







几个月之前,DeepLearning.ai 创始人吴恩达与 OpenAI 开发者 Iza Fulford 联手推出了一门面向开发者的Prompt Engineering教程,不知道大家有没有看…我当时火速看了,但是一直没有来得及整理中文版…来补作业了…
这篇笔记以及之后关于这个系列的整理仅作为学习笔记使用,内容基本都来自于教程并加上自己的理解,有需要的朋友可以直接戳https://learn.deeplearning.ai/。
这篇笔记主要整理教程中Introduction和Guidelines for Prompting的部分。
目录
策略1:使用定界符(delimiters)(清晰地标示你的输入)
一、Introduction
在大型语言模型或LLM的开发过程中,通常有两种主要类型的LLM。
1. Base LLM:基于文本的训练数据来预测下一个单词,例如

再比如,如果我们输入的prompt是 “What is the capital of France?” Base LLM返回的消息很可能如下所示,这是因为网上的一些文章很可能列出了关于一些the country of France的quiz question

2. Instuction Tuned LLM: 这种模型是训练来遵循指令的,它们通过指令和good attempts进行微调。Instuction Tuned LLM通常的训练方法如下
- 使用大量的文本数据对base LLM进行训练
- 通过进一步训练来微调,输入输出是指令和对这些指令的good attempts。
- 接下来,通常会使用一种称为RLHF(reinforcement learning from human feedback)的技术进一步优化,使系统更具有帮助性和遵循指令的能力
在这个系列课程里,我们将专注于Instuction Tuned LLM的最佳实践,这是我们建议你在大多数应用中使用的方法。当你使用Instuction Tuned LLM时,可以将其视为向另一个人提供指令,比如一个聪明但不了解您任务具体细节的人。因此,当LLM无法正常工作时,有时是因为指令不够清晰。
这个教程的主要内容如下:
- 给出一些最佳的软件开发中的prompting技巧
- 列举一些常见的用例,包括总结、推断、转换和扩展
- 学习如何使用一个Large Language Model (LLM) 构建一个聊天机器人
二、Guidelines for Prompting
这个部分将提供一些写prompt的指南来让你使用模型获得想要的结果,这份指南包括两个关键原则: 编写清晰明确的指令(清晰≠简短)以及给模型足够的时间进行思考。
Principle 1: 编写清晰明确的指令
策略1:使用定界符(delimiters)(清晰地标示你的输入)
定界符可以是任何明确的标点符号,使用定界符这可以将prompt与你需要prompt处理的文本分开,避免prompt injections。
- prompt injections:如果向prompt中添加一些额外输入,这些额外的输入可能会包含一些与模型指令相冲突的指令,导致模型遵循额外输入的指令而不是你期望它执行的操作。
可以参考使用的定界符包括:
- 三个双引号:""text"""
- 三个反引号:‘’’text’’’
- 三个破折号:---text---
- 尖括号:<>
- XML标签:<tag> </tag>
参考示例:

策略2:要求结构化输出(HTML、JSON)
下图给出了使用json格式输出的示例
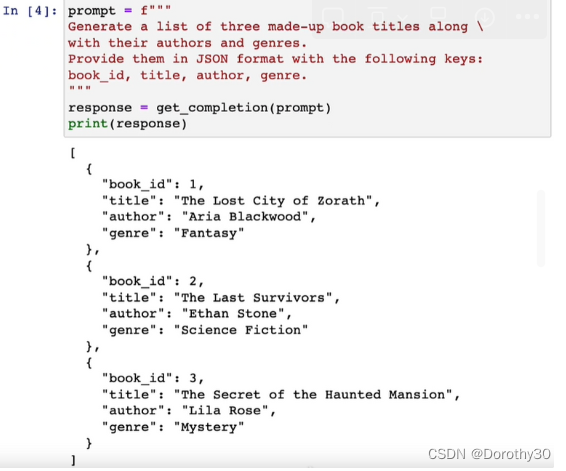
策略3:检查条件是否满足,以及检查执行任务所需的假设
如果你需要让ChatGPT完成的任务包含一些假设,而这些假设在它处理的文本中并不一定满足,我们可以告诉模型首先检查这些假设,如果不满足,指出假设不满足并在完整任务完成之前中止。你还可以考虑潜在的边界情况以及模型应该如何处理它们,避免意外的错误或结果。
以下为两个示例:
实例1:
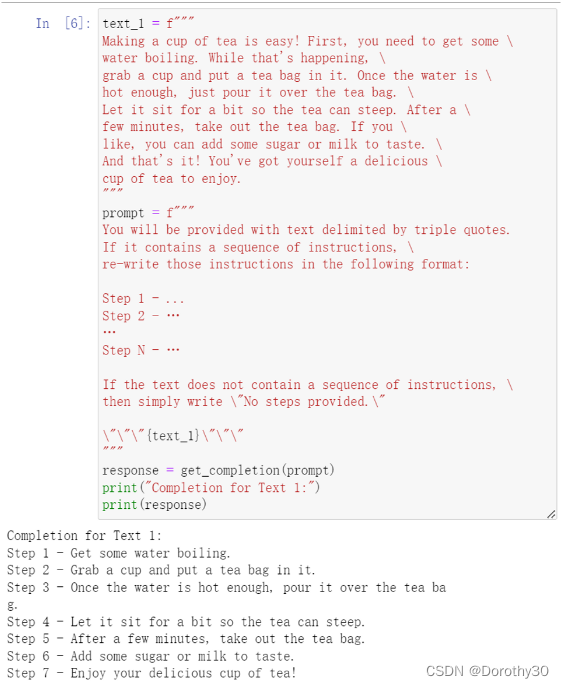
实例2:
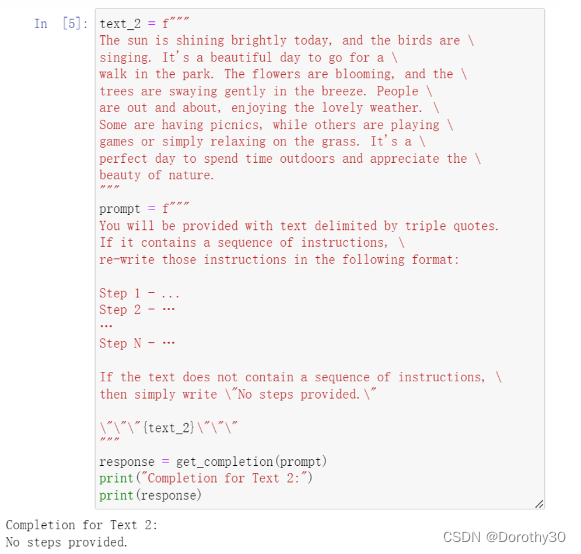
策略4:few-shot prompting
在prompt中,可以给出一些满足你要求的完成任务的示例输出,然后要求模型参考你给的示例来执行你给出的任务。

Principle 2: 给模型足够的时间进行思考
- 如果模型在匆忙得出错误结论时出现推理错误,你可以尝试重新组织你的prompt,要求模型在提供最终答案之前进行一系列相关推理。
- 另一种方式是,如果你给模型一个在短时间内或用少量词汇完成的任务过于复杂,它可能会猜测一个很可能是错误的答案。
策略1:明确指定完成任务的步骤
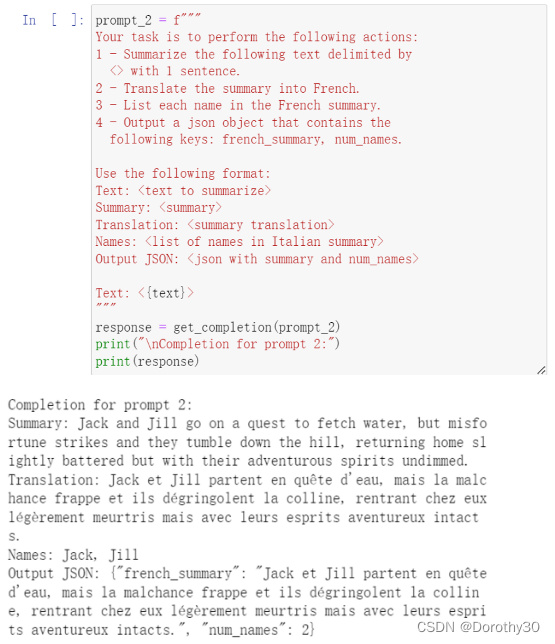
策略2:在匆忙得出结论之前,提示模型自行找出解决方案
有时候,当我们明确地提示模型在得出结论之前进行推理时,我们会获得更好的结果。这与我们之前讨论的给模型时间来思考问题然后再判断答案是否正确的想法是相同的,这个逻辑和人思考问题的方式也是类似的。
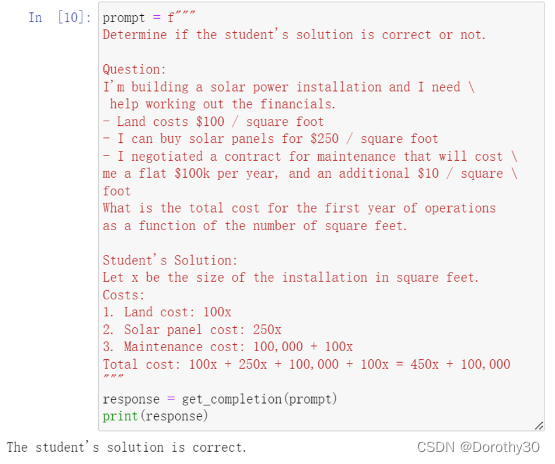
我们也可以通过提示模型先自行找出解决方案,然后将其解决方案与自己的解答进行比较、判断正误。
三、模型的局限性
如果模型在训练过程中接触到大量的知识,它并没有完全记住所见过的信息,因此对自身知识的边界了解不太清楚。
这意味着它可能会尝试回答问题,并且可能会编造听起来合理但实际上不正确的内容。我们将这些虚构的想法称为hallucinations。
因此,请确保在构建自己的prompt时使用之前介绍的一些技巧策略,以尽量避免出现这种情况。
一种可以尝试减少hallucinations的思路是:
- 首先找到与你问题有关的有用信息
- 让模型基于这些相关信息生成答案,要求它使用这些引用来回答问题,并且能够追溯答案的来源


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









