






适用范围:追星女(男)要爬爱豆话题页微博、小白学习爬虫等。
使用方法:复制全部代码至PyCharm,只需要修改cookie和话题。可以将cookie理解为你自己的通行证,修改话题就是你想爬取内容。代码我放在文中最后。
另外感谢一下大佬的文章:https://blog.csdn.net/m0_72947390/article/details/132832280
99%的内容参考的大佬文章代码,我简单表述一点,方便各位小白使用。
使用流程:
一、修改cookie
step1:浏览器登录微博、进入下图所示界面,右击点检查
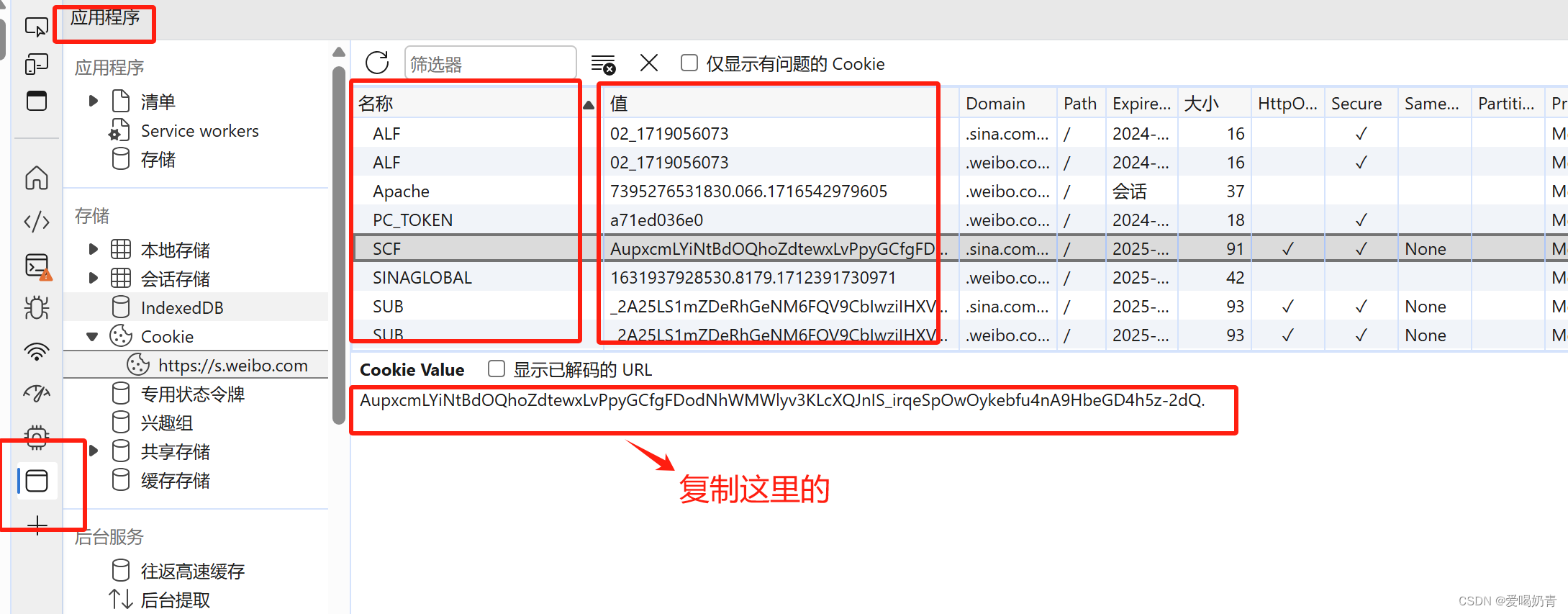
step2:点击检查后出现如下图所示界面,找到应用程序→cookie,找到这里的内容后,返回PyCharm中对代码中对应的内容进行修改。
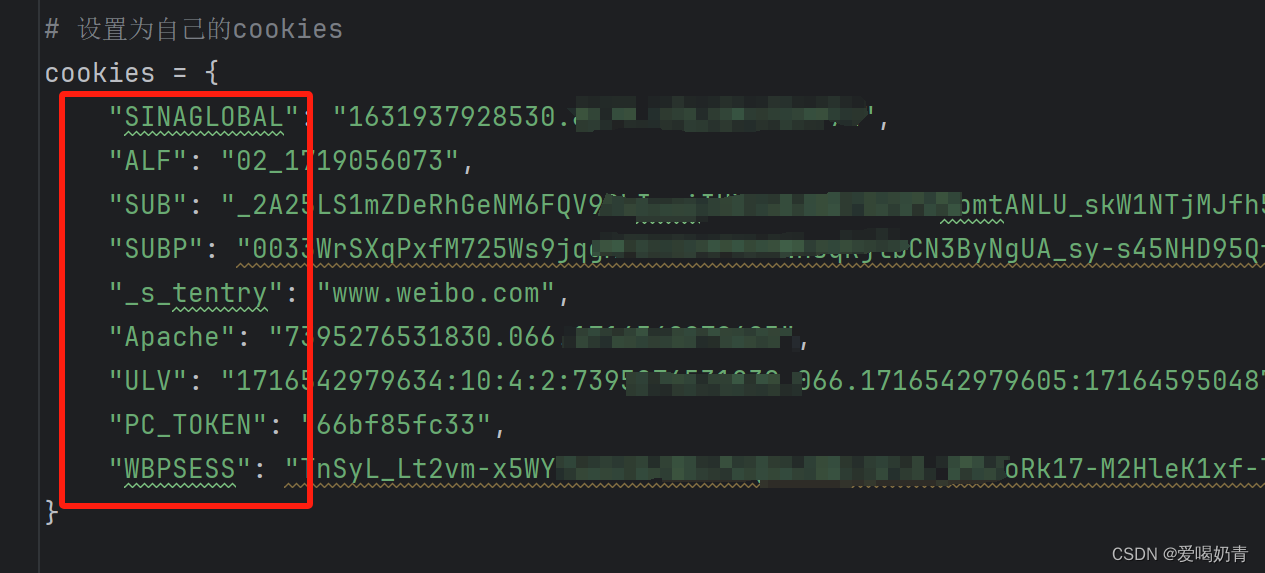
step3:在浏览器中点击要对应的字母,复制下面出现的数值,在代码中粘贴替换。cookie内容有很多个,每个都替换成你自己的。
二、修改话题
找到代码中的主函数,如下图所示部分。将q中的话题内容改为自己想要爬取的话题即可。如果要在这里修改the_type的类型,记得在上面get_the_list_response函数中也要修改。另外,要爬取的页数也可以自己修改,修改参数p就可以。
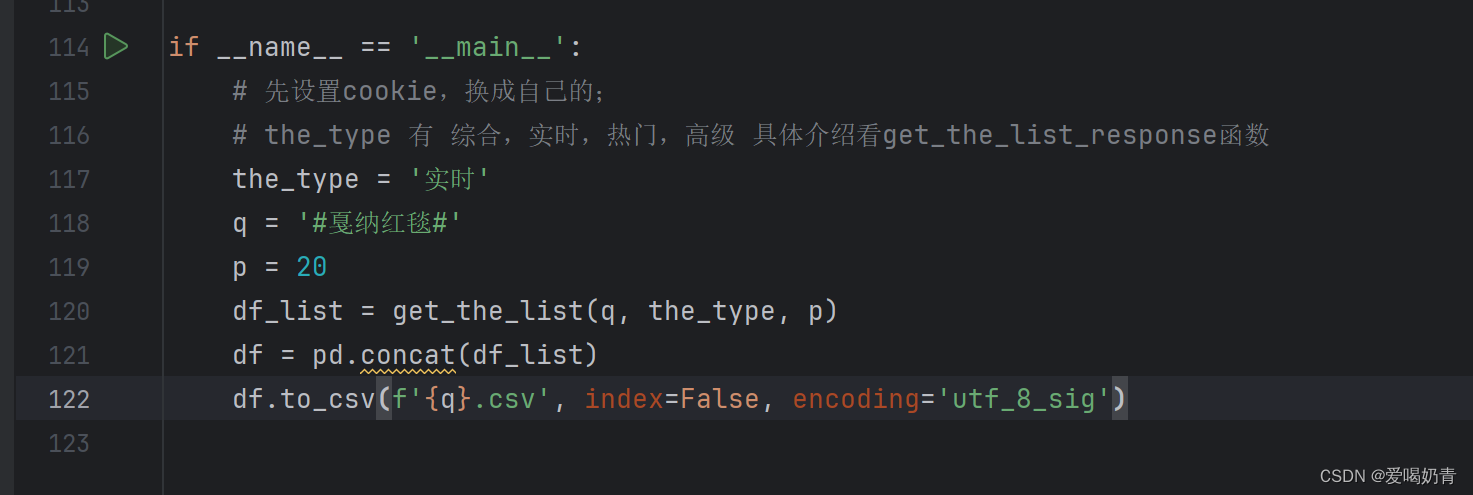
一定要主函数和def函数中的类型一致,否则爬不出来。

然后就可以右击run了,希望大家都能爬取成功,追星愉快。
代码内容:
import os
from bs4 import BeautifulSoup
import pandas as pd
import json
from urllib import parse
# 设置为自己的cookies
cookies = {
"SINAGLOBAL": "1631937928530.8179.1712391730971",
"ALF": "02_1719056073",
"SUB": "_2A25LS1mZDeRhGeNM6FQV9CbIwziIHXVoKdNRrDV8PUNbmtANLU_skW1NTjMJfh5QOHRU6PJKEImVwHTygofxdwaN",
"SUBP": "0033WrSXqPxfM725Ws9jqgMF55529P9D9WhsqRjlbCN3ByNgUA_sy-s45NHD95QfeoecShBRShnXWs4Dqc_zi--fiK.XiK.7i--Xi-zRiKy2i--RiKyFi-2ci--NiKLWiKnXi--Ni-z0iK.ci--ciK.Ri-8si--NiK.XiKLhi--NiKLWiKnX",
"_s_tentry": "www.weibo.com",
"Apache": "7395276531830.066.1716542979605",
"ULV": "1716542979634:10:4:2:7395276531830.066.1716542979605:1716459504876",
"PC_TOKEN": "66bf85fc33",
"WBPSESS": "TnSyL_Lt2vm-x5WYYkobC6cWXsfoQU4zBRyjViI-jMSZoRk17-M2HleK1xf-TxkNg8lBftZLn1psO_0fZ_9Lxm7GzKbpFx3nM8I9hOk3T378Qr-t28LxWirg7-SAHr1NRK17uNiG8SQs6yU463Ph-Q=="
}
def get_the_list_response(q='话题', the_type='实时', p='页码', timescope="2024-03-01-0:2024-03-27-16"):
"""
q表示的是话题,type表示的是类别,有:综合,实时,热门,高级,p表示的页码,timescope表示高级的时间,不用高级无需带入
"""
type_params_url = {
'综合': [{"q": q, "Refer": "weibo_weibo", "page": p, }, 'https://s.weibo.com/weibo'],
'实时': [{"q": q, "rd": "realtime", "tw": "realtime", "Refer": "realtime_realtime", "page": p, },
'https://s.weibo.com/realtime'],
'热门': [{"q": q, "xsort": "hot", "suball": "1", "tw": "hotweibo", "Refer": "realtime_hot", "page": p},
'https://s.weibo.com/hot'],
# 高级中的xsort删除后就是普通的排序
'高级': [{"q": q, "xsort": "hot", "suball": "1", "timescope": f"custom:{timescope}", "Refer": "g", "page": p},
'https://s.weibo.com/weibo']
}
params, url = type_params_url[the_type]
headers = {
'authority': 's.weibo.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'referer': url + "?" + parse.urlencode(params).replace(f'&page={params["page"]}',
f'&page={int(params["page"]) - 1}'),
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
}
response = requests.get(url, params=params, cookies=cookies, headers=headers)
return response
def parse_the_list(text):
"""该函数就是解析网页主题内容的"""
soup = BeautifulSoup(text)
divs = soup.select('div[action-type="feed_list_item"]')
lst = []
for div in divs:
mid = div.get('mid')
uid = div.select('div.card-feed > div.avator > a')
if uid:
uid = uid[0].get('href').replace('.com/', '?').split('?')[1]
else:
uid = None
time = div.select('div.card-feed > div.content > div.from > a:first-of-type')
if time:
time = time[0].string.strip()
else:
time = None
p = div.select('div.card-feed > div.content > p:last-of-type')
if p:
p = p[0].strings
content = '\n'.join([para.replace('\u200b', '').strip() for para in list(p)]).replace('收起\nd', '').strip()
else:
content = None
star = div.select('div.card-act > ul > li:nth-child(3) > a > button > span.woo-like-count')
if star:
star = list(star[0].strings)[0]
else:
star = None
comments = div.select('div.card-act > ul > li:nth-child(2) > a')
if comments:
comments = list(comments[0].strings)[0]
else:
comments = None
retweets = div.select('div.card-act > ul > li:nth-child(1) > a')
if retweets:
retweets = list(retweets[0].strings)[1]
else:
retweets = None
lst.append((mid, uid, content, retweets, comments, star, time))
df = pd.DataFrame(lst, columns=['mid', 'uid', 'content', 'retweets', 'comments', 'star', 'time'])
return df
def get_the_list(q, the_type, p):
df_list = []
for i in range(1, p + 1):
response = get_the_list_response(q=q, the_type=the_type, p=i)
if response.status_code == 200:
df = parse_the_list(response.text)
df_list.append(df)
print(f'第{i}页解析成功!', flush=True)
return df_list
if __name__ == '__main__':
# 先设置cookie,换成自己的;
# the_type 有 综合,实时,热门,高级 具体介绍看get_the_list_response函数
the_type = '实时'
q = '#戛纳红毯#'
p = 20
df_list = get_the_list(q, the_type, p)
df = pd.concat(df_list)
df.to_csv(f'{q}.csv', index=False, encoding='utf_8_sig')

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









