






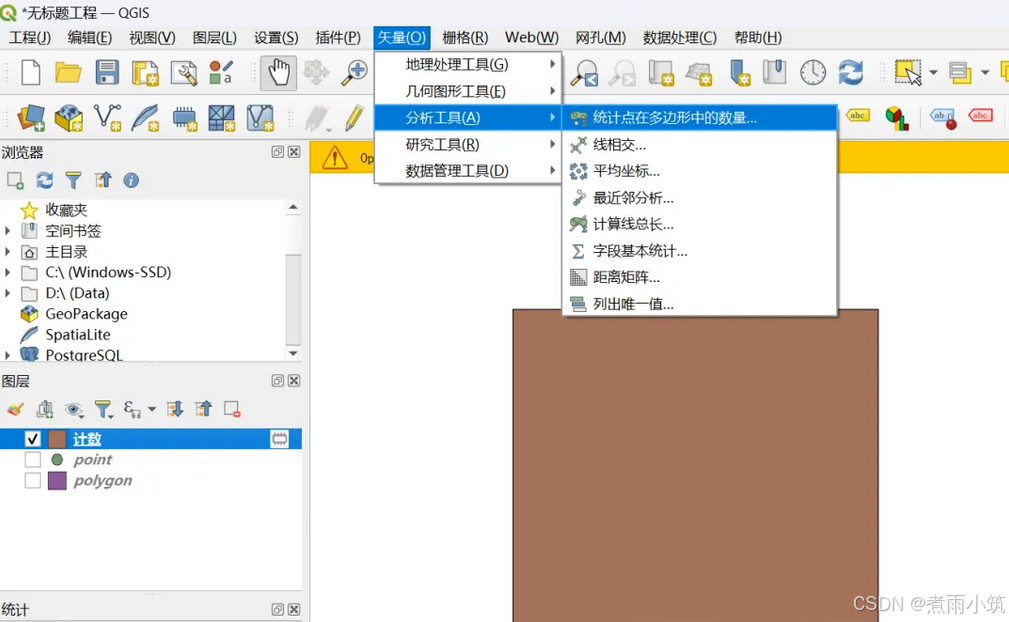
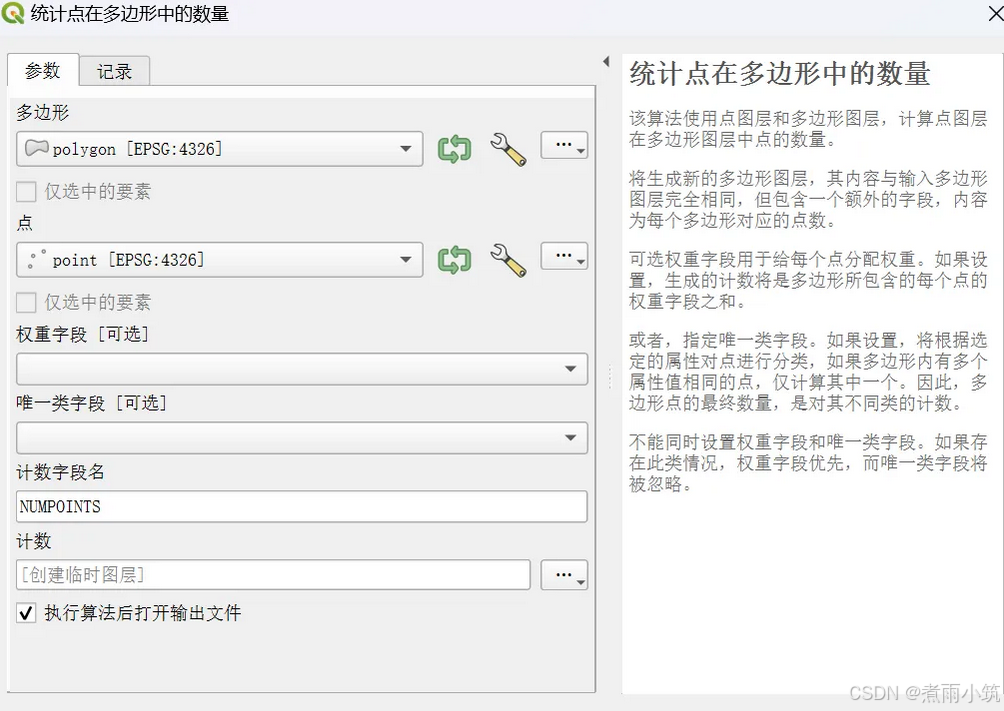
统计区域内点的数量用途广泛,比如用来统计各行政区域或划定的特定区域内POI点的数量。在QGIS中存在分析工具可以使用,如下,(欢迎关注本人公众号--交通数据探索师)
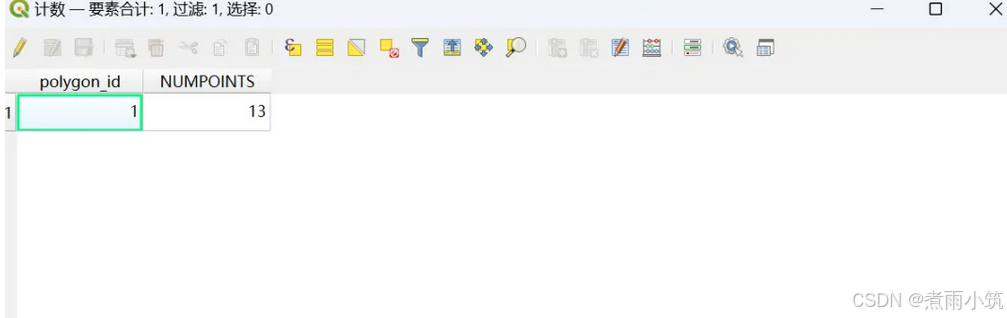
表示polygon_id(即多边形ID)为1的多边形内包含13个点。
想在geopandas中实现该过程需要用到下面的空间连接函数,用来确定点是否在在面内。
gpd.sjoin(gdf1, gdf2, how, predicate)
how: 指定连接的类型,以及在生成的 GeoDataFrame 中保留哪些几何图形
left: 表示使用左边(即上面的gdf1)的GeoDataFrame中的索引;仅保留左边的GeoDataFrame的几何列
right: 表示使用右边(即上面的gdf2)的GeoDataFrame中的索引;仅保留右边的GeoDataFrame的几何列
inner: 使用两个GeoDataFrame中索引值的交集;仅保留左表的几何列
predicate:
intersects: 相交关系
contains: 包含关系 b包含a表示a完全在b的内部且a与b的边界不接触
within: 对象的边界和内部只与另一个对象的内部相交(而不是其边界或外部)。 b.within(a) 等价于 a.contains(b)
touches: 触摸,两个对象至少有一个共同点,并且它们的内部没有与另一个对象的任何部分相交
crosses: 交叉,对象的内部与另一个对象的内部相交,但不包含另一个对象,且相交处的尺寸小于一个对象或另一个对象的尺寸。
overlaps: 重叠,几何图形有多个共同点,但不是所有共同点,且具有相同的维度,并且几何图形内部的交集与几何图形本身具有相同的维度。how参数演示
data = (
gpd.
sjoin(polygon, point, how='left', predicate='contains')
)
data输出数据如下,
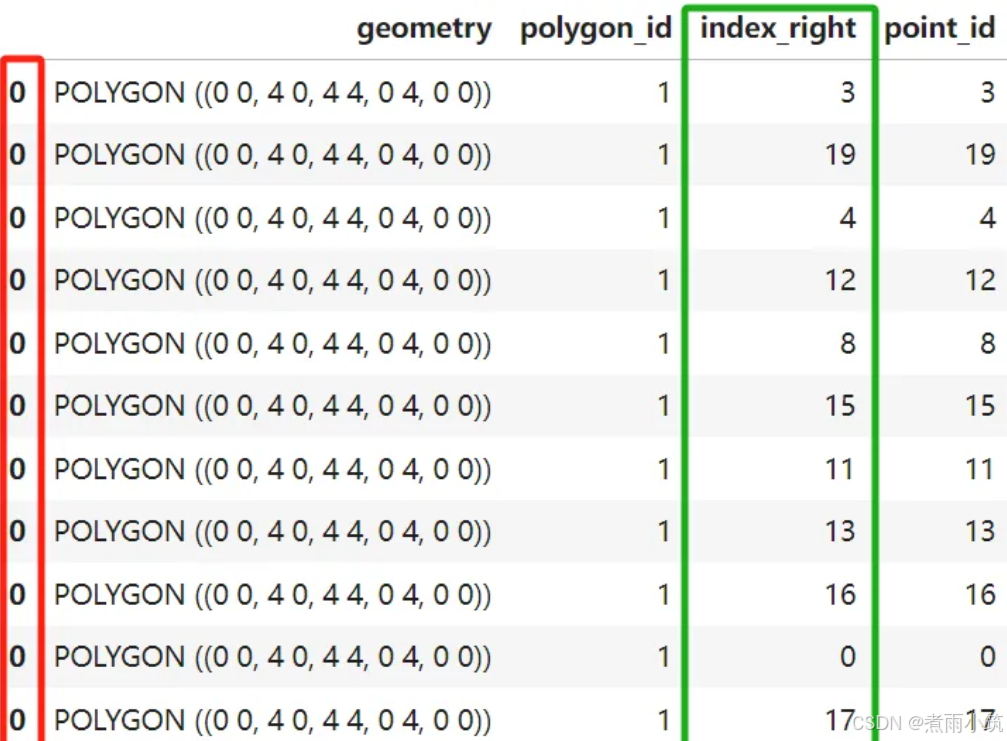
上面how=left,则生成的新表中的索引(如上图红框)使用的是sjoin函数中传入的左表的数据的索引,index_right列(如上图绿框)表示是对应的右表的索引。同时只保留了左表的几何列。
predicate参数演示
gpd.sjoin(point, polygon, how='right', predicate='within')
表示 基于左表within右表
(即左表的地理要素在右表的地理要素内部)的关系进行连接
gpd.sjoin(polygon, point, how='left', predicate='contains')
表示 基于左表contains右表
(即左表包含右表)的关系进行连接
以上两种写法是相同的接下来开始计算区域内点的数量,
使用的示例数据如下,
import geopandas as gpd
from shapely.geometry import Point, Polygon
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
np.random.seed(1)
polygon = (
gpd.
GeoDataFrame(geometry=[Polygon([(0, 0), (4, 0), (4, 4), (0, 4)])], crs='epsg:4326').
assign(polygon_id=1)
)
point = (
gpd.
GeoDataFrame(geometry=[Point(x, y) for x, y in zip(np.random.uniform(-0.5, 4, 20), np.random.uniform(-0.5, 4, 20))], crs='epsg:4326').
assign(point_id=range(20))
)
fig, ax = plt.subplots(figsize=(6, 2.5), dpi=300)
polygon.boundary.plot(ax=ax, color='green', linewidth=0.5, alpha=0.7)
point.plot(ax=ax)
plt.show() 可视化如下,
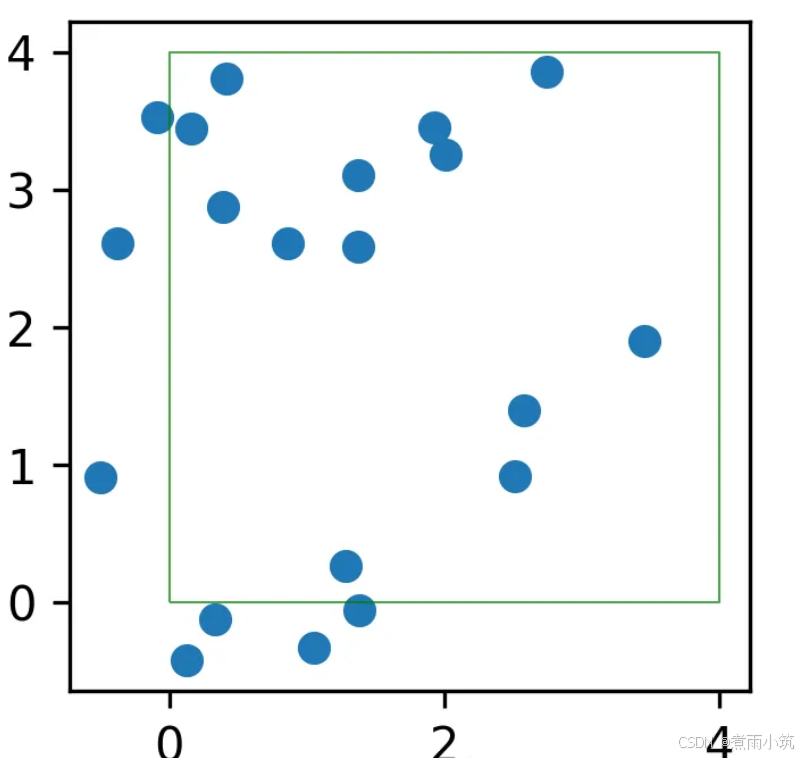
具体统计代码如下,
data = (
gpd.
sjoin(polygon, point, how='left', predicate='contains'). # 通过空间连接确定点与面的地理关系
groupby('polygon_id').
agg(point_num=('point_id', pd.Series.nunique)).
reset_index()
)
data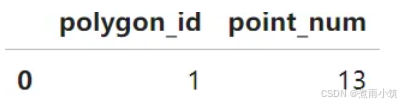
更多精彩内容,见本人公众号--交通数据探索师


















 2049
2049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











