







EDA
作者提出四种简洁有效的文本数据增强方法,可以提升分类任务的效果,称为EDA(Easy Data Augmentation),四种方法如下:
- 同义词替换(Synonym Replacement):从输入中随机选择 N 个非停用词,对选中的词,从它们的同义词中随即选择一个替换原词。
- 随机插入(Random Insertation):随机选择一个非停用词,然后随机选择该非停用词的一个同义词,将该同义词随机插入输入序列的任意位置上,重复 N 次。
- 随机调换(Random Swap):随机选择输入序列中的一个词对,调换它们的顺序,重复该过程 N 次。
- 随机删除(Random Deletion):以一定的概率随机删除序列中的每一个词。
在增强训练数据集时,每一样本仅采用4中方法中的任意一种。另一方面,长文本比短文本具有更强的抗噪声能力,因此不同长度的序列处理程度也不同。对于前三种方法,
N
=
L
∗
α
,
0
<
α
<
1
N = L * \alpha, 0< \alpha <1
N=L∗α,0<α<1, 第四种方法,删除概率取值为
α
\alpha
α。至于每条训练样本,需要增强几个样本,可以参考实验结果。
实验结果
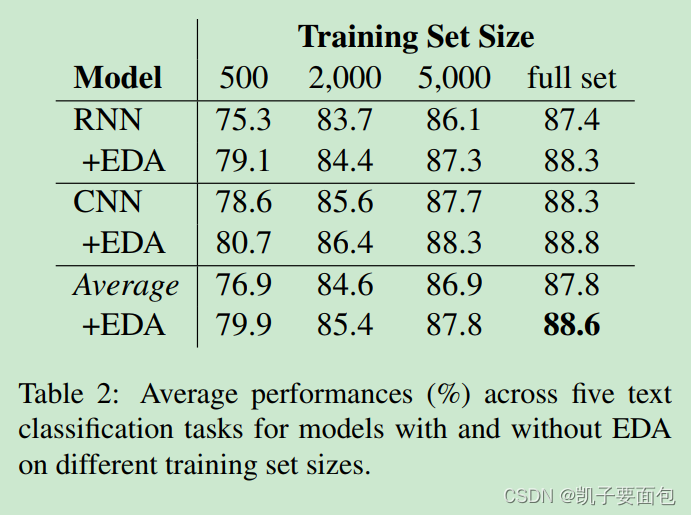
在训练集样本量为500时,使用EDA比不使用平均提升3.0%, 在全量数据下,使用EDA比不使用平均提升0.8%。可见EDA对小样本数据集的效果更好,在大样本情况下,效果提升很微弱。
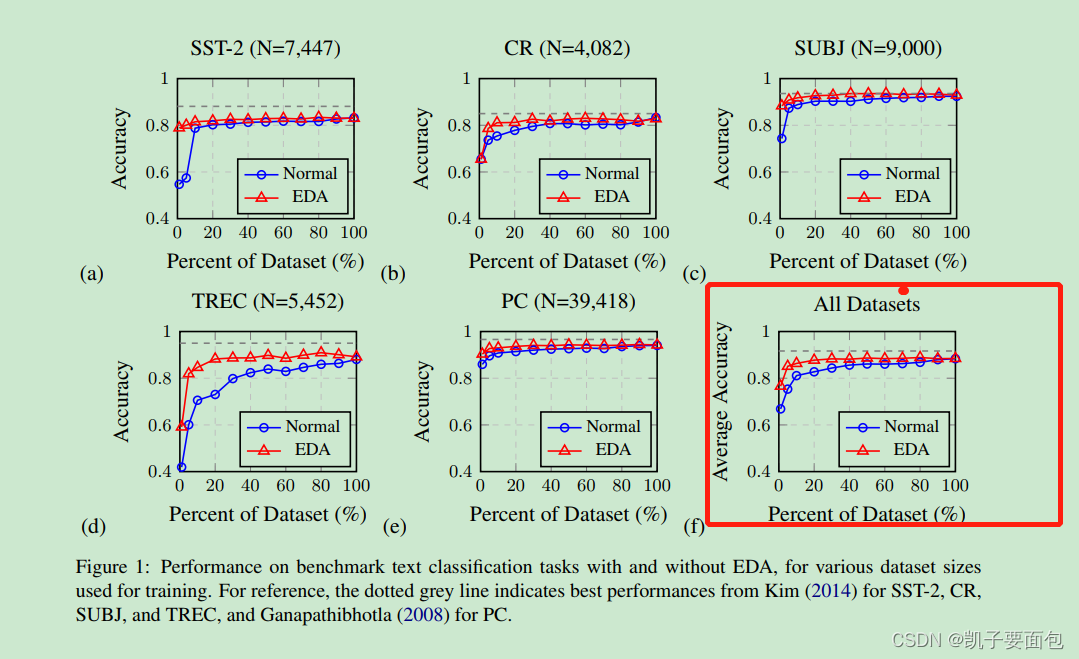
EDA在使用50%数据量的情况下,超越了未使用EDA时,模型的最优表现。

为了探究EDA是否改变了序列的标签信息,作者使用训练集训练RNN,然后用EDA增强测试集,将原始测试集与增强的测试集一起输入到RNN,得到原始测试集的序列向量表征,与增强序列的向量表征,将高维向量映射到二维平面,发现增强的向量仅仅围绕着原始向量表征,表示“采用EDA保留了标签信息”。
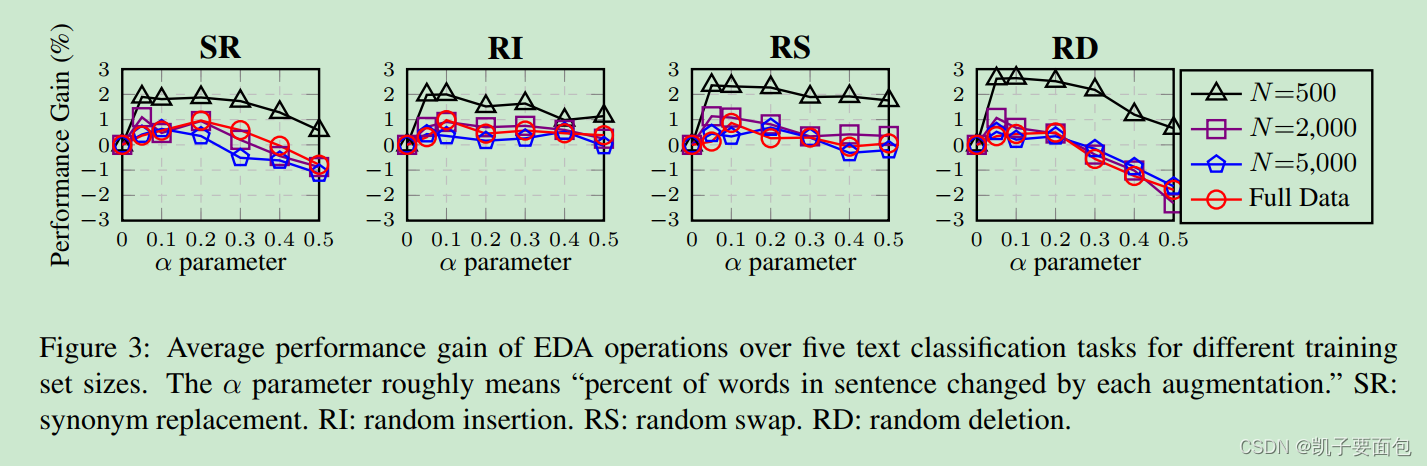
为了探究提出的四种方法分别的效果,作者在不同样本量、
α
\alpha
α条件下进行分解实验,结果表明
α
=
0.1
\alpha=0.1
α=0.1 时,四种方法都有一定的提升。
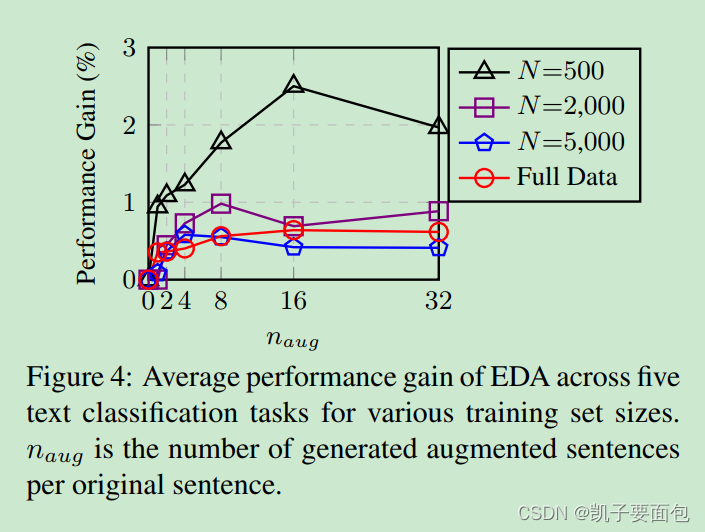
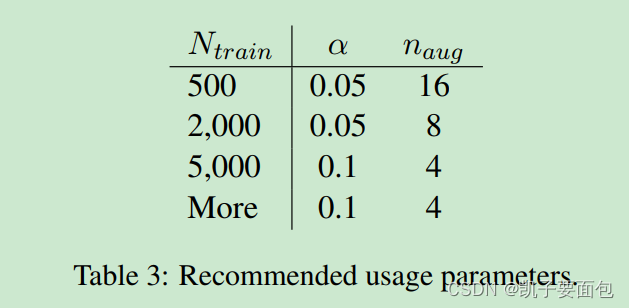
为了探究每一训练样本究竟增强几条样本,作者进行了上述实验,结果给出如下建议:

















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









