







tidyverse技巧(2)
继续学习数据科学中的R语言[1]
fct_lump分箱函数
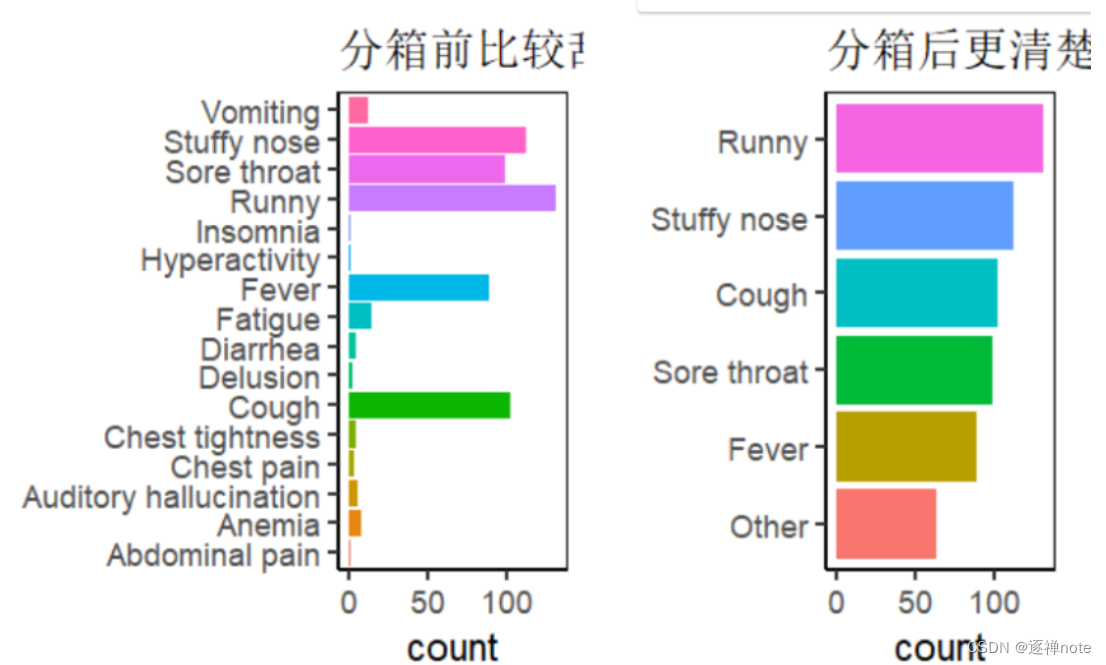
对于数据我们通常关注的是前几位或者后几位的情况,所以可以利用fct_lump将这些关键数据挑出来,当fact_lump(data,num)中的数据为正是表示选出较大的前num为数据,当为负数时表示选出排名后num为的数据被选出来。具体例子见参考[2]
library(tidyverse)
library(patchwork)
tb <- tibble::tribble(
~disease, ~n,
"Stuffy nose", 112,
"Runny", 130,
"Fever", 89,
"Diarrhea", 5,
"Vomiting", 12,
"Cough", 102,
"Sore throat", 98,
"Fatigue", 15,
"Abdominal pain", 2,
"Delusion", 3,
"Auditory hallucination", 6,
"Insomnia", 1,
"Anemia", 8,
"Hyperactivity", 2,
"Chest pain", 4,
"Chest tightness", 5
)
fct_reoder2()
让图例的顺序与图的曲线顺序一致 fct_reorder2()函数规则要求有两个向量参数,其中第一个为.x,第二个为.y,还为该函数的.fun参数设计了两个辅助函数: last2():为默认的选项,取.y根据.x排序后的最后一个元素,然后以这个数值作为因子类别排序的依据。 first2():取.y在根据.x排序后的第一个元素,同样以这个数值作为因子类别分类的依据。在可视化中默认得到的就是取纵坐标按很坐标排序后的最后一个元素,实际就是每根线条最右侧的纵坐标,这也是直观上梅根线的高度,以此再对分组变量进行排序,图例的线条自然和图中线条高低对应。详见R语言学堂[3]
dat_wide <- tibble(
x=1:3,
top=c(4,5,6),
middle=c(4.3,4.5,5),
bottom=c(3.5,3.75,4.5)
)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5794
5794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









