






十七、C++数组
C++数组就是表示一堆相同类型变量组成的集合。
1、数组的安全检查
如果我们像exampl[-1]这样去使用了不属于这个数组的空间,在debug模式下会得到一个程序崩溃的错误消息。然而在release模式下可能不会得到报错信息,这意味着我们已经写入了不属于我们的内存。因此我们需要设置安全检查,确保总是在数组的边界内写东西。
- 数组一个很重要的点是存储的数据是连续的。
- 数组实际上只是一个指针。
2、堆上创建数组
我们还可以在堆上(heap)创建一个数组,通过new关键字来创建一个数组,[]内是数组大小,然后创建一个新的数组another,类型是int*。
#include<iostream>
zai
int main()
{
int example[5]; //在栈上创建
int* another = new int[5]; //在堆上创建
delete[] another;//释放
std::cin.get();
}
这两行代码是一个意思,但是生存期不同。
- int example[5],是在栈上创建,当我们到达最后一行的花括号时,它会被销毁,因为跳出了作用域范围。
- another是在堆上创建,直到程序把它销毁之前都是处于活动状态,需要用delete关键字来删除。因为使用了数组的操作符[]来分配内存,我们还需要使用[]来删除它。
- 用new分配的内存将一直存在直到删除它。
3、堆上创建数组的间接寻址
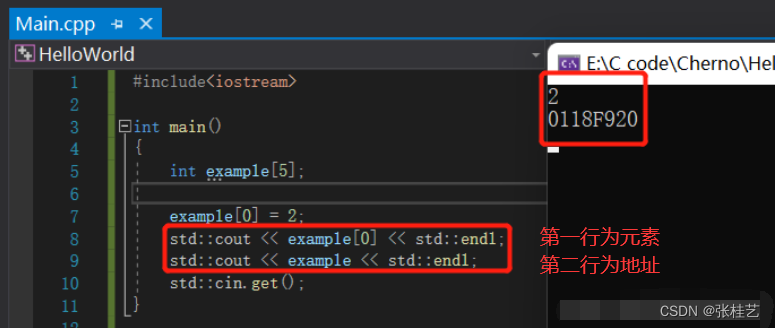
如果我创建一个名为Entity的类,然后将example数组移动到这里,再创建一个构造函数,用for循环语句初始化数组值为2,创建Entity对象e。
#include<iostream>
class Entity
{
public:
int example[5];
Entity()
{
for (int i = 0;i < 5;i++)
example[i] = 2;
}
};
int main()
{
Entity e;
std::cin.get();
}
运行该程序,如果我们到Entity对象e的内存地址,即在内存视图地址中输入&e并按回车键,可以看到Entity的内存地址上就是一行2。
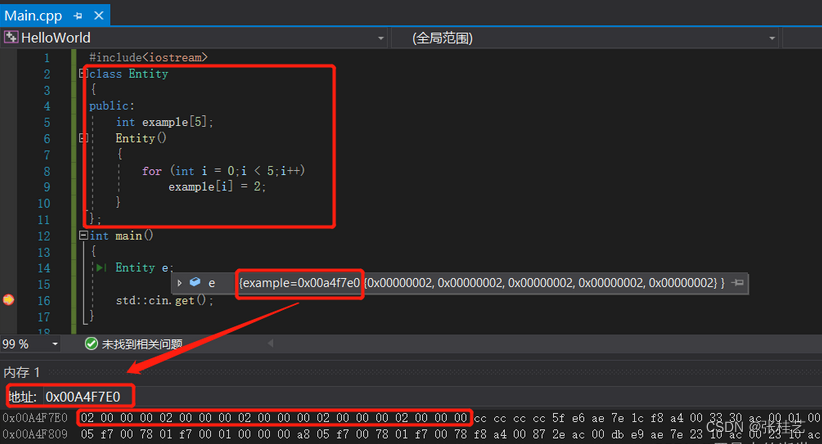 如果我们使用new关键字在堆上创建,运行完全相同的代码。再次进入内存地址,发现根本没有2,而是另一个内存地址。
如果我们使用new关键字在堆上创建,运行完全相同的代码。再次进入内存地址,发现根本没有2,而是另一个内存地址。
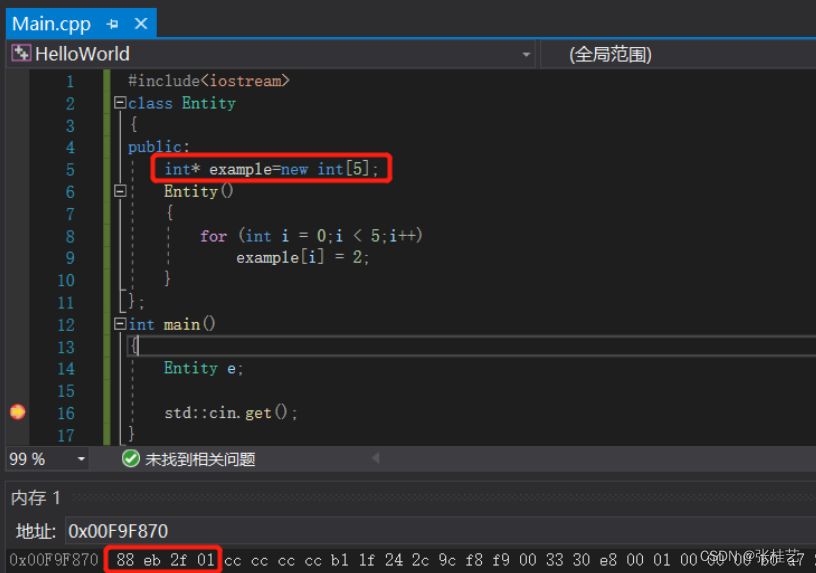 复制这个内存地址放到内存视图的地址中,但是要把它倒过来(小端法),0x012feb88,按下回车键。会得到一行为2的数据,这就是所谓的间接寻址。
复制这个内存地址放到内存视图的地址中,但是要把它倒过来(小端法),0x012feb88,按下回车键。会得到一行为2的数据,这就是所谓的间接寻址。
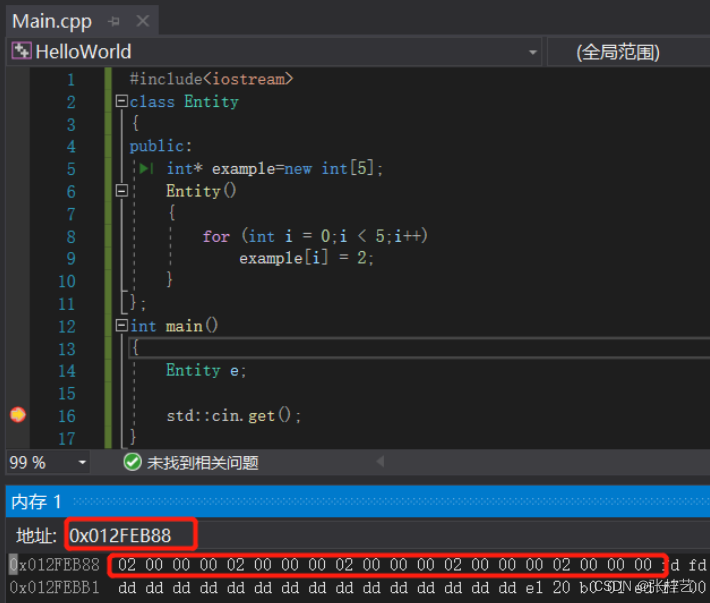
我们实际得到的e的内存地址包含的另一个地址0x012feb88,这才是我们数组的实际内存地址。所以应该在栈上创建数组来避免这种情况,因为这样在内存中跳跃肯定会影响性能。
4、C++11的数组
在C++11中我们有标准数组std::array,这是一个内置数据结构在C++11库中。它有很多优点,例如边界检查,记录数组大小(原始数组无法计算大小,无法使用example.size())
std::array<int,5>another;//another.size()大小为5
十八、C++字符串
在C++中有一种数据类型叫做char,它是一个字节的内存。字符串实际上是字符数组,我们通常将字符串称为const char*。加上const是为了不改变这些值,因为无法扩展字符串使其变大。char*并不意味着它是在堆上分配的,不能通过调用delete来删除。
1、字符串在内存中的样子
#include<iostream>
int main()
{
const char* name = "Cherno";
std::cin.get();
}
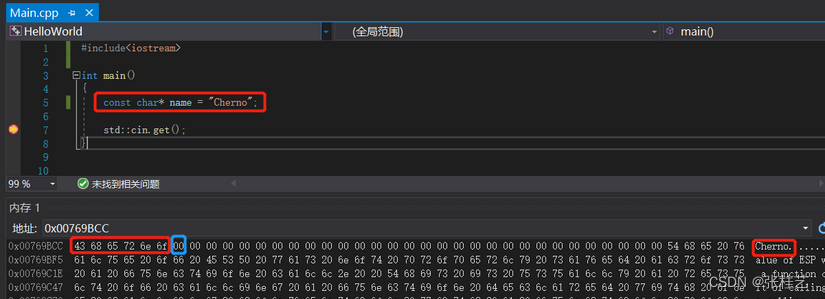
在第6行设置断点,运行程序就可以看到name的内存情况。在内存视图的地址栏中输入name,按下回车键。我们可以在内存视图的右边看到Cherno这个词,说明左边数字代表的是ASCII值。第7个字节被设为0,这被称为空终止字符,空终止字符是为了判断字符串的size。字符串从指针的内存地址开始,直到碰到0为止。
2、字符数组
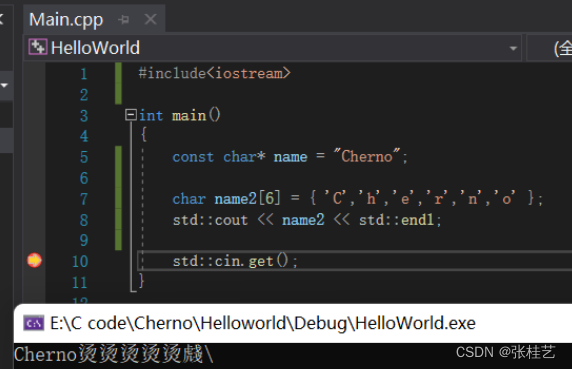
若我们创建的是包含字符的数组name2,这里没有空终止符,然后打印name2到控制台,会发现得到了Cherno,但是后面接了一大堆随机的字符。
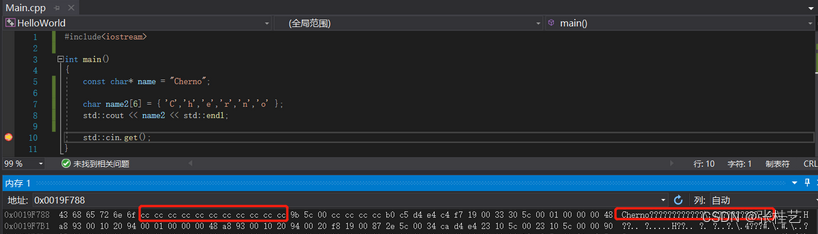
查看name2的内存视图,我们可以看到Cherno,然后接着一堆奇怪的符号。此时内存设置为cc,这实际上是一个数组守卫,让我们知道内存是在我们的分配之外。原因是name2的数组里面没有0,std::cout就不知道打印到哪儿结束。
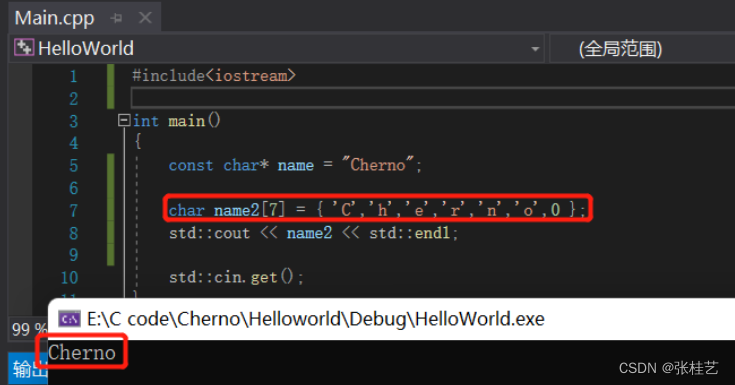
若我们修改数组的大小,并在末尾写上0,就能正确的打印Cherno。
3、std::string
在C++的标准库中有一个名为string的类,实际上有一个模板类叫BasicString。在c++中使用字符串应该使用std::string,它只是一个char数组和一些操作这些数组的函数。
std::string name="Cherno";
string有一个构造函数,它接收char或const char参数,把鼠标悬停会发现实际上是一个const char数组而不是char数组。为什么通常把字符串赋值给const char* 而不是char*,因为本质上用双引号定义字符串时,在C++中是const char数组而不是char数组,这是通过char* 的隐式转换。
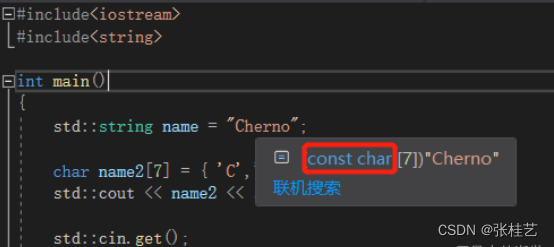
4、追加字符串
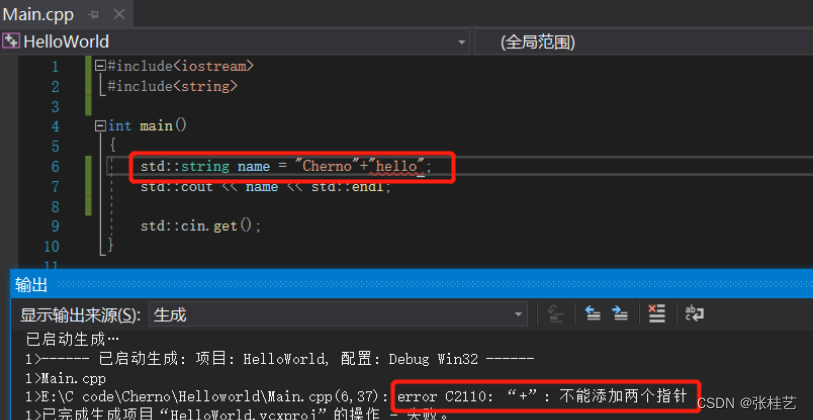
若想在Cherno后面加上hello,这里可能会出错。因为我们是想把两个const char类型的数组相加,双引号里的东西是const char数组而不是真正的字符串,不能把两个指针相加,不能将两个数组直接相加。
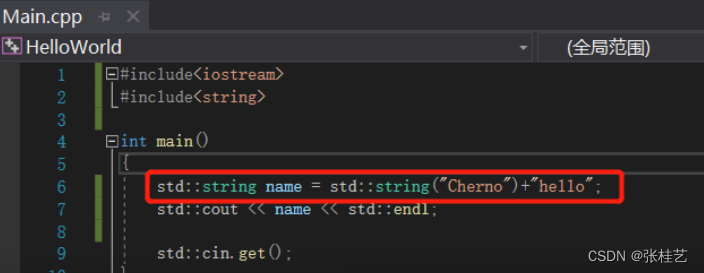
若想做这样的事,我们可以把它分成多行,这样做是将一个指针加到了name,name是一个字符串,把它加到字符串上,+=这个操作符在string类中被重载了。

或者将两个相加的字符数组中的一个,显示的调用一个string构造函数,相当于创建一个字符串,然后附加这个字符数组给它。
5、字符串作为参数传递
如果我们写了一个叫PrintString的函数想要传递一个字符串,不会简单的写std::string string然后打印string。
void PrintString(std::string string)
{
std::cout << string << std::endl;
}
因为这实际上是一个副本,如果这样把类(对象)传递给一个函数,实际上是在复制这个类(对象)。在函数中对这个类(对象)进行的操作不会传递到原始的类(对象)中。
void PrintString(const std::string& string)
{
std::cout << string << std::endl;
}
可以通过常量引用来传递,在前面加上const和引用&。&告诉我们是一个引用,意味着它不会被复制,而const承诺我们不会修改它(string)。
十九、C++字符串字面量
字符串字面量就是双引号balabala,比如"hbh";
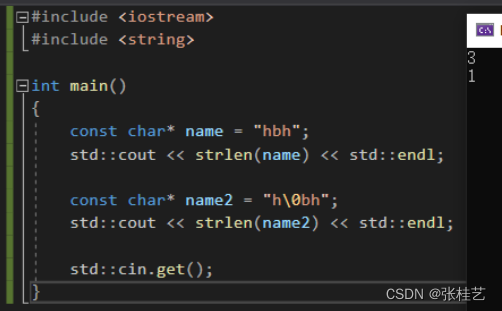
而像下图这样操作,虽然有的编译器不会报错,但是这是C++未定义行为,有的编译器会完全禁止,不好。像我的连 char* name = “hbh”; 都会报错(vs2019,C++17标准)。
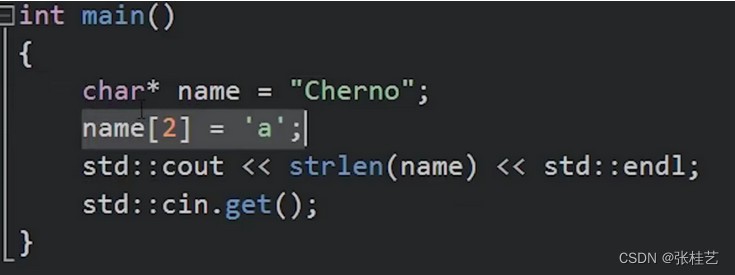
C++中还有别的一些字符串:
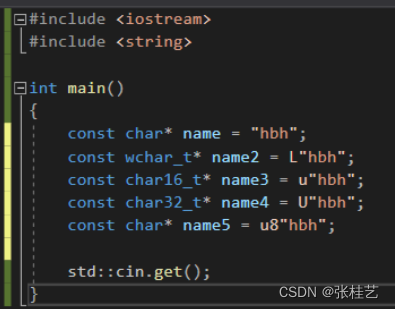
const char* name = "hbh";//char是一个字节的字符
const wchar_t* name2 = L"hbh";//wchar_t也是两个字节
const char16_t* name3 = u"hbh";//char16_t是两个字节的16个比特的字符(utf16)
const char32_t* name4 = U"hbh";//char32_t是32比特4字节的字符(utf32)
const char* name5 = u8"hbh";//const char就是utf8
wchar_t也是两个字节和char16_t的区别是什么呢?
事实上宽字符的大小,实际上是由编译器决定的,可能是一个字节也可能是两个字节也可能是4个字节,实际应用中通常不是2个就是4个(Windows是2个字节,Linux是4个字节),所以这是一个变动的值。如果要两个字节就用char16_t,它总是16个比特的。
在C++14中我们还能这样搞:
#include <iostream>
#include <string>
int main()
{
using namespace std::string_literals;
std::string name0 = "hbh"s + " hello";
std::cin.get();
}
string_literals中定义了很多方便的东西,这里字符串字面量末尾加s,可以看到实际上是一个操作符函数,它返回标准字符串对象(std::string);然后我们就还能方便地这样写等等:
std::wstring name0 = L"hbh"s + L" hello";
原始字符串字面量
C++11提供了原始字符串字面量的写法,可以在一个字符串前面加‘R’来修饰这个字符串,同时要把原始字符串用括号括起来。
std::string str = "C:\\FILE\\path"//传统写法
std::string str = R"(C:\FILE\path)"//C++11定义的新写法
新写法避免了大量的转义符。
- 字符串字面量永远保存在内存的只读区域。
char *p = “hello”; // p是一个指针,直接指向常量区,修改p【0】就是修改常量区的内容,这是不允许的。
char p[] = “hello”; // 编译器在栈上创建一个字符串p,把hello从常量区复制到p,修改p【0】就相当于修改数组元素一样,是可以的。















 1493
1493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









