







Ai生成测试用例
- 本篇会详细介绍ai大模型对于测试工程师的使用与思考,结合实际运用来实现ai对于测试工程师提效的方式方法
- 在年后deepseek横空出世,实际去使用后发现deepseek-R1真的很厉害,那么具体在工作内,我们应该怎么去实际运用就值得思考一番
- 在了解ai基本原理与对话沟通过程中,发现还是能做很多东西的,那么对于测试工程师来说测试用例是一个绕不开的话题,怎么能在工作中去实际结合ai来进行落地
1.流程介绍
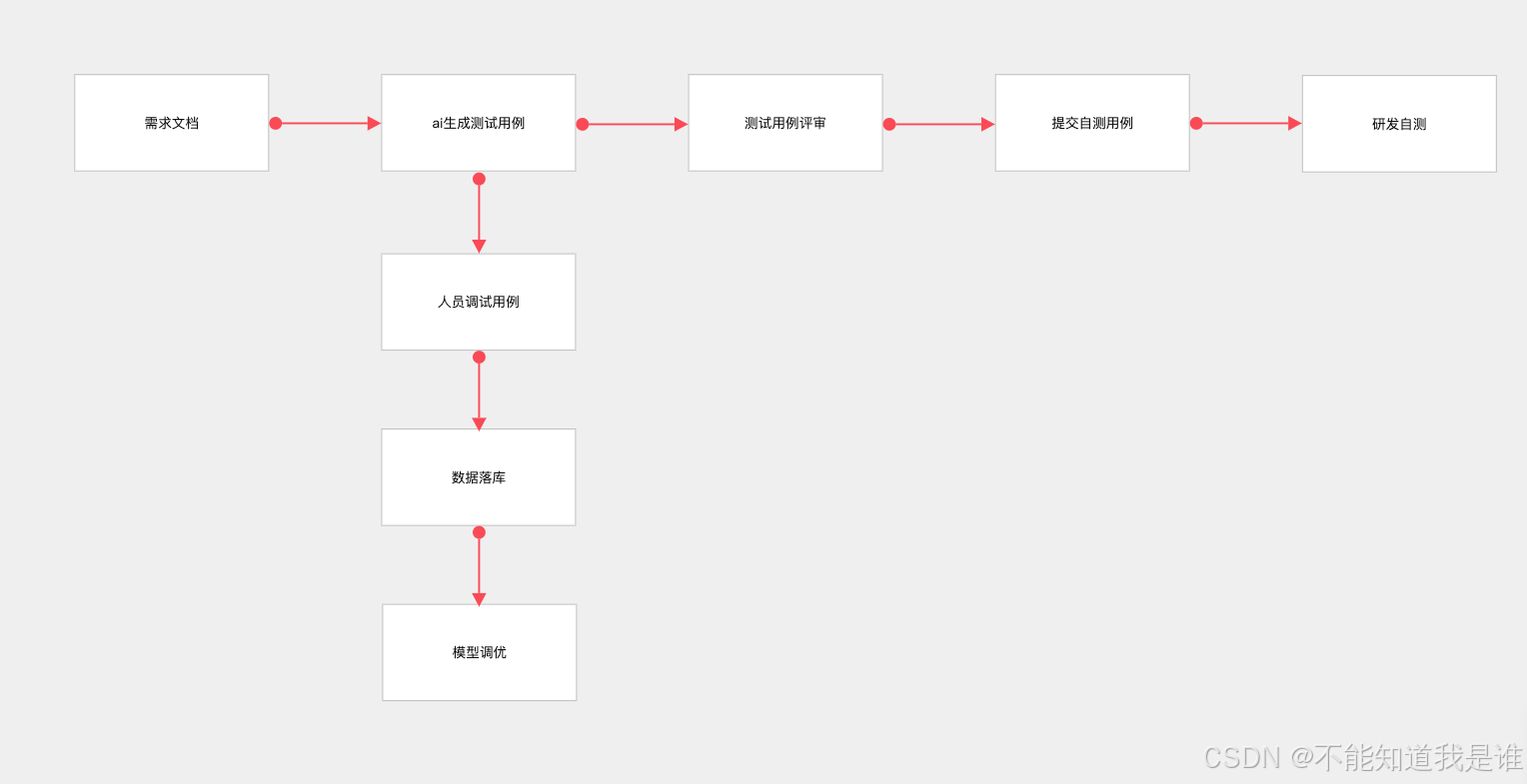
传统工作中,我们会根据需求文档来编写测试用例

对于ai辅助生成测试用例,主要会在人员编写的环节增加了整体ai流程,后面会讲到模型训练与调整
2.依赖安装
2.1python版本
需要明确一点就是python的版本一定要是3.8或3.8以上,查了很多ai三方sdk只支持python3.8以上的版本
2.2接入openAi
pip install openai 先安装openai的三方库
在实际开发中,发现deepseek/腾讯混元/阿里千问都支持openAi模块进行调用,字节的豆包需要下载Ark模块来进行请求
from openai import OpenAI
from volcenginesdkarkruntime import Ark
from common.logJournal import logger
class OpenAi:
def __init__(self, typeOf):
if typeOf == 1:
self.client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
self.model = "deepseek-chat"
elif typeOf == 2:
self.client = Ark(api_key=api_key)
self.model = "ep-20250205144141-zbd8k"
elif typeOf == 3: #
self.client = OpenAI(api_key=api_key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
self.model = "qwen-plus"
elif typeOf == 4: #
self.client = OpenAI(api_key=api_key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
self.model = "qwen-max"
else:
logger.error(f'OpenAi __init__ Exception typeOf error',error=traceback.format_exc())
在__init__内进行初始化
获得self.client与self.model,其中model为你的模型名称,在每个ai的api文档内都能查到具体不同的模型对应的功能以及思考力度
3.生产用例
生产测试用例需要使用非流式响应来获取全文stream=False
一般网上会告诉大家用input输入文案后去获取ai的流式结果,但是我们如果用写case的话,其实可以省略掉这个步骤,直接告诉ai我需要做什么,也不用去进行多轮对话
def run(self, text):
# 获取完整响应内容 (非流式响应)
attempts = 0
while attempts < 10:
try:
messages = [{"role": "system", "content": text}]
messages.append({"role": "user", "content": "输入需要产出的用例格式/具体内容/标题规范等"})
response = self.client.chat.completions.create(
model= self.model,
messages=messages,
max_tokens =8000,
stream=False
)
# 格式化数据
content = response.choices[0].message.content
json_data = self.json_text(content)
return json_data
except Exception as e:
attempts += 1
logger.error(f'OpenAi run Exception 尝试 {attempts} 失败', error=traceback.format_exc())
time.sleep(1) # 等待1秒后重试
return False # 所有尝试都失败后返回False
对于用例返回的内容,我们也可以在content内增加ai模型返回的定义
"1.TestTitle 类型:String 内容:测试用例标题+测试目标"
"2.Preconditions 类型:String 内容:前置条件"
"3.TestCase 类型:String 内容:测试步骤"
"4.ExpectedResults 类型:String 内容:预期结果"
"5.Problem 类型:string 内容:你在分析过程中遇到的问题"
"6.ImportantLevel 类型 string 内容:测试用例优先级 主流程用例为P1,其他默认P2"
同时我们也对返回的json做了数据格式处理
json_data = self.json_text(content)
4.用例输出
生产出的测试用例通过格式转换,我们可以去写成接口,返回在response内

4.1用例颗粒度
因为tokens的问题,所以用例颗粒度会较低,并且会有幻觉与场景丢失情况,解决的办法就是,我们可以通过模块化区分,针对模块来生产出测试用例,例如caseTitle内为模块标题,下方的case则为模块内用例,从而变相增加用例的颗粒度
产出的case可以通过结果生成页面,提供给测试同学进行修改补充与完善
4.2用例产出
用例产出可以分为多种模式,如果有三方用例管理平台,可以通过api方式直接上传我们的测试用例,如果没有,也可以通过python的xmind库进行一键导出用例
5.用例调整
我们把ai返回的用例转换成json后去做格式处理,然后封装成接口并且把模块的测试用例保存到数据库内
并且做成前端可视化页面,可以提供给测试同学去手动修改ai产出的测试用例
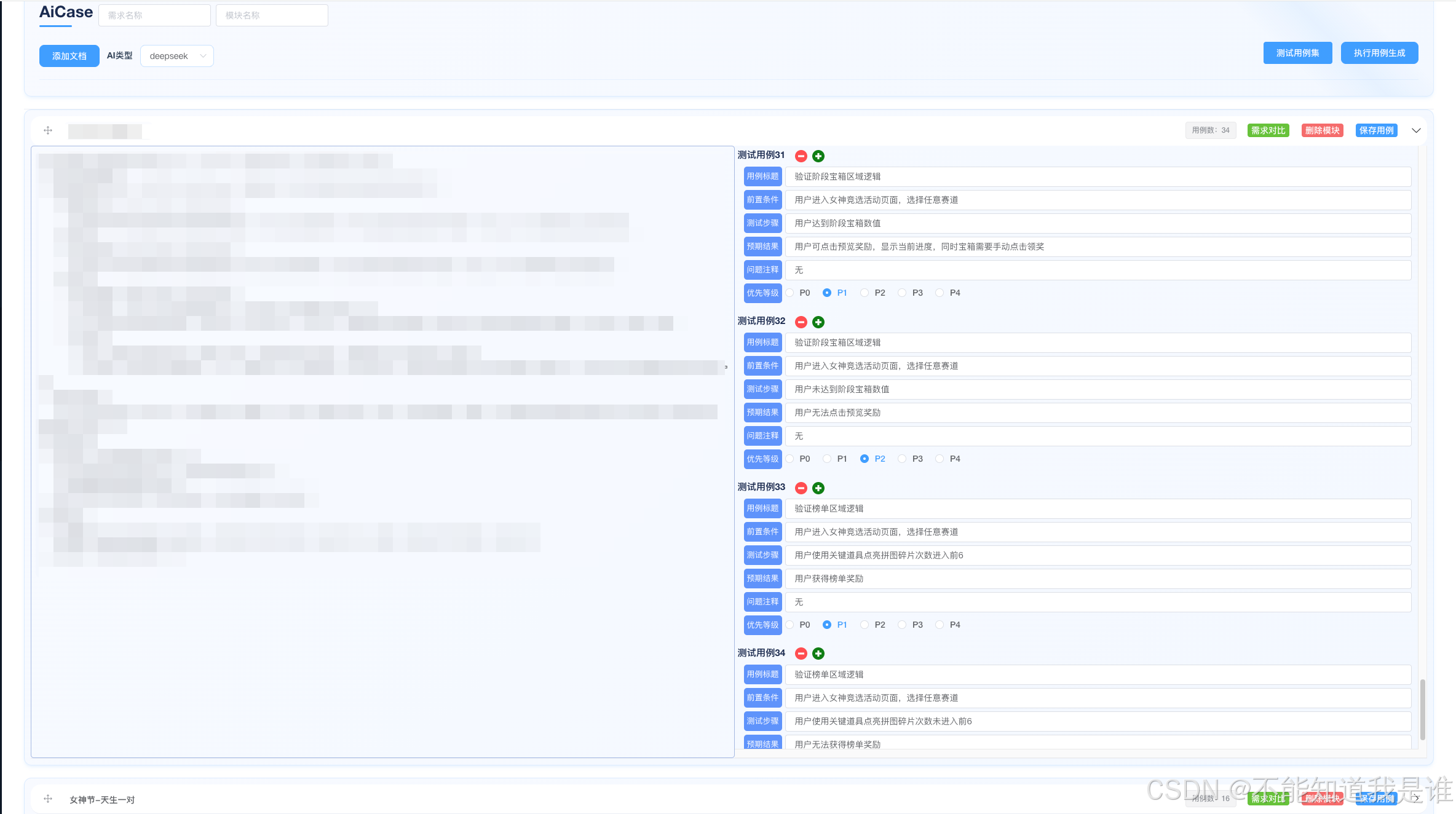
我们还支持了一上传用例到三方平台并且可以针对测试计划创建进行的一键添加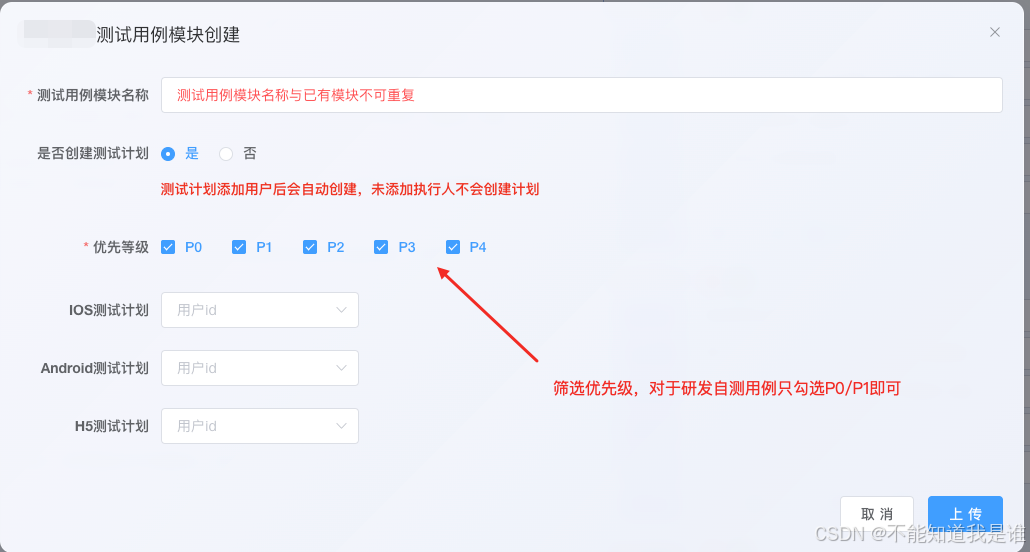
6.数据落库
6.1背景
数据落库主要分为两点
- 第一就是我们可以做出前端页面,针对历史用例可以去进行复用,提升编写用例效率,例如增加通用场景的case进行一键添加
- 第二就是为了方便我们后续对ai进行训练微调
6.2数据区分
我们数据落库的时候需要记录一些内容的明细
- 需求名称
- 模块名称
- 需求文档内容
- ai生产用例
- 人工验收后用例
下面会讲为什么要记录这些内容,而不是只记录修改后的用例就行

7.模型调优
当我们的测试用例数据有一定量级时,我们就可以对模型进行调优,让ai模型更适合测试用例生产
举例:千问ai

在千问的api文档内,有明确的告诉大家sft与dpo模型调优的区别,目前来看,其实第二种更适合我们
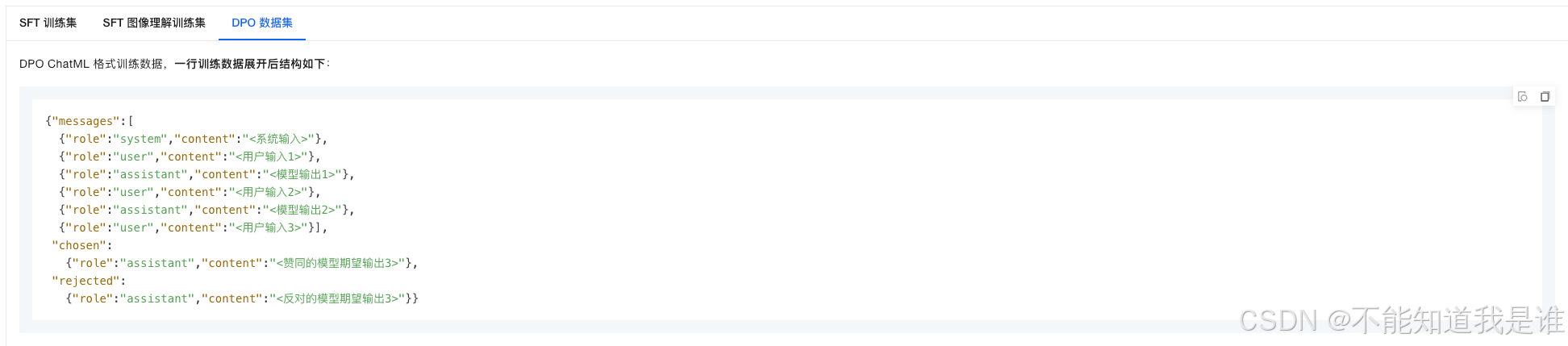
我们来看调优DPO的时候需要的数据准备就能发现,我们需要举正反例子,那么我们在数据落库的时候,修改前与修改后的用例则派到了用场,只不过需要注意的是,token的输入对于测试用例的调优来说,确实有点高,不过如果不训练,实际上现有的模型解析思考已经能满足我们日常用例的生成了。
编写不易,分享请注明作者与地址~

















 1799
1799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









