







1 实验目的
熟悉循环神经网络的使用
2 实验内容
用Pytorch搭建循环神经网络,实现唐诗生成任务
3 实验步骤
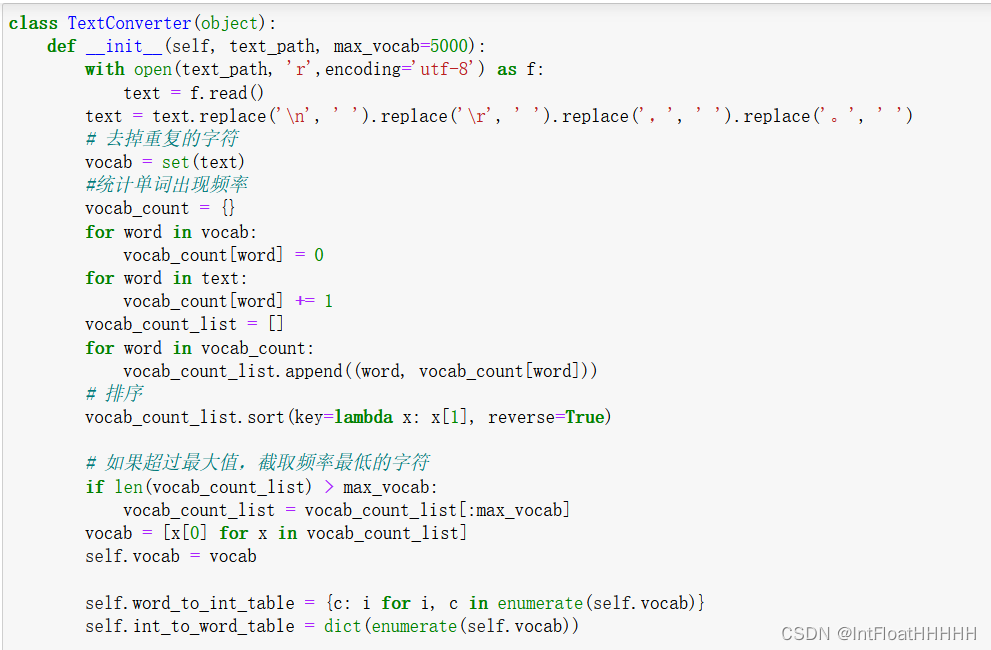
数据准备: 准备一个包含大量唐诗的数据集。可以从公开的唐诗数据集中获取,或者通过爬取网上的唐诗库来构建自己的数据集。将唐诗数据集转换为适合模型输入的格式,例如将每个句子拆分为字符序列或词语序列,并将其映射为数字表示。
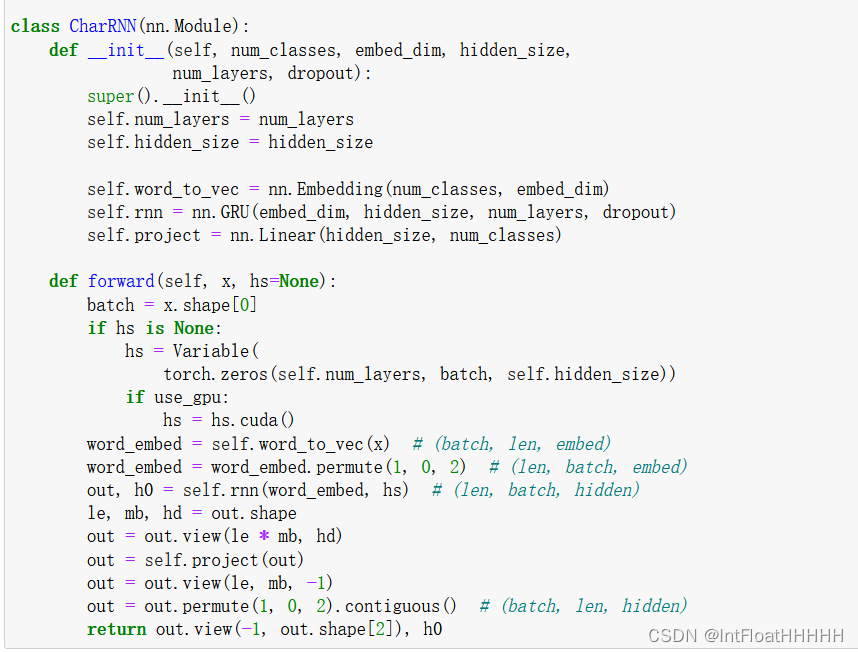
构建模型: 使用PyTorch构建循环神经网络模型。可以选择基本的RNN、LSTM或GRU作为循环单元,并根据任务需要选择合适的模型深度和宽度。模型的输入是前一时间步的字符或词语,输出是当前时间步的字符或词语。可以使用Embedding层将输入进行词嵌入表示。
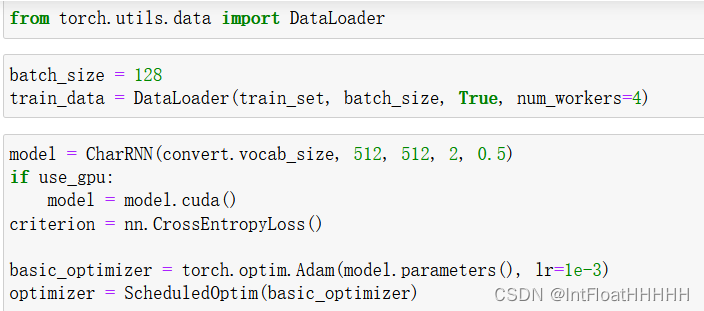
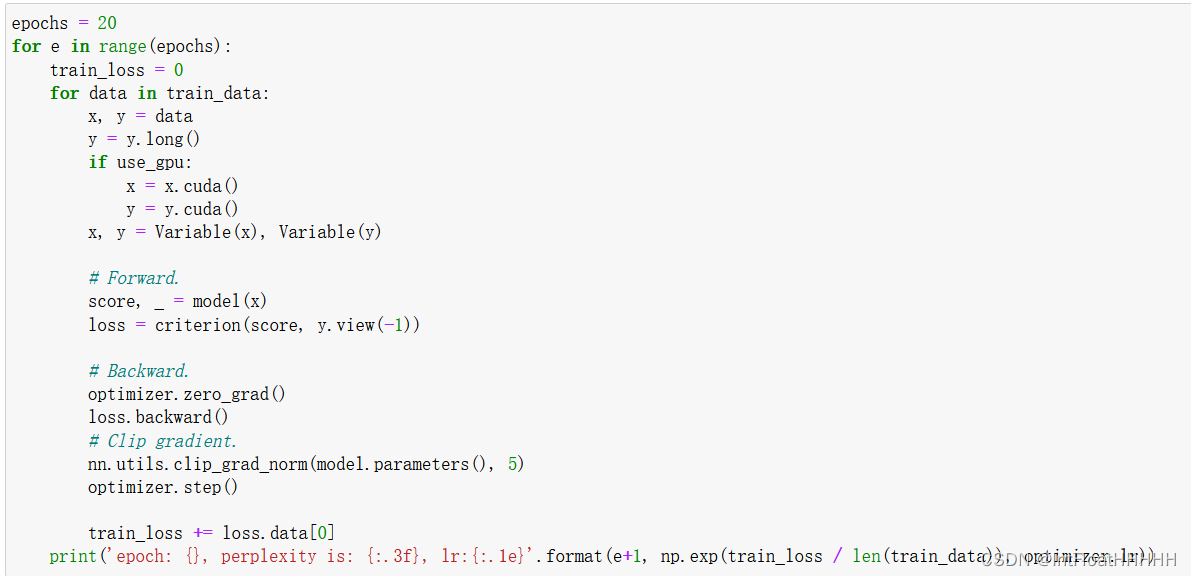
模型训练: 使用准备好的数据集对模型进行训练。定义损失函数,通常使用交叉熵损失函数。选择适当的优化器,如Adam或SGD,并设置合适的学习率。迭代训练模型,将输入序列喂入模型,并将模型输出与目标序列进行比较,通过反向传播算法更新模型的参数。
唐诗生成: 训练完成后,可以使用训练好的模型进行唐诗生成。给定一个初始的诗句或关键词作为输入,模型会根据之前的字符或词语生成下一个字符或词语。将生成的字符或词语与当前输入合并,然后再次输入模型进行下一个字符或词语的生成。重复该过程直到生成完整的唐诗。
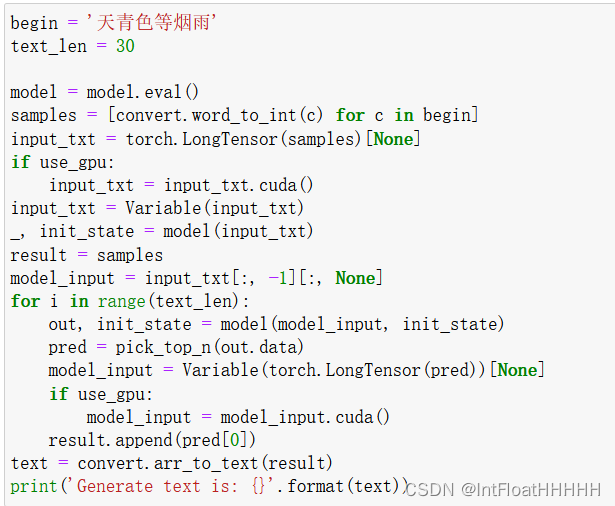
4.实验代码



5 总结
通过本实验,我们使用PyTorch搭建了一个循环神经网络模型,并完成了唐诗生成任务。以下是实验总结的要点:
循环神经网络在生成唐诗等序列数据任务中表现出较好的效果。它们可以捕捉到序列数据的上下文信息,并生成具有一定创造性的输出。
数据集的选择和预处理对模型的训练和生成结果至关重要。选择具有多样性和丰富性的唐诗数据集可以提高生成结果的多样性和质量。同时,对数据进行适当的预处理和特征工程可以提高模型的学习效果。
模型的选择和调优也对生成结果产生影响。选择合适的循环单元(如RNN、LSTM或GRU)和模型结构,调整模型的深度和宽度可以进一步调优模型的超参数,如学习率、隐藏层大小、批次大小等,以提高生成结果的质量和多样性。
在唐诗生成过程中,可以采用不同的策略来增加生成文本的创造性和多样性。例如,可以引入温度参数来调节生成文本的概率分布,较高的温度值会增加随机性和多样性,而较低的温度值会使生成结果更加确定和保守。
在训练过程中,可以采用Teacher Forcing技术来加速模型的训练。Teacher Forcing是指在训练过程中,将真实的目标序列作为模型的输入,而不是使用模型自身的输出作为下一个时间步的输入。这有助于加速训练收敛,并提高生成结果的准确性。
总的来说,通过使用PyTorch搭建循环神经网络模型,并进行唐诗生成实验,我们深入了解了循环神经网络的原理和应用,并学会了使用训练好的模型生成具有一定创造性和多样性的唐诗。这个实验为我们在自然语言处理领域的应用提供了基础,并启发我们进一步探索更复杂的文本生成任务和模型优化方法。然而,需要注意的是,生成的唐诗质量可能会受到多个因素的影响,包括模型的训练数据、模型的结构和超参数的选择等,因此在实际应用中需要进行合适的调整和优化,以达到更好的生成效果。















 2357
2357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









