab:SwanLab - 在线AI实验平台
项目团队:新疆大学大数据挖掘和智能计算实验室
2. 准备
2.1 安装python库
安装以下4个库
torch>=2.0.0 torchvision>=0.15.1 swanlab>=0.2.4 gradio>=3.50.2安装命令:
pip install torch>=2.0.0 torchvision>=0.15.1 swanlab>=0.2.4 gradio>=3.50.22.2 下载数据集
案例(全球麦穗数据集GlobalWheat):链接:https://pan.baidu.com/s/1HZB4na0q3u94CJyWVnRyZw
提取码:2g3n
GlobalWheat
--images
----train
------1.jpg
------2.jpg
----test
------1.jpg
------2.jpg
----vaildation
------1.jpg
------2.jpg
--labels
----train
------1.txt
------2.txt
----test
------1.txt
------2.txt
----vaildation
------1.txt
------2.txt它们各自的作用与意义:
-
GlobalWheat文件夹:该文件夹用于存储图片文件夹images与标签文件夹labels
-
images文件夹:该文件夹用于保存训练、测试、验证图片文件夹。
-
labels文件夹:该文件夹用于保存训练、测试、验证标签文件夹。
2.3 下载YOLOv8模型
模型链接:https://github.com/ultralytics/ultralytics
解压后得到ultralytics-main文件夹,并安装ultralytics库,命令如下:
pip install ultralytics2.4 创建文件目录
在ultralytics-main文件夹中创建app.py,main.py,将GlobalWheat文件夹导入,并在GlobalWheat文件夹中创建wheat.yaml
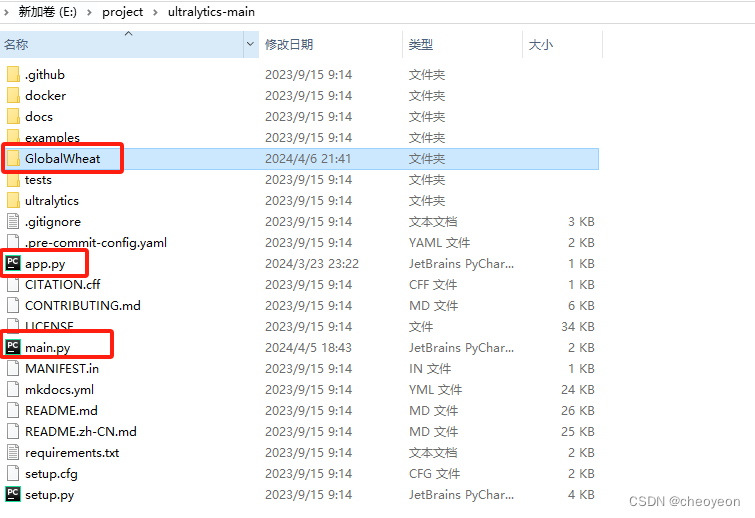
它们各自的作用分别是:
-
GlobalWheat:这个文件夹用于存储数据集
-
main.py:用于训练YOLOv8模型的脚本
-
app.py:运行Gradio Demo的脚本
-
wheat.yaml:保存数据集中训练、测试、验证集的绝对路径,以及类别。
3. 训练部分
3.1 模型训练
首先将yolov8.yaml文件导入模型,再进行模型训练。其中,data代表数据集路径,epoch代表训练次数,imgsz表示图片输入尺寸。
具体代码:
from ultralytics import YOLO
if __name__ == '__main__':
# 模型训练
model = YOLO("ultralytics/cfg/models/v8/yolov8.yaml")
model.load()
model.train(data="./GlobalWheat2020/wheat.yaml", epochs=50, imgsz=640)
3.2 初始化SwanLab
SwanLab是一个类似Tensorboard的开源训练图表可视化库,有着更轻量的体积与更友好的API,除了能记录指标,还能自动记录训练的logging、硬件环境、Python环境、训练时间等信息。

设置初始化配置参数:SwanLab库使用s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









