







引:对于pandas中的对象(DataFrame和Series),可以使用函数对元素进行操作。在《利用python进行数据分析》一书中,简要介绍了4种方法:
1、使用NumPy的ufuncs(元素级数组方法)用于操作pandas对象:
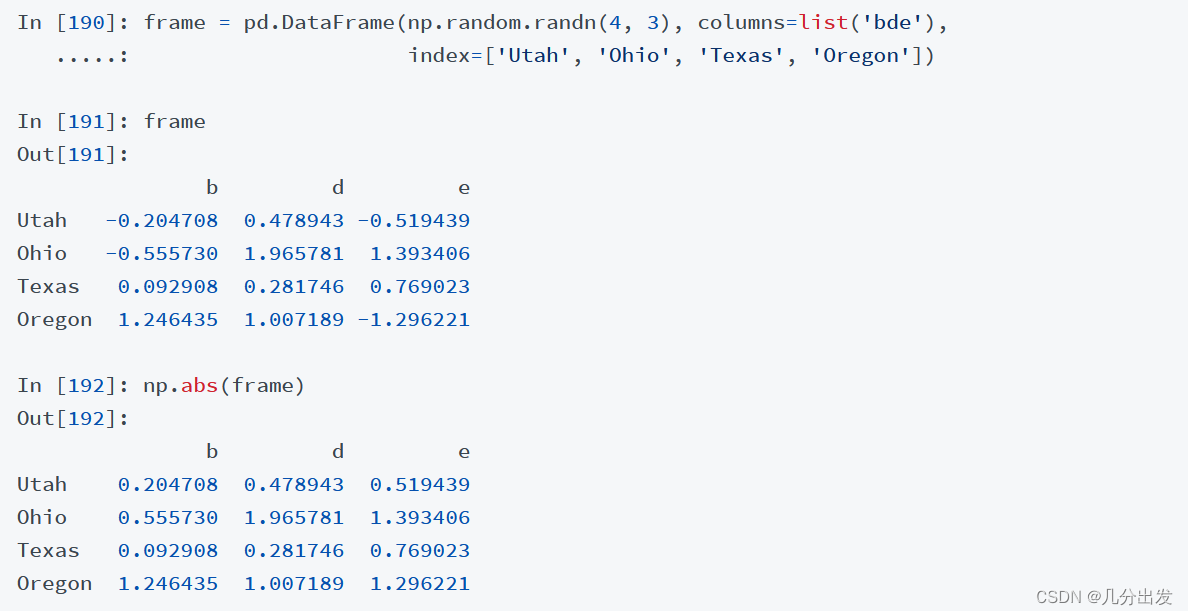
接下来便是今天要说的三个方法:map()、apply()、applymap()
但是以上方法存在速度慢的缺陷,我将在后面讨论
一、Series:map、apply
对于Series来说,有map和apply两种方法,他们的作用都是把Series中的值代进函数中去;或者可以认为按Series索引迭代执行函数,
官方文档中对map的定义是:

根据输入映射或函数映射序列的值。
用于将序列中的每个值替换为另一个值,可能派生于函数或一个序列、字典
对于apply的定义:

对序列的值调用函数。
可以是 ufunc(适用于整个系列的 NumPy 函数) 或仅适用于单个值的 Python 函数。
例:
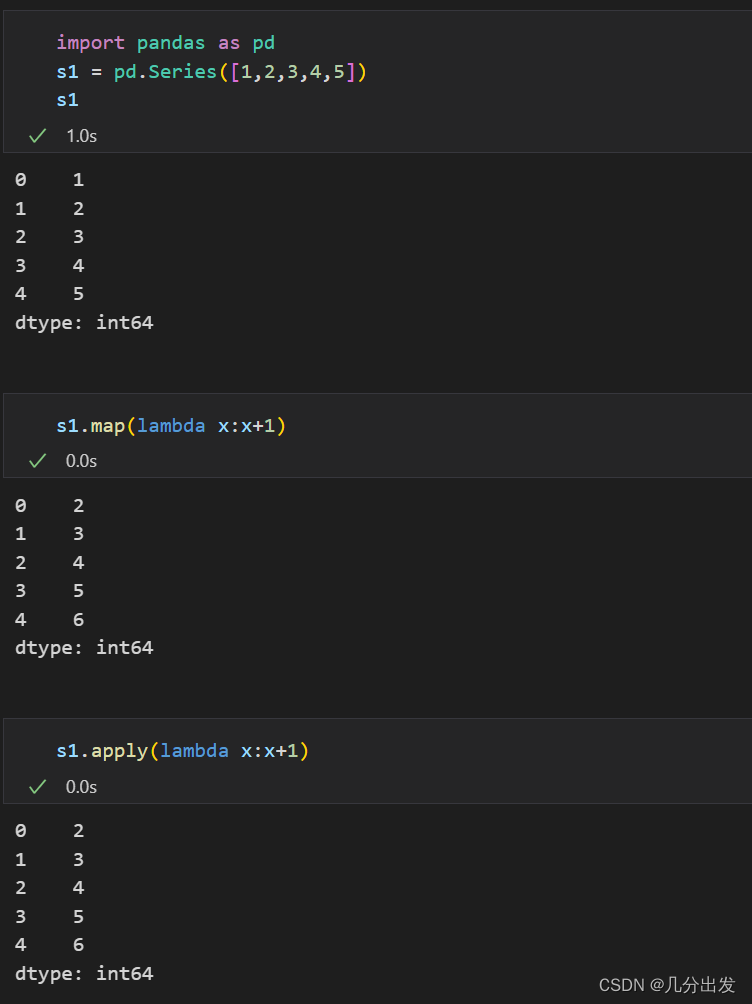
除了给入一个lambda函数作为参数,还可以自定义函数作为参数,只要保证自定义函数的参数和返回值都是一个。
apply和map两者还是有一些差异,对于map来说,它做的事情就是“将原本的值映射(mapping)到另外的值”因此map不但可以接收一个函数,它也可以接受dictionary或另外一个Series,只要是可以一一对应的就好
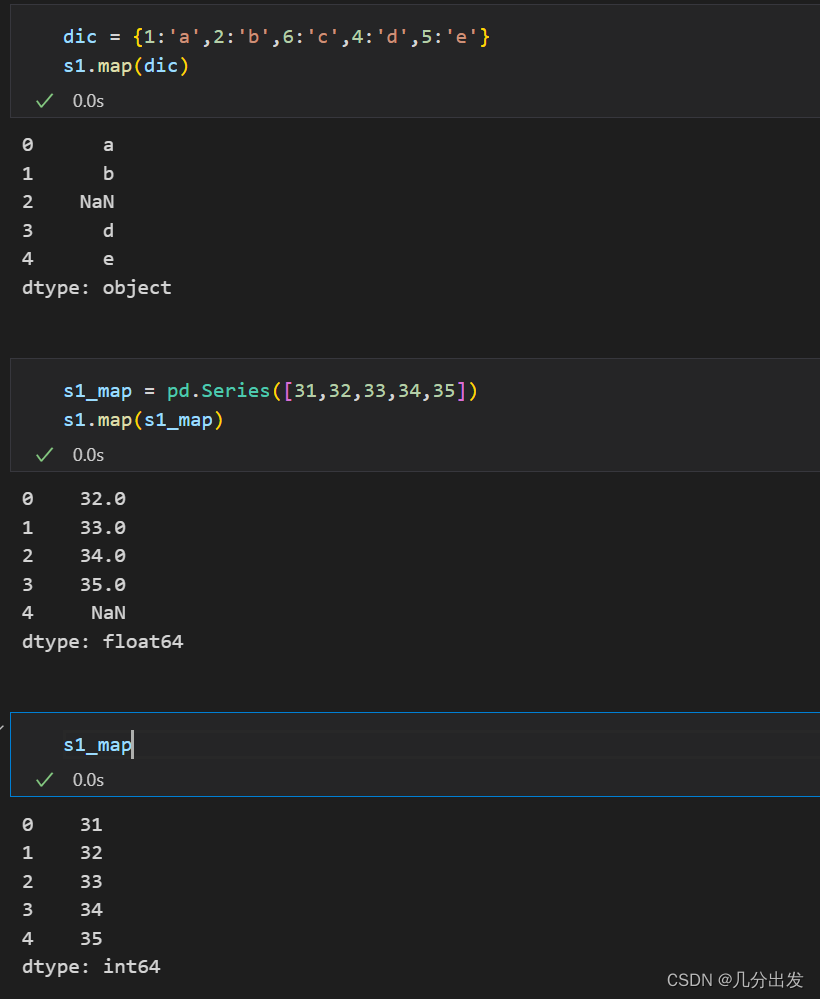
如果给定的是dictionary,那么dictionary的keys就相当于函数的输入,而key所对应的value就相当于函数的输出,所以上面的dic中,1这个key对应的value是'a',所以map后,1就变成'a'了,另一方面,dic中并没有3这个key,所以s1中原本是3的值,但map后就变成了NaN
那如果给定的是Series,概念和dictionary时相似的,只是函数的输入变成Series的index,函数的输出变成index所对应的值,所以s1中,原本为1的值,在map后变成32,因为s1_map中,index=1的值就是32
那对 apply 来说,虽然它没办法像map那样还可以接受dictionary和Series,但是它可以给定额外的参数
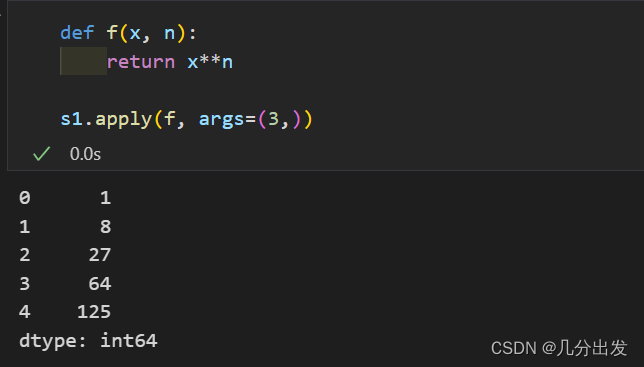
用法如上图
二、DataFrame:apply、applymap
那对于DataFrame来说,则有apply和applymap可以用。
官方文档对apply的定义:

沿DataFrame的一个轴映射函数(理解为对每一行执行函数或某一列执行函数)
参数axis=0(默认值)时,每一行(是一个Series)作为对象传进函数;axis=1时,每一列作为对象传进函数。返回类型与函数返回类型有关,或在参数result_type中指定
对applymap的定义:

对DataFrame中的元素应用函数
映射的函数接受并返回一个标量(元素级)
apply的功能为以行(或列)为单位做计算,applymap则是做element-wise的计算
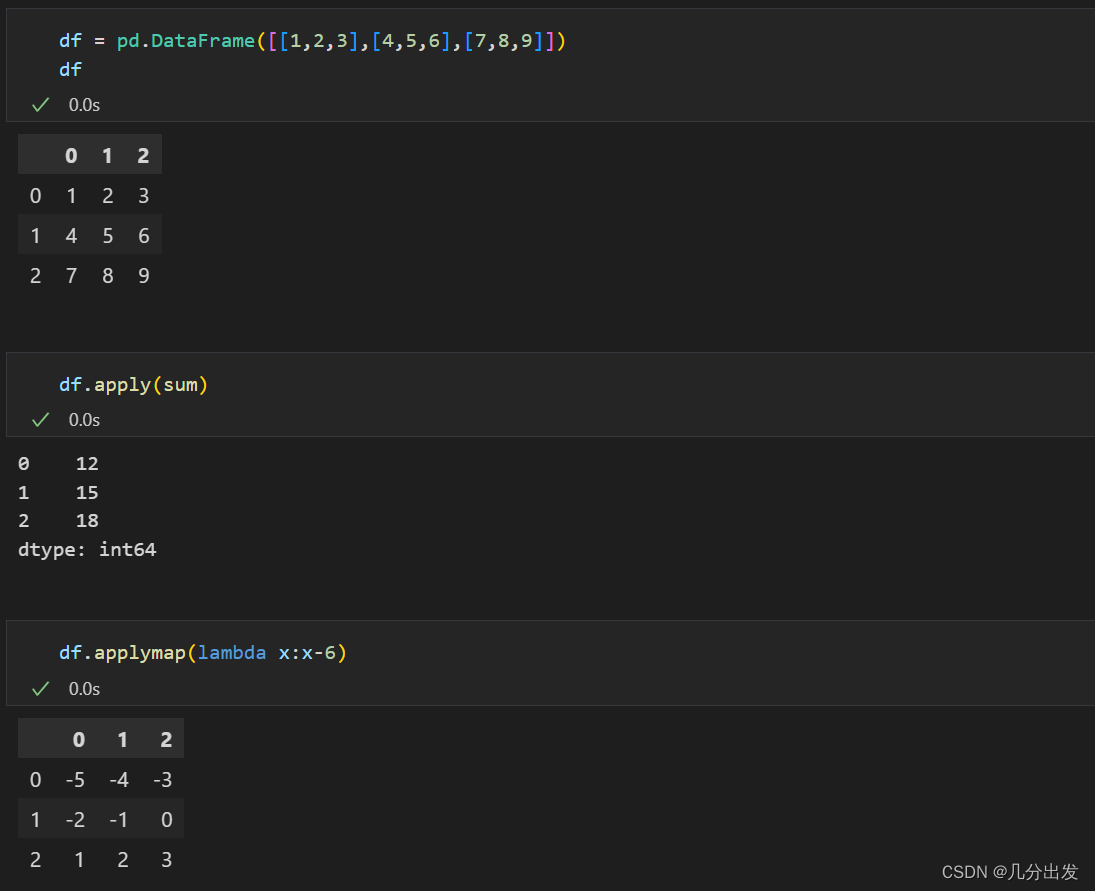
另外 apply 可以给定输入函数的额外参数,而 applymap 无法
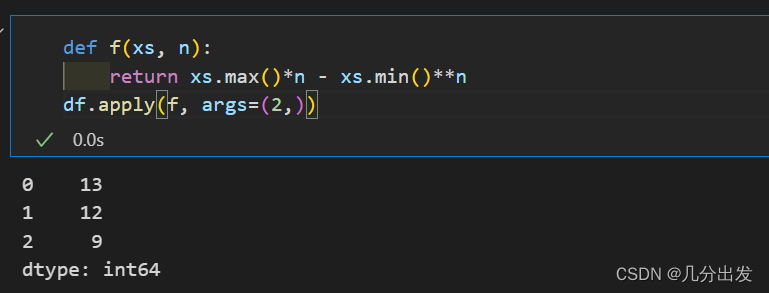
而因为apply是在做aggregates操作,因此输入的函数应该要为aggregates function,像上面是给定sum,但是如果输入的函数给了ufunc或类似的函数,那apply也会有element-wise的结果
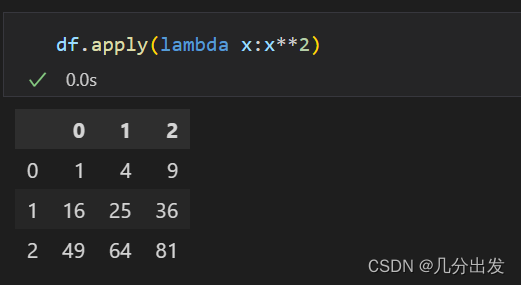
总结
Series中有apply及map,两者功能相似,都是将原本的值转换成另一个值,但是map可以给定function、dictionary、Series,而 apply 只能给定 function,但同时它有 args 可以设定,可以给定输入函数的额外参数
DataFrame中有apply和applymap,apply是针对column的aggregates操作,applymap则是element-wise,但是如果使用apply时,给定的函数是一个ufunc,那么它也会有element-wise的结果
三、apply的速度问题
我在实际使用apply过程中发现他的速度很慢(其实一开始不知道是因为apply()慢,看了一些资料后才明白)
apply因为执行的时候要找到函数,而这个函数是python写的,因此会拖慢速度
改善的方法是尽量不用apply,而是执行矢量化操作(详见参考资料2)
其实很简单,就是使用类似df['energy_kwh'] * price来代替apply的逐行(列、元素)操作。
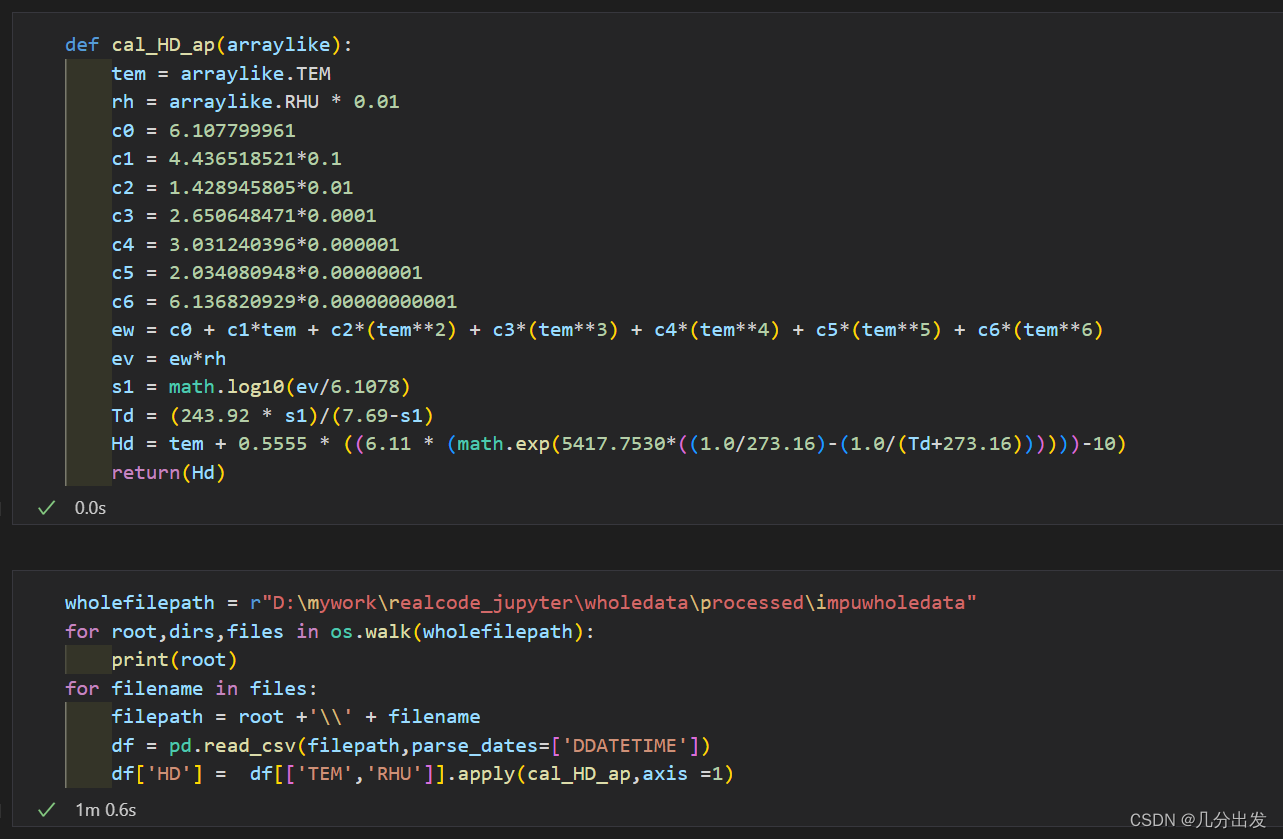
举一个例子,要计算体感温度humidex指数(体感温度指数的一种,计算公式链接),需要两个变量:温度和相对湿度。在DataFrame列中,有'TEM'、'RHU'列分别代表温度和相对湿度。

分别使用apply方法和矢量化操作在同样的数据上花费的时间:
apply:(1m0.6s)
矢量化操作:(4.9s)
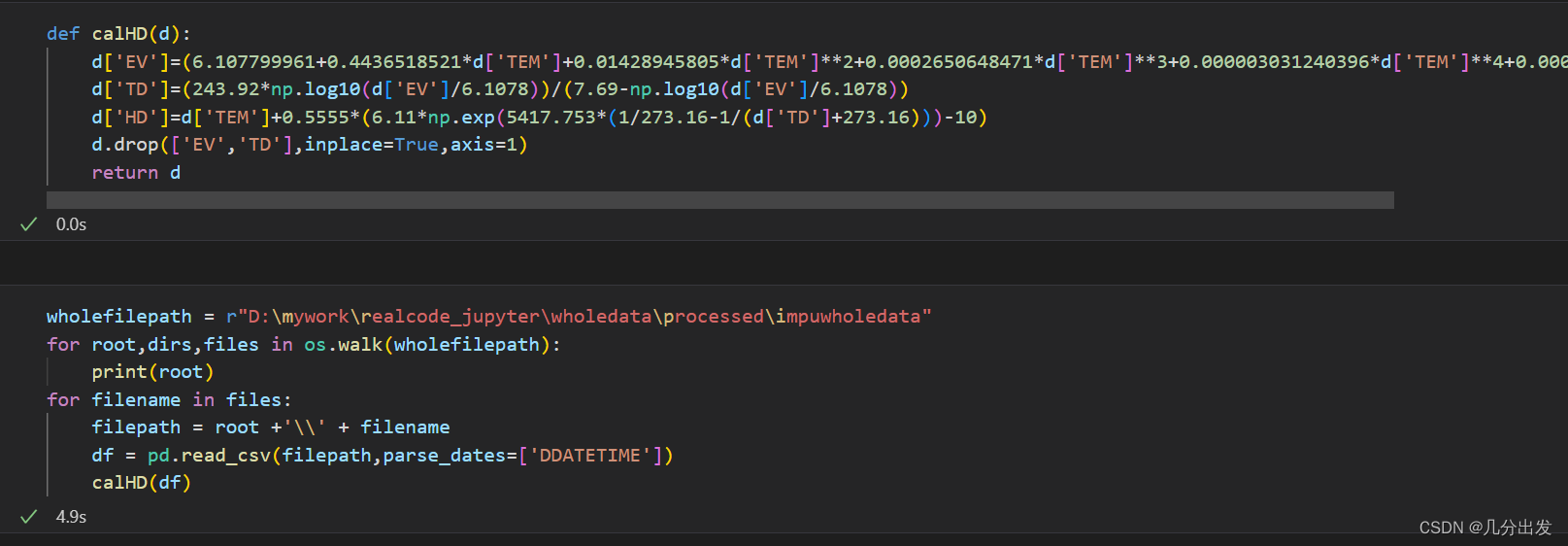
可以看到,矢量化操作速度更快,而apply方法较慢。如果在大数据集上使用了较多apply方法,那花费的时间可想而知
创作不易,欢迎点赞、收藏、加关注!
我的公众号【光阴似贱日月如琐】,欢迎交流


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











