










我们今天来介绍一项完成Long-horizon任务的一项新的技术:ManipGen。
什么叫Long-horizon?就是任务比较长。说到底,也是任务比较复杂。
那么这个技术就给我们提供了一个非常好的解决这类问题的思路,同时,也取得了不错的效果。
项目链接:https://arxiv.org/pdf/2410.22332
我们废话少说,直接进入正题吧。
一、ManipGen 是什么
ManipGen 是一种全新的机器人操控技术,它致力于解决机器人在复杂环境下执行长任务操控任务的难题。
以往的机器人操控技术,在面对复杂任务时往往力不从心。要么需要大量的人工标注数据,成本极高;要么泛化能力很差,稍微换个场景或者任务,就 “罢工” 了。
ManipGen 则另辟蹊径,它通过结合模拟训练、基础模型和创新的策略设计,让机器人具备了强大的零样本学习能力,能够在真实世界中完成各种从未见过的任务。

二、ManipGen 有什么用
ManipGen 的出现,为机器人操控带来了质的飞跃,它的应用场景非常广泛。
**首先,在智能家居领域,**它可以让家用机器人更好地理解和执行各种任务。比如,当你说 “机器人,帮我把桌子上的东西收拾一下,再把餐具放进橱柜里”,它就能准确地识别桌子上的物品,规划合理的动作路径,避开障碍物,把东西收拾好并放进橱柜。这大大提高了家居生活的便利性,让我们的生活更加轻松舒适。
其次,在工业生产中,ManipGen 也能发挥重要作用。它可以使工业机器人更加智能地处理各种复杂的装配任务。面对不同形状、不同摆放位置的零件,机器人能够快速规划抓取和装配策略,提高生产效率和产品质量,降低生产成本。 在物流行业,机器人可以利用 ManipGen 技术,更高效地完成货物的分拣、搬运和存储。它们能够准确识别不同的货物,合理规划搬运路线,避免碰撞和损坏,提升物流运作的整体效率。
三、ManipGen 的核心方法
1、任务分解与基础模型的运用
ManipGen 的核心之一,是利用基础模型对任务进行分解。它把复杂的操控任务分解成一个个简单的子问题,就像把大象放进冰箱,分成 “打开冰箱门”“把大象放进去”“关上冰箱门” 这几个步骤一样。如下图:

这里的基础模型,主要是视觉语言模型(VLMs),比如 GPT-4o。
它能理解人类的语言指令,把任务描述转化为具体的操作步骤。当收到 “把食物放进微波炉加热” 的指令时,GPT-4o 会分析出 “找到食物”“拿起食物”“打开微波炉门”“放入食物”“关闭微波炉门”“启动微波炉” 等一系列子目标。
然后,通过语言条件姿态估计器(比如 Grounded SAM)来确定每个子目标中物体的位置和姿态。它会分析场景中的图像,找到食物和微波炉的准确位置,计算出机器人抓取食物和操作微波炉的最佳姿态。接着,使用运动规划器(如 Neural MP)规划出机器人的运动轨迹,让机器人能够安全、高效地完成每个子任务。
2、局部策略
整体PipeLine:
ManipGen 引入了一种全新的策略 —— 局部策略。这种策略只关注目标物体附近的局部区域,具有很多独特的优势。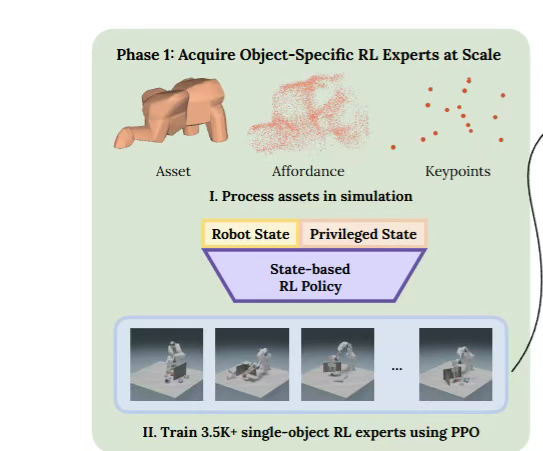
它对绝对机器人和物体的姿态不敏感,不管机器人和物体在什么位置、什么角度,局部策略都能发挥作用;它不受技能执行顺序的影响,先做哪个动作、后做哪个动作,都不会干扰它的运行;它还对全局场景配置具有不变性,无论周围环境多么复杂,它都能专注于自己的 “小目标”。
为了训练这些局部策略,ManipGen 采用了一种两阶段训练方法:
(第一阶段如上图)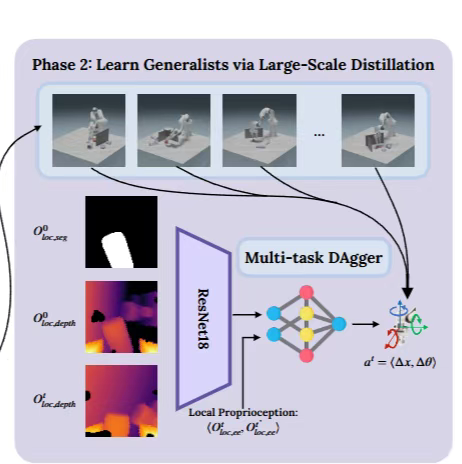
第一阶段,在模拟环境中使用强化学习(RL)训练大量基于状态的专家策略。这些专家策略就像是一个个 “小能手”,分别擅长抓取、放置、操作把手等不同的技能。在训练抓取技能时,会在模拟环境中放置各种各样的物体,让机器人学习如何准确地抓取它们。
(第二阶段如上图)
第二阶段,通过 DAgger(Dataset Aggregation)算法,把这些单任务的专家策略提炼成通用的视觉运动策略。不过,传统的 DAgger 算法在多任务场景下有一些问题,要么会导致策略学习到与当前策略差异很大的数据,要么会因为每次只从一个物体获取数据而产生不稳定的结果。ManipGen 对 DAgger 进行了改进,引入了一个大小为 K 的重放缓冲区,它可以存储最近的 K*B 条轨迹。训练时,在重放缓冲区上更新策略和从环境中收集新的轨迹这两个操作交替进行,这样就能让策略更好地学习不同物体和场景下的操作模式。
3、模型整体与数据
为了让局部策略能够在各种情况下都表现出色,ManipGen 在模拟训练上下了很大功夫。在数据生成方面,它精心挑选了大量的物体用于训练。
比如在训练抓取和放置技能时,使用了 UnidexGrasp 数据集中的 3500 个物体,这些物体涵盖了碗、杯子、瓶子等各种常见物品。同时,为了增加训练的难度和真实性,还会在场景中随机生成杂物和障碍物,让机器人学会在复杂环境中避开它们,准确地完成任务。
在训练操作把手、打开和关闭抽屉等技能时,会从 Partnet 数据集中选取 2600 个物体的把手,并对物体的大小、形状、位置、方向、关节范围、摩擦和阻尼系数等进行随机化处理,模拟出各种真实世界中的情况。

在观察设计上,ManipGen 采用了一种低维的物体形状表示方法,通过对物体网格进行最远点采样(FPS),获取少量关键的点(K=16)来表示物体形状。
这样既能减少数据量,又能让机器人快速了解物体的大致形状,更好地规划操作动作。此外,还会在观察中加入奖励信息和最终观察的指示,让机器人更容易理解自己的行为是否正确,从而加快学习速度。
为了让机器人在真实世界中也能应对各种复杂的视觉情况,ManipGen 对模拟环境中的深度图进行了数据增强。比如,模拟真实世界中物体边缘的噪声和不规则空洞。对于边缘噪声,通过双线性插值对深度图进行处理,模拟出边缘像素丢失和噪声的效果;对于不规则空洞,通过计算随机像素级掩码并进行高斯模糊,得到不规则形状的掩码,然后应用到深度图像上。还会进行随机相机裁剪,增加图像的多样性,让机器人学习到不同视角下的物体特征,提高视觉运动学习性能。
4、zero-shot long-horizon 操作的实现
在实际应用中,ManipGen 的零样本长周期操控能力令人惊叹。当接收到一个新的任务指令时,它会按照以下步骤执行:

首先,视觉语言模型(如 GPT-4o)根据任务描述和场景图像,生成一个操作计划,这个计划是一系列的(物体,技能)元组。比如,对于 “把食物放进微波炉加热” 的任务,计划可能是(“食物”,“拿起”),(“微波炉”,“打开门”),(“食物”,“放入”),(“微波炉”,“关闭门”),(“微波炉”,“启动”)。
然后,利用语言条件姿态估计器(如 Grounded SAM),根据操作计划中的物体和技能,估计出每个物体的目标姿态。在估计 “食物” 的目标姿态时,它会分析场景中的图像,找到食物的位置和形状,计算出机器人抓取食物的最佳姿态。
接着,运动规划器(如 Neural MP)根据目标姿态和当前场景的点云信息,规划出机器人的运动轨迹。在规划过程中,会考虑到障碍物的位置,确保机器人能够安全地到达目标位置。
最后,机器人根据规划好的轨迹移动到目标物体附近,然后部署相应的局部策略进行操作。在抓取食物时,会根据局部策略调整抓取的力度和角度,确保能够稳定地抓取物体。在操作过程中,会不断根据传感器的反馈调整动作,直到完成整个任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









