







1 实验目的
使用Pytorch平台搭建循环神经网络用于Char文本生成。
2 实验内容
使用Pytorch搭建循环神经网络,训练模型之后,模型根据训练结果自动实现Char文本生成。
3 实验步骤
数据准备: 我们选择了一个文本数据集作为输入,将文本数据预处理为字符级别。这可以是一本小说、一组诗歌或任何连续文本的数据集。我们将文本数据转换为字符序列,将每个字符映射为一个数字表示。
模型设计: 我们使用PyTorch搭建了一个循环神经网络模型,常用的循环神经网络模型包括基本的RNN、长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)。我们根据实际情况选择合适的循环神经网络模型。
模型训练与文本生成: 我们使用训练集的文本数据来训练模型。在每个时间步,模型接收一个字符作为输入,并生成下一个字符的概率分布。通过最大似然估计和反向传播算法,我们训练模型的权重参数。在训练完成后,我们可以使用模型生成文本,方法是将生成的字符作为输入,再根据模型的输出继续生成下一个字符,从而生成连续的文本。
4实验代码


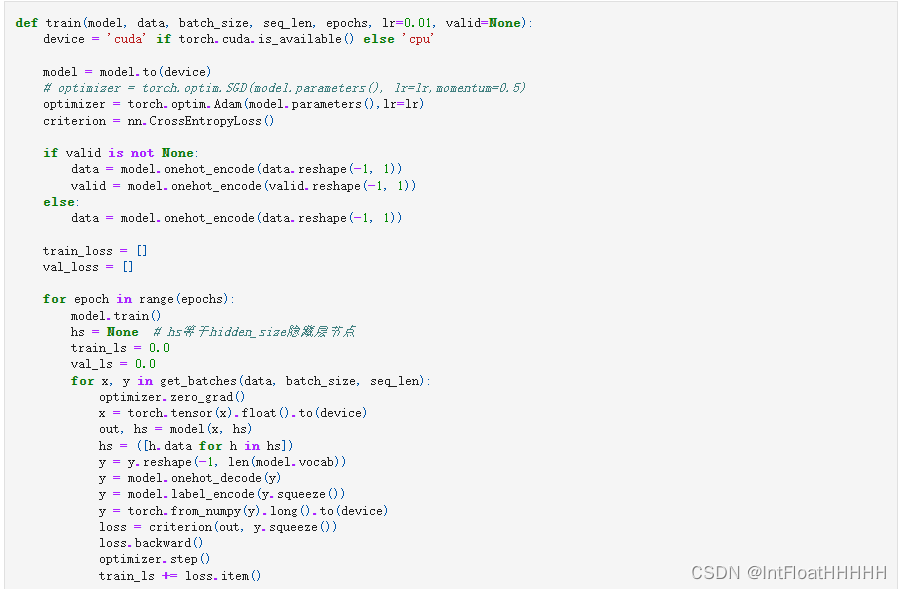
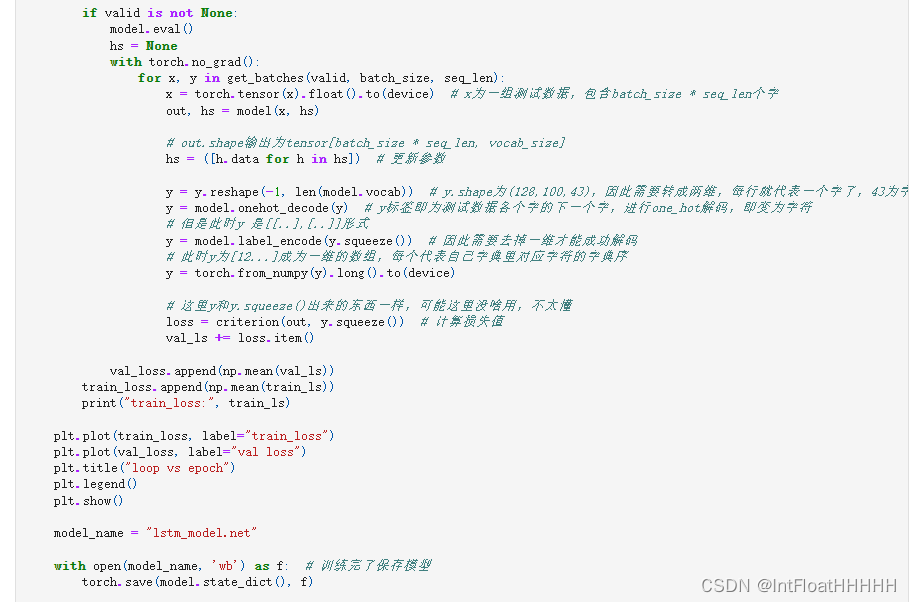


5 总结
循环神经网络是一种适用于序列数据的强大模型。它们能够捕捉到序列中的时间依赖关系,并具有记忆和预测的能力,适用于字符级别的文本生成任务。
模型的性能受多个因素影响,包括网络的深度和宽度、激活函数的选择、优化器的选择等。通过实验和调整这些参数,我们可以改善模型的性能和生成结果的质量。
数据集的选择和预处理对模型的训练和生成结果至关重要。选择具有多样性和丰富性的文本数据集可以提高生成结果的多样性和创造性。同时,对文本数据进行适当的预处理(如标准化、分词、去除噪声等)可以提高模型的学习效果。
训练模型需要适当的迭代次数和合适的学习率。过少的迭代次数可能导致模型未能充分学习文本的特征,而过多的迭代次数可能导致模型过拟合。合适的学习率可以避免模型训练过程中的梯度爆炸或梯度消失问题。
文本生成的结果可能会受到模型的训练数据和模型结构的限制。如果训练数据较少或模型较简单,生成的文本可能会有重复、不连贯或不合理的问题。可以通过增加训练数据量、调整模型结构或引入其他技术(如温度参数、束搜索等)来改进生成结果的质量。
总的来说,通过使用PyTorch搭建循环神经网络模型并进行文本生成实验,我们深入理解了循环神经网络的原理和应用,并学会了使用训练好的模型生成具有一定创造性的文本。这个实验为我们在自然语言处理领域的应用提供了基础,并启发我们进一步探索更复杂的文本生成任务和模型优化方法。然而,需要注意的是,生成的文本质量可能会受到多个因素的影响,包括模型的训练数据、模型的结构和超参数的选择等,因此在实际应用中需要进行合适的调整和优化,以达到更好的生成效果。















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









