







1. 索引类型
B+树索引;可以通过索引字段的前缀进行查找。
全文索引
哈希索引
2. B+树索引
B+树索引找到的其实是page_id,然后把该页读到内存中,再在内存中查找。对于某一条具体记录的查询是通过对Page Directory进行二分查找得到的。
聚集索引要求按照Key顺序存储元素,因此每张表只能有一个聚集索引,一般为主键
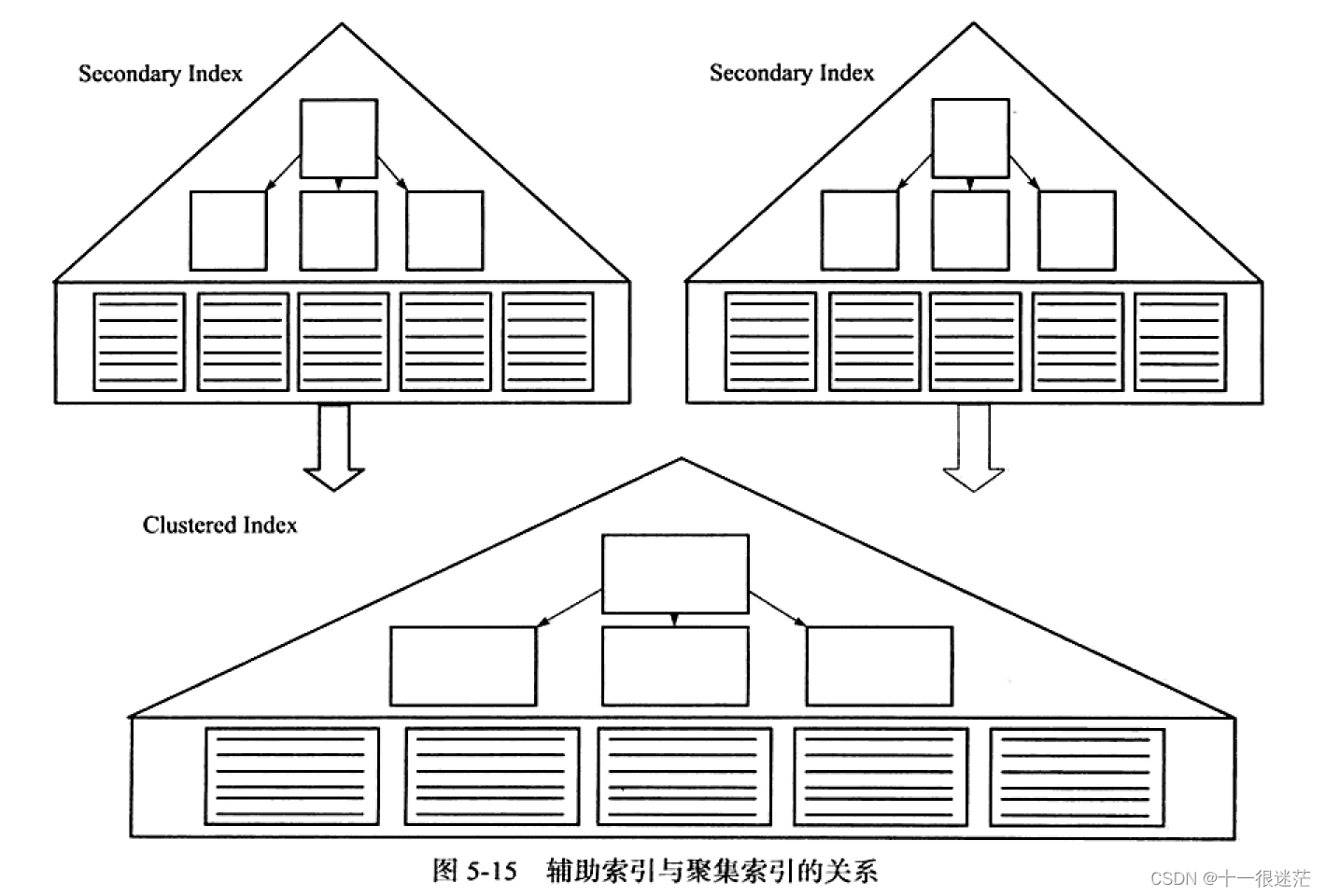
2.1 辅助索引(Secondary Index)
叶子节点包含了一个书签(bookmark),就是聚集索引键。
2.2 索引分裂
保存插入的顺序信息,来决策向左或向右分裂
PAGE_LAST_INSERT
PAGE_DIRECTION
PAGE_N_DIRECTION
(1)若插入是随机的,取页中间记录作为分裂点的记录
(2)若向一个方向连续插入5个记录(确保是递增插入,因为优化分裂会导致原page的分裂几率增加)
- 如果目前定位到的记录之后还有3条记录,则分裂点记录为定位到记录后的第三条记录;
- 否则,分裂点记录就是待插入的记录。
这里有个问题:如果按照上述分裂方式,那么在插入后删除,就会导致频繁的分裂和合并,应该是限定在插入的场景下使用。
这里还有个引申问题:https://www.cnblogs.com/mscm/p/13493129.html
2.3 索引Cardinality值
(1)Cardinality表示索引中唯一值的数目的估计值,非常关键。
非实时更新,即并非每次索引更新都会更新该值
实质上用来表示某个字段的取值范围,即选择性,Cardinality/n_rows_in_table应尽可能接近1。
(2)更新索引的Cardinality信息:
ANALYZE TABLE tbl_name;
下面这三个通过innodb_stats_on_metadata参数设置,默认为OFF;
SHOW TABLE STATUS;
SHOW INDEX;
访问INFORMATION_SCHEMA下的表TABLES和STATISTICS时;
(3)对Cardinality的统计都是通过采样方法来完成的
取得 B+ 树索引中的叶子节点数量,记为 A
随机取得 8 个叶子节点,统计每个页不同记录的个数
P
i
P_i
Pi
预估值为
∑
P
i
∗
A
/
8
\sum P_i*A/8
∑Pi∗A/8
(4)更新的策略
- 表中1/16的数据发送过变化
stat_modified_counter>2*10^9;某些行频繁变化,但表中数据实际没有增加。
2.4 Fast Index Creation 快速索引创建
只限于对辅助索引,对创建索引的表加S锁
对于主键的创建和删除需要重建表。
2.5 索引的使用
(1)联合索引:(a,b)
对于单个的a列查询仍然可以使用
a = xxx ORDER BY b;可以避免额外的排序
(2)覆盖索引
通过辅助索引即可获得想要的信息,一般是统计信息或主键信息。
(3)选择辅助索引的另一种情况:通过辅助索引查找的数据是少量的
可以使用FORCE INDEX(idx_name)来强制使用某个索引
(4)索引提示(INDEX HINT):显式告诉优化器使用哪个索引
适用于某个SQL语句可选择的索引非常多的情况
(5)Multi-Range Read(MRR)优化
将查询到的辅助索引得到的查询结果存放在一个缓存中,按照主键进行排序,再进行书签查找
可以将某些范围查询拆分成键值对,就是枚举范围中的值,类似在CMU P3实验中做的优化。
(6)Index Condition Pushdown(ICP)优化
一般是针对辅助索引
在索引取出的同时,判断是否可以进行WHERE条件的过滤,然后再去获取记录。
3. 哈希索引
哈希索引是自适应的,会根据表的使用情况自动为表生成哈希索引,不能人为干预。
3.1 InnoDB中的哈希算法
对缓存池页建立了哈希表。InnoDB解决冲突的方式采样链表方式。
哈希函数为: h ( k ) = k m o d m h(k) = k \mod m h(k)=kmodm, m m m的取值为略大于2倍的质数
表空间都有一个space_id,某个表空间下的某页offset,哈希值的计算为K = (space_id << 20) + space_id + offset;
3.2 自适应哈希索引
注意:只能用来搜索等值查询
4. 全文检索(Full-Text Search)
将某个记录中的任意内容信息查找出来的技术。
使用于 MATCH AGAINST 操作
4.1 倒排索引
通常利用关联数组实现,存放在辅助表(Auxiliary Table)中,两种表现形式:
inverted file index,{单词,list(单词所在文档的ID)};
full inverted index,{单词,list[(单词文档ID,在文档具体位置)]};
4.2 InnoDB 全文检索
(1)其采用了full inverted index的方式,辅助表中有两个列,一个是word字段,一个是ilist字段(DocumentID, Position),并且在word列设有索引;
(2)为了提高全文检索的并行性能,共有 6 个Auxiliary Table。存放在磁盘上
(3)FTS Index Cache(全文检索索引缓存)是一个红黑树结构,其根据(word,ilist)进行排序。
-
对全文索引的更新,会先插入到FTS Index Cache中。当对全文索引进行查询时,Auxiliary Table会先将在FTS Index Cache中对应的word字段合并到Auxiliary Table中,再进行查询。
-
总是在事务提交时将分词写入FTS Index Cache中,然后再通过批量更新写入磁盘
数据库关闭时,也会将FTS Index Cache同步到磁盘上的Auxiliary Table。
当缓存满时,会将其中的(word, ilist)分词信息同步到磁盘上的Auxiliary Table -
当数据库宕机时,缓存中的数据会丢失,重启数据库时,当用户对表进行全文检索时,InnoDB会自动读取未完成的文档,进行分词操作,再将分词结果放入到FTS Index Cache中。
-
表
fts_a(表明了FTS_DOC_ID与word的映射关系),根据该表创建倒排索引idx_fts;
(创建全文索引时,若没有FTS_DOC_ID列,InnoDB会自动创建,并添加唯一索引)
删除fts_a中的记录时,会将FTS_DOC_ID保存在information_schema.INNODB_FT_DELETED,即DELETED表中,
但并不会马上更新Auxiliary Table(即INNODB_FT_INDEX_TABLE表),通过OPTIMIZE TABLE命令才会在辅助表中将相应记录删除。 -
stopword列表中的word不需要进行索引分词操作
通过参数innodb_ft_server_stopword_table设置
4.3 全文检索的使用
MATCH (col1,xxx) AGAINST (‘想要搜索的word’ 搜索模式)
(1)NATURAL LANGUAGE是默认模式
在WHERE中使用MATCH,返回的查询结果是根据相关性进行降序排序。
查询的word在stopword列中,会忽略
查询的word字符长度是否在区间内,不在的话会忽略该词的搜索
(2)Boolean
+和-分别表示某个单词必须出现或一定不存在
@distance,查询的多个单词之间的距离是否在distance内(Proximity Search)
" " 视为短语(一个单词)
(3)Query Expansion
全文索引的扩展查询,需要implied knowledge时进行;分为两个阶段。
5. 索引
(1)MySQL只能高效使用索引的最左前缀列,因此如果索引包含多个列,列的顺序也十分重要。
索引对多个值排序的依据是定义索引时列的顺序。
(2)若存储引擎不支持哈希索引,仍可以创建伪哈希索引,例如:需要存储大量的URL,并需要根据URL进行搜索查找,如果直接作为B+树的Key那么存储的内容就会很大,可以采用哈希值作为Key(CRC32),建立B+树进行查找。
需要在查询的SELECT子句中手动指定哈希函数。
5.1 高性能的索引策略
(1)独立的列,索引的列不能是表达式的一部分。
(2)前缀索引。前缀的选择性应该接近于完整列的选择性。
需要使用 count(distinct) 查看不同前缀长度的区分度,再选取前缀长度
MySQL无法使用前缀索引做ORDER BY和GROUP BY,也无法做覆盖扫描
后缀索引,可以把字符串反转后存储
可以使用哈希字段
(3)需要考虑特殊用户,某些条件值的基数会比正常值高,例如:guset用户,需要进行特殊处理。
(4)InnoDB中随机插入最好使用OPTIMIZE TABLE命令做优化
InnoDB中二级索引存储主键值,而非指向实际存储的指针,这种策略减少了当出现行移动或者数据页分裂时二级索引的维护工作。
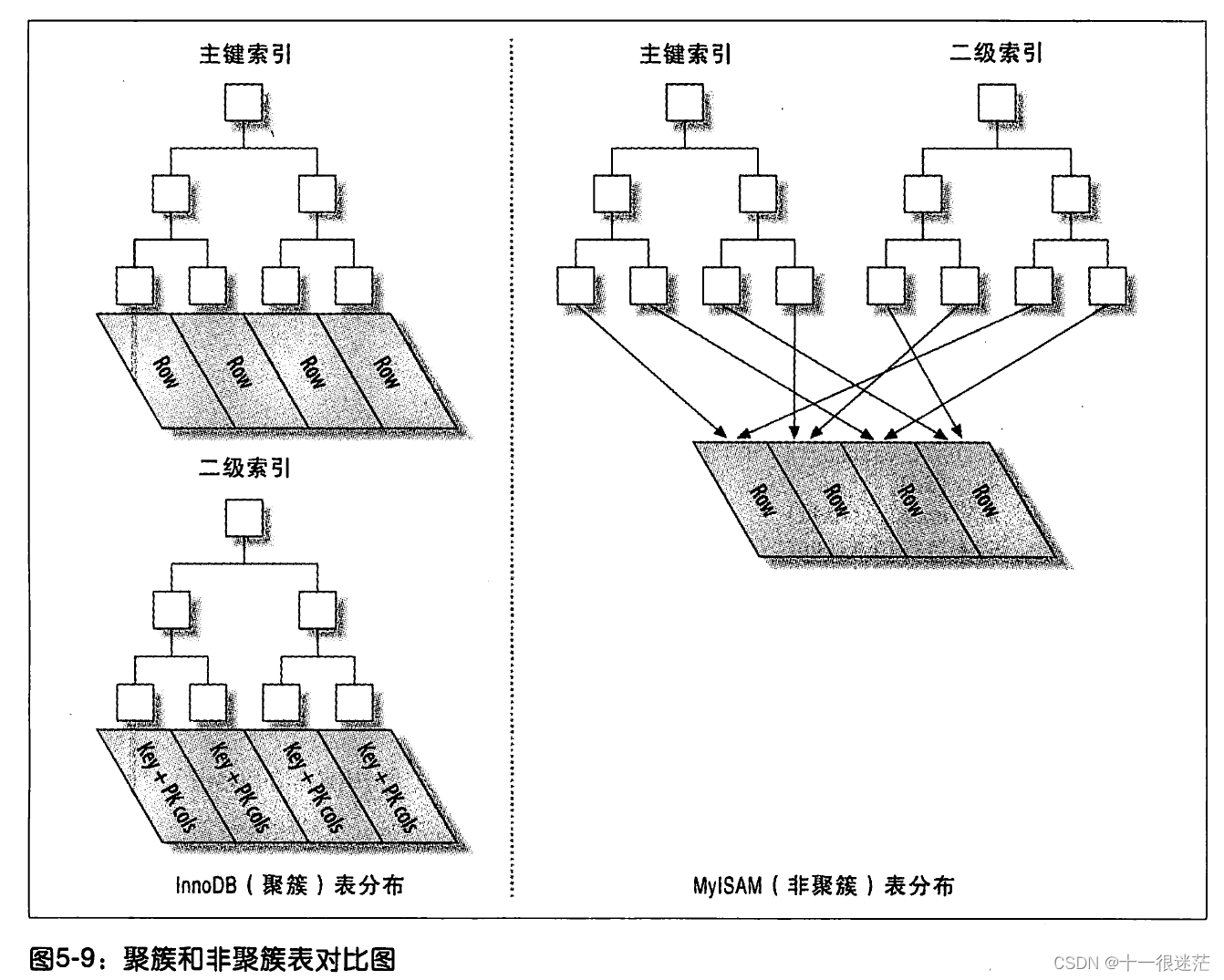
(5)覆盖索引;MySQL只能使用B树做覆盖索引
(6)使用索引进行排序,排序方向必须一致,即都要为正序。
要与索引顺序一致,而且不能 ASC、DESC 混用
(7)InnoDB在二级索引上使用共享锁,在主键索引时使用排他锁。
尽可能将需要做范围查询的列放在索引后面。
可以在索引中加入更多的列,并通过IN()的方式覆盖那些不在WHERE子句中的列(IN方式相当于多个等值查询)。
CHECK TABLE 通常能找出大多数的表或索引的错误。
6. 索引使用注意事项
6.1 重建索引
(1)采用如下方式重建主键索引并不合理,因为会导致整个表的两次重建
alter table T drop primary key;
alter table T add primary key(id);
上述方式重建二级索引是合理的;
(2)更合理的方式是采用:ALTER TABLE t1 ENGINE = InnoDB;(recreate)
重建的表是比较紧凑的,但不会是最紧凑的结构,会预留 1/16 的页空间留给后续的更新使用;
(3)5.5 之前的流程(整个过程不允许原表进行更新)
建立临时表(Server 层创建)
按照主键递增的顺序插入临时表
交换这两个表(表名交换)
删除临时表
(4)5.6 之后采用 Online DDL(不支持加全文索引、空间索引)
建立临时表(InnoDB 创建)
按照主键递增的顺序插入临时表(此过程中所有对 A 的操作记录在一个日志文件 row log 中,此步骤时会从 MDL 写锁降为读锁,可以进行增删查改)
将日志文件的内容应用到临时表中(此步骤可能会产生分裂,造成新的空洞)
进行替换
6.2 索引选择异常
(1)使用二级索引时,尤其是需要回表的操作,一定要检查估计的行数是否准确,若偏差较大,可以使用 analyze 命令;
analyze table 也会加 MDL 读锁;
optimize table = recreate + analyze
(2)force index(index_name)
如果 force index 指定的索引在候选索引列表中,就直接选择这个索引,不再评估其他索引的执行代价。
这种方法的坏处是,一旦索引改名了就需要修改这个语句,不太灵活;
(3)可以考虑修改语句,引导优化器选择期望的索引;
(4)可以重建一个新的索引或者删掉之前的索引;
6.3 索引使用常见坑
(1)隐式类型转换
字符串和数字进行比较时,会把字符串转换为数字;这其实相当于在索引列上加了一个转换函数(例如,当索引列为 VARCHAR 类型时),可能会导致放弃索引搜索功能;
(2)隐式字符编码转换
例如,utf8 需要隐式转换为 uft8mb4
(3)隐式自动截断
例如索引列 c 的类型为 VARCHAR(10),搜索条件为 c = ‘1234567890abcd’,可以确定不会有满足该条件的记录,但 MySQL 会进行自动截断,相当于 c = ‘1234567890’ ,可能会做出很多无用功;














 2268
2268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









