







模型
ChineseBERT 与 BERT 非常相似,只是在 Embedding 层上,前者对每个输入单元还添加了“字形”、“拼音”信息。由于中文是象形文字,因此字形中也包含了一定的语音信息,而加入拼音信息主要是为了解决一字多音——不同的发音包含不同的语义信息, 模型整体结构如下所示:
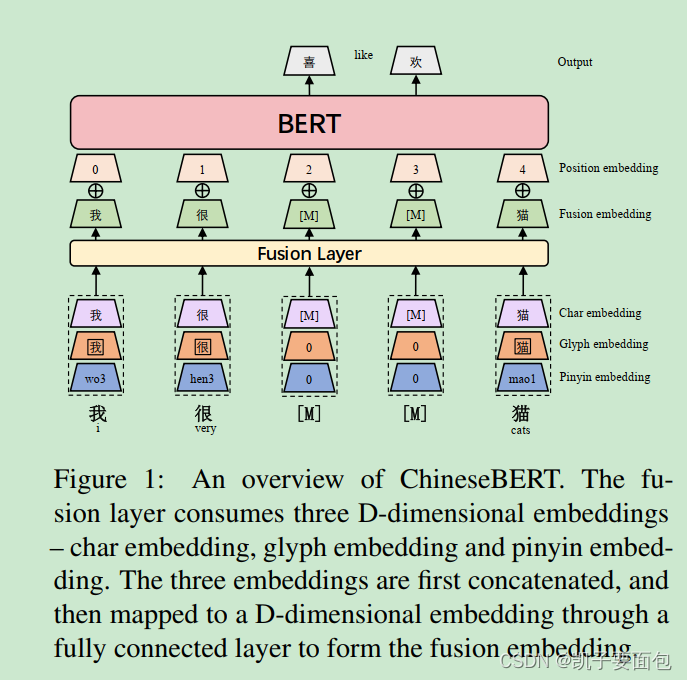
每个token的 Char embedding、Glyph embedding、 Pinyin embedding 会先进行 concatenate操作,然后经过全连接映射,最后与 Position embedding相加输入到BERT Encoder。
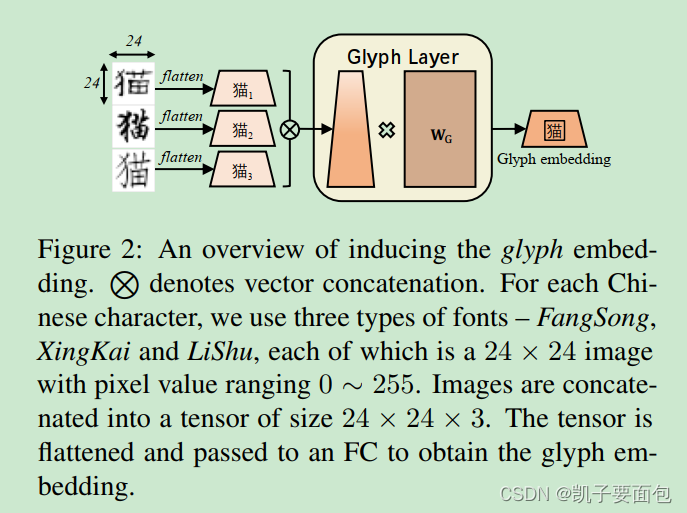
为了获取token的字形信息,论文中使用对应token的“仿宋、楷体、隶书”三种字体2424的照片信息,照片信息会组装成2424*3的数组,然后经过维度映射,转换成最终Glyph embedding。
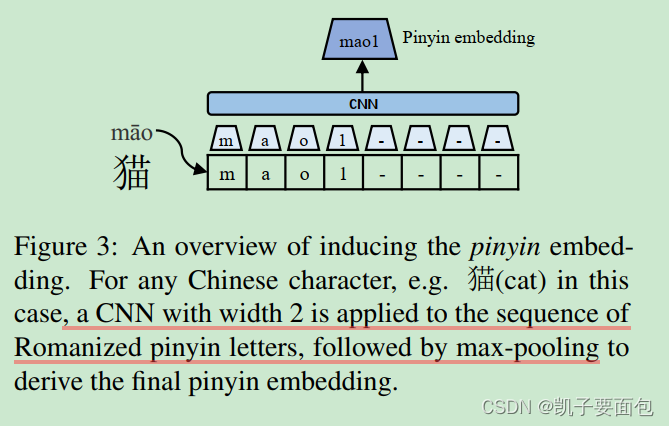
在计算 Pinyin embedding 时,使用开源库 pypinyin 获取中文序列的拼音,尾部的特殊字符表示音调,使用CNN 与 Max Pooling 抽取特征。
预训练配置
从 Common Crawl 清洗出 10亿的中文字符训练语料,使用 LTP toolkits 工具分词——Whole Word Mask 策略时需要。在遮掩语言模型中, 90%采用Whole Word Mask 策略, 10% 的情况下采用单字遮掩策略。
实验结果
分类实验对比结果显示, ChineseBERT 比 BERT效果略有提升。
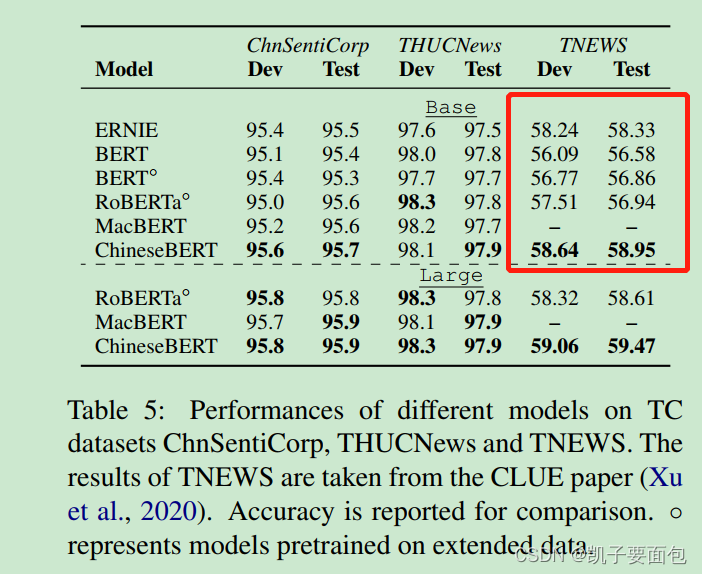
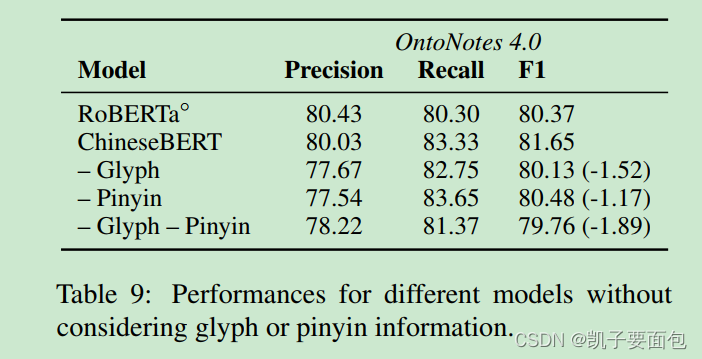
在OntoNotes数据集上,分解实验表明字形信息、拼音信息均有助于效果提升,第三行表示无字形信息,第四行表示无拼音信息、第五行表示无字形无拼音信息,注意第五行的模型效果不及RoBEATa,是因为模型训练步长、训练数据量更小。















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









