







利用Python中的statsmodels简单建立多元线性回归模型(一)
概念简单介绍
多元线性回归其实是在一元线性回归的基础上增加了若干个自变量个数,数学表达式如下:
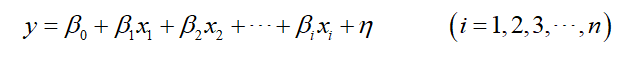
其中,
y
y
y是因变量(响应变量),
β
0
β_{0}
β0是截距项,
β
1
β_{1}
β1,
β
2
β_{2}
β2,
.
.
.
...
...,
β
i
β_{i}
βi是回归系数,
x
1
x_{1}
x1,
x
2
x_{2}
x2,
.
.
.
...
...,
x
i
x_{i}
xi为自变量,
η
η
η为随机误差项。
案例
本文采用scikit-learn中的加利福尼亚房屋价值数据。下面导入相关的库:
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing as fch #加载加利福尼亚房屋价值数据
#加载线性回归需要的模块和库
import statsmodels.api as sm #最小二乘
from statsmodels.formula.api import ols #加载ols模型
#设置全部行输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
导入数据
加利福尼亚房屋价值数据是scikit-learn中的经典数据集,因此导入数据时要进行整理,在运行
data=fch()
的时候需要自行下载,具体运行之后自行操作。
data=fch() #导入数据
house_data=pd.DataFrame(data.data) #将自变量转换成dataframe格式,便于查看
house_data.columns=data.feature_names #命名自变量
house_data.loc[:,"value"]=data.target #合并自变量,因变量数据
house_data.shape #查看数据量
house_data.head(10) #查看前10行数据

数据一共20640行,9列,8列自变量
分测试集和训练集
将70%的数据作为训练集,剩下的作为测试集,代码如下:
#分训练集测试集
import random
random.seed(123) #设立随机数种子
a=random.sample(range(len(house_data)),round(len(house_data)*0.3))
house_test=[]
for i in a:
house_test.append(house_data.iloc[i])
house_test=pd.DataFrame(house_test)
house_train=house_data.drop(a)
测试集的index是乱的,重新排序index
#重新排列index
for i in [house_test,house_train]:
i.index = range(i.shape[0])
house_test.head()
house_train.head()

训练模型
#训练模型
lm=ols('value~ MedInc + HouseAge + AveRooms + AveBedrms + Population + AveOccup + Latitude + Longitude',data=house_train).fit()
可以利用summary查看模型结果
lm.summary()


R方为0.607,比较低,根据结果可知,有一些不显著的变量。在下一篇中,将根据AIC准则建立向前逐步回归函数提出自变量。
接下来测试模型
#利用测试集测试模型
house_test.loc[:,"pread"]=lm.predict(house_test)
#计算R方
##计算残差平方和
error2=[]
for i in range(len(house_test)):
error2.append((house_test.pread[i]-house_test.loc[:,"value"][i])**2)
##计算总离差平方和
sst=[]
for i in range(len(house_test)):
sst.append((house_test.value[i]-np.mean(house_test.value))**2)
R2=1-np.sum(error2)/np.sum(sst)
print("R方为:",R2)
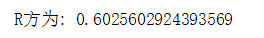
测试模型结果显示R方为0.60256,其实算是一个偏低一点的R方。
作预测效果图
#作预测效果图
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(range(len(house_test.pread)),sorted(house_test.value),c="black",label= "target_data")
plt.plot(range(len(house_test.pread)),sorted(house_test.pread),c="red",label = "Predict")
plt.legend()
plt.show()

可见,中间的部分有较好的拟合度,但是开头和结尾拟合误差太大了,所以R方较低。如果在图像右侧有更多的数据分布,那么模型的预测值就会越来越偏离真实的数据。
在下一篇文章中,将采用AIC准则建立向前逐步回归,筛选自变量!
参考文献
常国珍,赵仁乾,张秋剑.Python数据科学技术详解于商业实战[M]. 北京:中国人民大学出版社,2018.















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









