










在这篇笔记中,我们将使用社交媒体的数据进行Hawkes process的建模。我们将首先讨论为什么Hawkes process适合来进行推特转发级联的建模,以及如何构建记忆核函数
,然后我们将从推特数据中估计模型参数。最后使用带参数的模型来进行转发级联的规模估计(受欢迎程度)。
目录
1.1 事件的强度函数(intensity function)
1 一个信息传播的显著Hawkes process
我们将模拟一个网络信息的传播:用户分享内容,其他用户将内容进行分享并传播给更多用户的现象。在这个应用中,我们将每一次转发当做点过程上的一个事件。同时,我们也将对社交网络的三个特点进行建模:(1)影响力规模。被粉丝多的用户发出来的推特更容易被转发→影响力更大;(2)随着时间的推移记忆。当内容新鲜时,转发最多;(3)内容质量。
1.1 事件的强度函数(intensity function)
首先,一个转发级联定义为对一个原始推特的一系列转发的集合。这在点过程里面可以体现为分支结构里的immigrant event和它的后代。在之前的笔记中,我们提到在Hawkes process中的事件强度函数可以如下定义:
我们假设immigrant event的基础强度。由于要体现每个用户的影响力规模,我们将使用一个显著的Hawkes process(a marked Hawkes process)来进行建模。
我们定义每个mark/magnitude 为每个推特的用户影响力,在这篇笔记中我们将用户的关注者数量视作影响力。因此原始推特的事件发生时间为
,影响力为
。那么后续的推特表示在时间
到来的具有影响力
的事件。
我们构建一个包含mark m的power-law记忆核函数,如下所示:
:推特内容的病毒性/内容质量,用于缩放该条推特后续的转发率。
:推特用户在社交网络的影响力,这种影响力在社交网络上有一种扭曲效应(“warping effect”),在核函数中体现为用户的影响力会呈指数级别的影响推特的转发。
:体现为power-law的部分,主要是表征了一个事件被遗忘的速度,其中参数$c>0$是一个恒定的位移项,这是为了使得在
的时候
有界。
2 对Hawkes process进行参数估计
从前面的intensity function可以看到,我们需要用最大似然估计来估计的有四个参数。将前面的强度函数代入上一篇笔记的极大似然函数中可得:
该公式的具体推导见下图:

为了使得branching factor有意义且为正数,上述函数中的参数的限制为:,
,以及
。同时,为了使得最终得到的级联是有限的,我们在估计中也将
作为限制条件之一。
针对上一篇笔记中提到的在估计最大似然中可能会遇到的三个问题:边缘效应,计算复杂度和局部最小值。在当前应用场景下,(1)因为我们是观察一个immigrant事件产生的后代级联,所以不存在边缘效应;(2)本应用的计算复杂度为。但在代码实现中,使用了三个方法来使计算更为高效:向量化,保存需要重复使用的计算结果,在大量级联中进行数据并行执行。(3)使用多组随机初始值的设置来应对局部最小值的问题。
3 未来事件的期望数量
在数据收集的过程中,已知在截止的时间内观察到了一个转发的级联的一部分,并且已经拟合了参数。那么我们想要接著这个级联继续往下模拟,直到级联结束的话,我们也许想要估计在观察到n个事件之后,未来还要发生多少事件,我们的一个完整转发级联才结束。
那么首先基于观察到的n个事件,我们可以先模拟出基于当前已发生的事件估计出来的Hawkes process,可以产生的下一代事件。然后我们再计算当前Hawkes process的branching factor,最后再根据
的数量
和branching factor来计算所有未来后代事件的数量(也就是说我们先通过计算
进行最直接的一步预测,然后在n个事件之后出现未来后代的数量的计算是基于我的第一步预测的结果的,每个事件能够触发的新事件能力由branching factor决定)。
3.1 未来第一代的数量
因为我们关注的只是一个immigrant事件触发的转发级联,所以自然可以得出在不会再观察到immigrant事件了,因为后代的转发都是由当前事件触发的。那么对于
的第一代后代的计算,我们可以通过记忆核函数计算过去发生的所有事件的影响来得到。那么
的计算为:
3.2 Branching factor
在之前的笔记中我们提到过,branching factor是通过对历史事件的影响进行积分来计算的:
由于在我们的应用场景中,要考虑每个事件的影响力,因此我们也要对这种影响力m进行积分。在这里我们假设每个事件的影响力是服从社会影响的power-law分布的,即:
,其中
为控制分布长尾的参数,可以从实际数据中进行估计。那么此时的branching factor的计算为:
其中,
具体计算见下图:
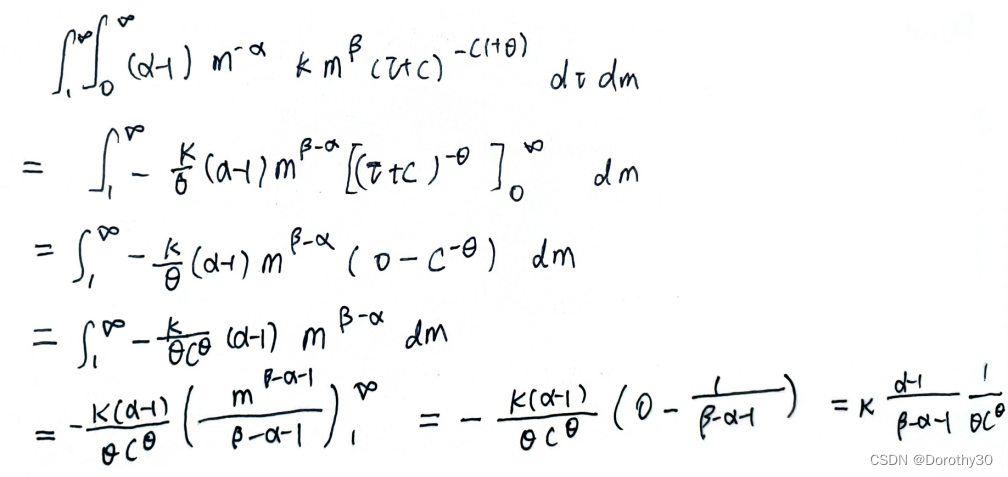
3.3 整个级联的规模(一个cluster里的总后代数)
在之前的笔记中,我们提到过,一个cluster中后代期望事件数量为:
当然在我们的应用中也可以这样进行计算,但就像前面提到的一样,有一个更为精确地估计是基于来进行后代数量的估计,因此我们有:
将之前得到的代入,我们可以进一步得到
4 实操教程
关于教程具体的数据和代码可以在作者提供的github地址上看:https://github.com/s-mishra/featuredriven-hawkes。这里面的所有代码是用R语言写的,所有代码实例使用既提供了power-law的版本,也提供了exponential的版本。在笔记中我我用python写了一遍,仅供参考。
-
首先可视化了power-law kernel的曲线,相关参数为
以及
。代码的python如下:
# Define initial event that starts the cascade (i.e., the immigrant) event = np.array([1000, 0]) # magnitude = 1000 at time t0 = 0 # Define the end point of time and the list of event times t_end = 100 t_list = np.linspace(event[1], t_end, num=1000) # Set the parameters needed for power_law_kernel kappa = 0.8 beta = 0.6 c = 10 theta = 0.8 alpha = 2.016 res = kernel_pl(event, t_list, kappa, alpha, beta, 1, c, theta, True) plt.plot(t_list, res, color='blue') plt.xlabel('Time') plt.ylabel('Intensity') plt.title('Power-law memory kernel over time') plt.show()
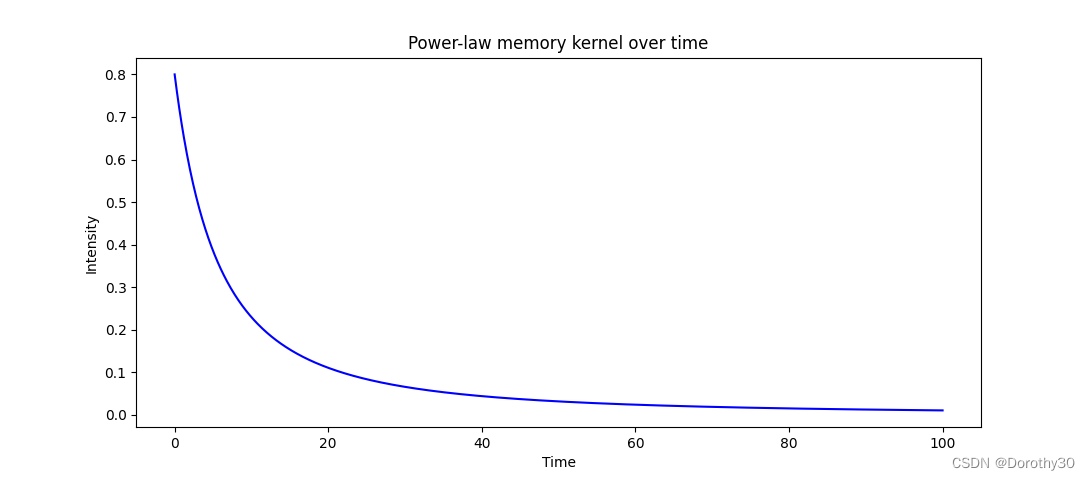
-
进一步地,我们可以用thinning算法的步骤模拟出一整个由初始移民事件生成的一整个后代cluster。初始事件发生的时间为
,模拟时间持续50个时间间隔。代码如下:
events = marked_hawkes.generate_Hawkes_event(kappa, alpha, beta, 1, c, theta, event[0], 50, True, 'List_1_2.txt', None, "power_law")
-
接下来,我们基于真实的Twitter传播级联来估计带有power-law kernel的Hawkes process的参数。代码包含了对CSV文件的读取和基于前600秒的事件来执行最大参数估计的部分:
real_cascade = pd.read_csv('example_book.csv') # Retain only the events that occurred in the first 600 seconds (10min), these will be used for fitting the model params predTime = 600 history = real_cascade[real_cascade['time'] <= predTime] # Remove the first column, which is event index history = history.iloc[:, [1, 2]] # Call the fitting function # Disable warning messages np.seterr(all='ignore') startParams = {'kappa': 1, 'beta': 1, 'c': 250, 'theta': 1} result = marked_hawkes.fitParameters(startParams, history, "power_law") print(f"result:{result}") print(f"result['x']:{result['x']}") -
最后,根据估计到的模型参数值,我们估计了整个传播级联的总规模
# Using the fitted model parameters, we call getTotalEvents to get predictions prediction = marked_hawkes.cal_total_events(history=history, bigT=predTime, kappa=result['x'][0], beta=result['x'][1], c=result['x'][2], theta=result['x'][3], kernel_type="power_law") print(prediction)
完整的代码已经上传到CSDN,审核通过后会更新到笔记里面~















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









