







笔者在使用如下所示的代码时,在jupyter notebook中产生的如下效果
scaled_img_f = np.zeros((h//2,w//2,c),dtype="float")
for x in range (h//2):
for y in range(w//2):
scaled_img_f[x,y,:] = img[2*x,2*y,:]
scaled_img_i = np.zeros((h//2,w//2,c),dtype="int")
for x in range (h//2):
for y in range(w//2):
scaled_img_i[x,y,:] = img[2*x,2*y,:]
#print(scaled_img_i == scaled_img)
#print(scaled_img)
#print(t)
#print(scaled_img_f)
plt.subplot(1,3,1)
plt.imshow(scaled_img_f)
plt.subplot(1,3,2)
plt.imshow(scaled_img_i)
plt.show()
# display scaled down image
其中img是预先读取的图片,生成效果如图:
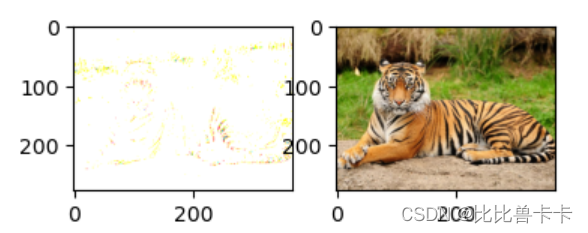
代码中两个矩阵仅有的不同之处就是矩阵的数据类型,导致两图不同的原因并不是因为他们数据不同,而是因为他们在imshow时被处理的方式不一样。
对于imshow函数,opencv的官方注释指出:
函数可以缩放图像,具体取决于其深度:
. - 如果图像是 8 位无符号的,则按原样显示。
. - 如果图像是 16 位无符号或 32 位整数,则像素除以 256。即取值范围[0, 255\ * 256]映射到[0, 255]。
. - 如果图像是 32 位或 64 位浮点,则像素值乘以 255。即 .value 范围[0, 1] 映射到[0, 255]。
所以上述两个矩阵被不同地处理了,这就是图1严重发白的原因(数值太大了)
所以,如果提前给浮点数除以255,问题迎刃而解。















 5814
5814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









