










艺术 文化遗产领域 VQA parper 阅读
Visual Question Answering for Cultural Heritage
文章目录
前言
尽管如此,与绘画和雕塑互动最频繁的方式仍然是拍照。然而,图像本身只能传达艺术品的美学,缺乏充分理解和欣赏它所需要的信息。通常,这些额外的知识既来自艺术品本身(因此也来自描绘它的图像),也来自外部的知识来源,如信息表。前者可以通过计算机视觉算法推断出来,而后者则需要更结构化的数据来将视觉内容与相关信息配对。无论其来源如何,这些信息仍然必须有效地传输给用户。在计算机视觉领域,一个流行的新兴趋势是视觉问答(VQA),用户可以通过自然语言提出问题,与神经网络进行交互,并获得关于视觉内容的答案。我们相信,这将是博物馆参观的智能音频导览和个人智能手机上简单的图像浏览的演变。这将把经典的音频导览变成一个智能的私人教练,游客可以通过询问专注于特定兴趣的解释与之互动。这样做的好处是双重的:一方面,访问者的认知负担将减少,将信息流限制在用户真正想要听到的内容上;另一方面,它提出了与向导互动的最自然的方式,有利于参与。
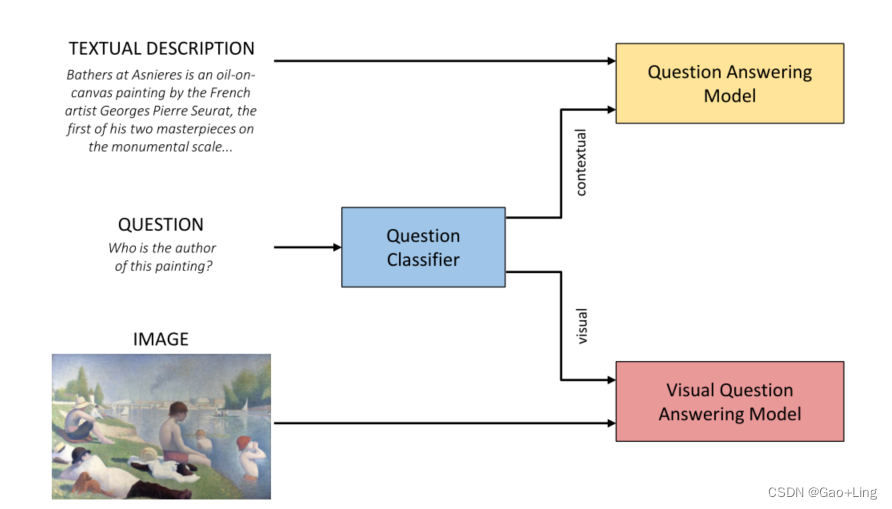
方法
visual Question Answering with visual and contextual questions
这项工作的主要思想是对输入问题的类型(视觉或上下文)进行分类,以便由最合适的子模型回答问题。我们依靠问题分类器来理解问题是否只涉及图像的视觉特征,或者是否需要外部信息源来提供正确答案。然后,根据分类器的输出,将问题提交给VQA或QA模型。在这两种情况下,都必须对问题进行分析和理解,但是使用两种不同的体系结构是由处理不同的额外信息源的需要驱动的。如果问题是可视化的,那么答案就会从图像中生成,而如果问题是上下文相关的,那么答案就会使用外部文本描述生成。
我们的方法用来回答一个问题的总体流程(见图1)如下:
(i)问题分类。问题在问题分类器模块的输入中给出,该模块确定问题是上下文的还是可视化的。
(ii)[可视化]问答。根据预测的问题类型,相应的模块将被激活以生成答案。(a)如果问题是上下文相关的,则将问题以输入的形式提供给一个问答模块,该模块接受输入,也接受对回答问题有用的外部信息。这个系统只根据这个外部信息产生一个输出答案。
(b)如果问题是可视化的,则将问题和图像作为输入输入到可视化问答模块。该系统根据图像的内容生成一个输出答案。
Question Classifier Module
问题分类器模块由Bert[5]模块组成,用于文本分类。BERT利用Transformer[21],这是一种注意机制,可以学习文本中单词(或子单词)之间的上下文关系。对Transformer进行双向训练,以便对语言上下文和语言流有更深入的了解。这个语言模型非常通用,因为它可以用于不同的任务,如文本分类,句子中的下一个单词预测,问题回答和实体识别。通过在Transformer输出上添加一个分类层,这个模型变成了一个问题分类体系结构。输入问题被表示为三种不同嵌入的总和:令牌嵌入、分段嵌入和位置嵌入。此外,在问题的开头和结尾添加了两个特殊的标记。
Contextual Question Answering Module
用于问答任务的模型是关注该任务的另一个Bert模块。在这种情况下,模块同时接受问题和文本描述的输入。由于该系统使用文本信息回答问题,因此文本必须包含相关信息以生成适当的答案。
Visual Question Answering Module
可视化问题回答模块的体系结构类似于Anderson等人在自底向上-自顶向下方法中使用的体系结构。在这里,图像的显著区域由Visual Genome数据集[12]上预训练的Faster R-CNN[18]提取。问题的单词用嵌入[17]的Glove表示,然后用门通循环单元(Gated Recurrent Unit, GRU)对问题进行编码,将每个问题压缩成一个固定大小的描述符。建立了编码问题和显著图像区域之间的注意机制,以权衡对回答问题有用的候选区域。然后将加权区域表示和问题表示投影到一个公共空间,并通过一个元素乘积连接。最后,联合表示通过两个完全连接的层和一个产生输出答案的softmax激活。
实验结果
为了评价模型的性能,我们进行了不同的实验。我们通过独立分析每个组件来衡量模型的性能。
问题分类器Question Classifier
我们用OK-VQA和VQA v2数据集的问题训练问题分类器模块。我们从VQA v2中提取了一些视觉问题,这些问题的数量与OK-VQA中需要外部知识的问题数量相等。得到的数据集被分成训练集和测试集。问题分类器应该从问题的结构中理解答案是否与视觉内容有关。这是一个通用的分类器,与任务的领域无关。事实上,VQA v2和OK-VQA包含通用图像,而我们感兴趣的是在文化遗产领域的应用。通过对VQA/OK-VQA数据集和由Artpedia[20]子集组成的新数据集进行评估,我们展示了我们方法的有效性及其转移到文化遗产领域的能力。由于该数据集不包含问题,而只包含图像和描述,我们从该数据集中提取了30张图像,并为它们添加了数量不定的视觉和上下文问题(两类从3到5个)。我们的问题分类器模块的准确性如表1所示。我们可以观察到,在大多数情况下,它能够正确地预测问题的类型。
Contextual Question Answering
我们在包含30张注释图片的Artpedia子集上测试我们的问答模块。特别地,我们在三个不同的实验中测试了我们的模块的准确性:语境问题测试、视觉问题测试和视觉和语境问题同时测试。请注意,视觉和上下文模块的输出是不同的,因为VQA被视为一个分类问题,而对于QA,从表2所示的结果中,我们可以推断,我们的问题回答模块对上下文问题工作得很好,而对视觉问题的结果更差。这可以从视觉问题是指在ArtPedia的视觉句子中无法描述的绘画的可见细节来证明。
Visual Question Answering
与为问答模块进行的测试类似,我们在视觉和上下文问题上对视觉问答模块进行评估。表2显示了我们的可视化问题回答模型的结果。相反,我们可以从问题回答模块观察到,该模型在视觉问题上表现良好,但不能正确回答上下文问题。这是由于上下文问题需要外部知识(如作者、年份),而纯视觉问题回答引擎无法获取这些信息。
完整模型 Full pipeline
最后,我们将所有模块的功能结合在一起,并对视觉和上下文问题进行测试,获得了0.570的准确性。由于有了问题分类器,完整的管道能够正确地区分视觉问题和上下文问题。可视化问题回答模块和问题回答模块接收它们能够回答的几乎所有问题作为输入(问题回答模块的上下文问题和可视化问题回答模块的可视化问题)。因此,整个模型的性能超过了两个单一应答模块。图2显示了管道的三个组成部分的一些定性结果。这些组件正确地处理了大多数问题,但是可以观察到一些常见的故障情况。例如,问题回答模型可能会在答案中添加一些基本事实中不存在的细节,而视觉问题回答模型可能会将绘画的某些元素与类似的对象混淆。
总结
在本文中,我们提出了一种文化遗产领域的视觉问题回答方法。我们已经解决了两个重要问题:需要处理包含的图像和上下文知识,以及缺乏数据可用性。我们提出的模型结合了VQA和QA模型的功能,依赖于一个问题分类器来预测它是指视觉内容还是上下文内容。为了评估我们模型的有效性,我们用可视化的和上下文相关的问答对注释了ArtPedia数据集的一个子集。
阅读者的总结
感觉本文蹭了艺术VQA的热度。
简单说,就是在进行回答之前,先将question进行分类,然后分别进行VQA回答和QA回答,得到答案。
以上module在3个数据集上跑,结果就是,question分类任务的效果不错,对VQA的回答效果不错,但是QA任务的效果不行(也就是开放型回答的效果just soso)















 6571
6571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









