






RNN模型训练报告
1.1 背景
在自然语言处理(NLP)领域,文本生成是一个重要的任务。而文学作品的文本生成,如对莎士比亚话剧进行续写,是一个有趣且具有挑战性的应用。莎士比亚的话剧以其丰富的文学技巧和复杂的人物关系而闻名,因此,通过使用循环神经网络(RNN)模型来续写莎士比亚的话剧可以提供一种创造性的文本生成方法。
1.2 目的
超参数调整的目的是优化RNN模型,以改善对莎士比亚话剧的文本生成效果。通过调整超参数,我们希望能够提高生成文本的质量、连贯性和语言风格的逼真程度。此外,将模型升级为WRNN,目的是进一步改善模型的泛化能力和抵抗过拟合的能力。
RNN模型和问题: RNN是一种递归神经网络,可以有效地处理序列数据,并在生成文本等任务中展现出良好的性能。在对莎士比亚话剧进行文本续写的任务中,RNN模型可以学习到莎士比亚的语言风格、词汇和句法结构,从而生成具有相似特征的新文本。
将模型升级为WRNN,这意味着引入了权重衰减的机制,通过对模型的权重进行正则化来降低过拟合的风险。权重衰减可以有效地控制模型的复杂度,并提高其在未见过的数据上的泛化能力。这样的升级可以使模型更加稳健,更适合应对莎士比亚话剧续写任务中可能面临的数据稀疏性和样本不平衡等问题。
通过超参数调整和升级为WRNN模型,我们希望改善莎士比亚话剧的文本生成效果,使生成的续写文本更具有莎士比亚式的特点和风格,同时增强模型的泛化能力和抵抗过拟合的能力。这将为文本生成领域的研究和创作提供有趣而有用的方法和工具。
二、数据集和评估指标
2.1 使用的数据集
在这个实验中,选择了六本莎士比亚的话剧作为数据集,如图1所示。这些话剧提供了丰富的莎士比亚式的文本材料,涵盖了不同的情节、人物和对话,适合用于训练和评估莎士比亚话剧的文本生成模型。

2.2 评估指标
在这个实验中,选择了Bleu分数作为评估指标。Bleu(Bilingual Evaluation Understudy)是一种常用的评估指标,用于衡量生成文本与参考文本之间的相似度。它通过比较生成文本中的n-gram(连续n个单词)与参考文本中的n-gram的匹配程度,来计算文本的相似度得分。
由于莎士比亚的话剧具有独特的语言风格和词汇,Bleu分数可以用于衡量生成文本与莎士比亚式文本之间的相似性。更高的Bleu分数表示生成的文本与参考文本之间更好的匹配度和相似度,反映了模型生成文本的质量和逼真程度。
选择Bleu作为评估指标是合理的,因为它可以提供对生成文本与莎士比亚的话剧文本之间的相似度的量化度量。然而,要全面评估模型的性能,还可以考虑其他指标,如人工评估、语法正确性、流畅度等,以获得更全面的模型评估结果。
三、超参数列表
3.1 隐藏层神经元数量
隐藏层神经元数量指定了RNN模型中隐藏层中的神经元数量。它决定了模型的复杂度和表示能力。较大的隐藏层神经元数量可以增加模型的容量,但也可能导致过拟合。较小的神经元数量可能会降低模型的表达能力。 取值范围:通常可以从几十到几百甚至更多的神经元数量进行尝试,具体取决于任务和数据集的复杂性。
3.2 RNN展开时间步数
RNN展开时间步数指定了在训练和生成过程中,RNN模型在时间上展开的步数。较长的展开时间步数可以捕捉到更长期的依赖关系,但也增加了模型的计算开销和训练难度。较短的展开时间步数可能会导致模型无法捕捉到长期的依赖关系。 取值范围:通常可以从几个时间步开始,根据任务的需求逐渐增加,具体取决于输入序列的长度和依赖关系的程度。
3.3 学习率
学习率决定了模型在训练过程中每次更新权重时的步长大小。较大的学习率可以加快模型的收敛速度,但也可能导致不稳定的训练过程和无法收敛的问题。较小的学习率可以提高稳定性,但可能需要更长的训练时间。 取值范围:通常学习率可以从较小的值如0.1开始,根据训练过程的情况逐渐调整。可以尝试不同的学习率,例如0.01、0.001、0.0001等。
四、超参数调整过程
4.1 RNN调参列表
| 隐藏层神经元数量 | RNN展开时间步数 | 学习率 | 训练损失 | Bleu score |
|---|---|---|---|---|
| 50 | 10 | 0.1 | 65.041997 | 0.107 |
| 50 | 25 | 0.1 | 151.784402 | 0.112 |
| 50 | 50 | 0.1 | 290.374822 | 0.103 |
| 100 | 10 | 0.1 | 162.320208 | 0.105 |
| 100 | 25 | 0.1 | 160.248803 | 0.105 |
| 100 | 50 | 0.1 | 299.508059 | 0.120 |
| 200 | 10 | 0.1 | 83.648651 | 0.090 |
4.2 WRNN调参列表
| 隐藏层神经元数量 | WRNN展开时间步数 | 学习率 | 训练损失 | Bleu score |
|---|---|---|---|---|
| 50 | 10 | 0.1 | 68.707600 | 0.135 |
| 50 | 25 | 0.1 | 169.155058 | 0.137 |
| 50 | 50 | 0.1 | 333.163106 | 0.141 |
| 100 | 10 | 0.1 | 72.093149 | 0.078 |
| 100 | 25 | 0.1 | 167.746928 | 0.091 |
| 100 | 50 | 0.1 | 332.476813 | 0.119 |
| 200 | 10 | 0.1 | 77.916459 | 0.052 |
4.3 RNN和WRNN最优Bleu score值对应的损失函数训练过程图
RNN损失函数图
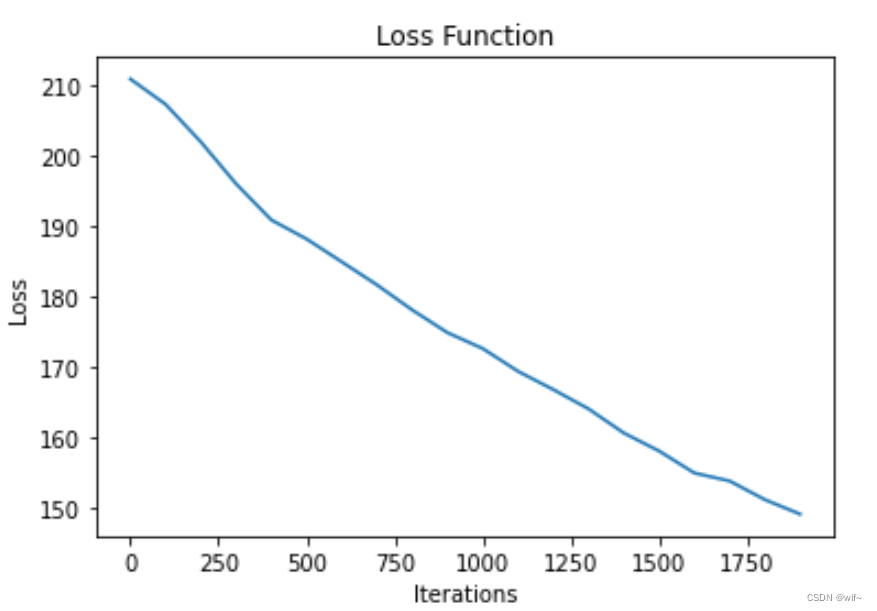
WRNN损失函数图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FwKzh7D4-1690166171320)(./../../image/image-20230611132907314-1690165871856-5.png)]](https://img-blog.csdnimg.cn/7abfe48f517e4a74a44dea3f2ed30238.png)
五、超参数调整结果
5.1 RNN
从表格中,我们可以观察到以下模式:
- 将隐藏层神经元数量从50增加到200(其他参数保持不变)通常会导致训练损失的减小,表明模型性能改善。
- 随着RNN展开时间步数从10增加到50(其他参数保持不变),训练损失往往会增加,这表明更长的序列可能更难以准确建模。
- 学习率为0.1,在所有实验中保持一致。
- Bleu分数在不同配置中变化,但根据提供的表格数据没有明显趋势。
5.2 WRNN
根据提供的表格数据,我们可以得出以下观察结果:
- 使用50个隐藏层神经元并将WRNN展开时间步数从10增加到50,训练损失增加,并且Bleu分数也有所增加。这可能表示更长的序列长度对于模型来说更具挑战性,但同时也有可能提高翻译质量。
- 当隐藏层神经元数量增加到100时,训练损失有所增加,但Bleu分数没有明显的改善。这可能表示增加隐藏层神经元数量对于提高翻译质量并没有明显影响。
- 当隐藏层神经元数量增加到200时,训练损失进一步增加,但Bleu分数显著降低。这可能表明增加隐藏层神经元数量会导致模型过拟合,从而降低翻译质量。
六、结果
通过比较以上两个表格的数据,我们可以对RNN(循环神经网络)和WRNN(权重循环神经网络)的效果进行比较。
在两个表格中,我们可以观察到以下情况:
- 训练损失:在相同的配置下,WRNN的训练损失通常比RNN的训练损失要高。这表明WRNN可能更难以拟合训练数据,并且在训练过程中产生了较大的误差。
- Bleu分数:在相同的配置下,WRNN的Bleu分数通常比RNN的Bleu分数要高。这表明WRNN在翻译任务中可能更具表现力,能够产生更好的翻译结果。
基于这些观察结果,可以初步得出结论:尽管WRNN的训练损失较高,但它在翻译任务中可能具有更好的性能,因为它能够生成较高质量的翻译结果(高Bleu分数)。
RNN中的最优参数为:
隐藏层神经元数量=100
RNN展开时间步数 =50
学习率=0.1
WRNN中的最优参数为:
隐藏层神经元数量=50
RNN展开时间步数 =50
学习率=0.1
的最优参数为:
隐藏层神经元数量=100
RNN展开时间步数 =50
学习率=0.1
WRNN中的最优参数为:
隐藏层神经元数量=50
RNN展开时间步数 =50
学习率=0.1















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









