







七大排序
1.排序的基本概念与分类
①排序的基本概念
假设有n个记录的序列为{r1, r2, …, rn},其对应的关键字分别为{k1, k2, k3, …, kn},需要确定1, 2, …, n的一种排列p1, p2, …, pn,使得其对应的关键字满足,kp1 ≤ kp2 ≤ … ≤ kpn,即使得序列称为一个按关键字有序的序列{rp1, rp2, … rpn},这样的操作就叫做排序。
如:序列关键字为{2, 3, 5, 1},对其进行升序排列后,得到的结果为{1, 2, 3, 5}。
②排序的稳定性
排序不仅可以针对主关键字排序(一个主关键字对应一条唯一的记录),也可以针对次关键字排序(一条次关键字对应多条记录),因为排序的记录序列中可能出现两个或两个以上的关键字相等的记录,排序结果可能出现不唯一的情况,因此我们给出了稳定与不稳定排序的定义如下:
假设ki = kj(i ≤ i ≤ n, 1 ≤ j ≤ n, i ≠ j),且在排序前的序列中ri领先于rj(i < j)。如果排序后ri仍领先rj,则称为所用的排序方法是稳定的;反之,可能使得排序后的序列中rj领先于ri,则称所用的排序方法是不稳定的。
如:下记录表对分数进行升序排列。

未排序时张三在钱六前面,对于稳定排序后,张三依旧在钱六前面;然而对于不稳定排序,可能出现张三在钱六前面,也可能出现钱六在张三前面。
稳定排序算法有:冒泡排序、直接插入排序、归并排序。
不稳定排序算法有:堆排序、快速排序、希尔排序、直接选择排序。
③内排序与外排序
内排序:在排序整个过程中,待排序的所有记录全部放置在内存中。
外排序:由于排序的记录太多,不能同时放在内存中,整个排序过程需要在内外存之间多次交换数据才能进行。
④影响排序算法的性能的因素
- 时间性能:排序算法的时间开销是衡量其好坏的最重要标志,用时间复杂度O来表示。
- 辅助空间: 辅助存储空间是除了存放待排序所占用的存储空间之外,执行算法所需要的其他存储空间。
- 算法的复杂性: 指的是算法本身的复杂度,而不是时间复杂度。
2.冒泡排序
冒泡排序是一种交换排序,它的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止。
每一次冒泡将序列未排序部分的最大值冒泡到未排序部分序列末尾。
如:待排序序列是{9,5,1,8,3},序列长度为5。
先来看第一次冒泡过程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8LcooLpo-1638801062049)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638498994195.png)]](https://img-blog.csdnimg.cn/cedb154a4ee849ce82e81e2fba94d822.png)
黄色为待排序序列,红色代表已经排序完成的部分,每一次冒泡是对上一次冒泡后的待排序序列进行排序。 整个排序过程如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RowmASpb-1638801062049)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638500324773.png)]](https://img-blog.csdnimg.cn/cf33043988e242b2b6fb43c5b9798d12.png)
其C++代码如下:
void bubbleSort(vector<int> &nums) {
//设记录序列长度为n
//外循环,冒泡次数为n-1次
for (int i = 0; i < nums.size() - 1; ++i) {
//内循环,每一次冒泡需要比较n - i次
for (int j = 1; j < nums.size() - i; ++j) {
if (nums[j] < nums[j - 1]) {
swap(nums[j], nums[j - 1]);
}
}
}
}
冒泡排序时间复杂度为:O(n^2)。
冒泡排序空间复杂度为:O(1)。
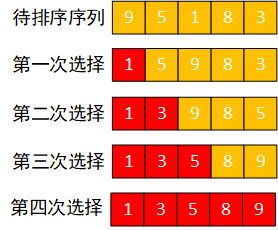
3.简单选择排序
简单选择排序算法就是通过n - i次关键字间的比较,从n - i + 1个记录中选出关键字最小的记录,并和第i(1 ≤ i ≤ n)个记录交换。
每次从待排序列种选出一个最小值,然后与待排序序列的第一个元素互换,直到全部待排序列数据排完即可。
如:待排序序列为{9,5,1,8,3},序列长度为5
先来看一次选择过程:

黄色为待排序序列,红色代表已经排序完成的部分,每一次选择是对上一次选择后的待排序序列进行排序。 整个排序过程如下图:
其C++代码如下:
void selectSort(vector<int> &nums) {
//设记录序列长度为n
//外循环,选择次数为n-1次
for (int i = 0; i < nums.size() - 1; ++i) {
int min = i; //选择待排序序列的第一个元素作为每次选择开始的最小值
//内循环,每一次选择需要比较n - i - 1次
for (int j = i + 1; j < nums.size(); ++j) {
if (nums[j] < nums[min]) {
min = j;
}
}
if (min != i) {
swap(nums[i], nums[min]);
}
}
}
直接选择排序时间复杂度为:O(n^2)。 虽然都是O(n ^2),但简单选择排序性能略优于冒泡排序。
直接选择排序空间复杂度为:O(1)。
4.直接插入排序
直接插入排序的基本操作是将未排序好序列的第一个元素插入到已经排好序的序列中。
如:待排序序列为{9,5,1,8,3},序列长度为5
先来看一次插入过程,黄色为待排序序列,红色代表已经排序完成的部分,前面4个元素已经排序好了,将最后一个待排元素3插入到排序序列中:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2lELjmk0-1638801062050)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638536352749.png)]](https://img-blog.csdnimg.cn/ce9700916d0844cb97e6ef911a806112.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAMTIzWVFI,size_17,color_FFFFFF,t_70,g_se,x_16)
整个排序过程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QeTUZ5zT-1638801062051)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638535518855.png)]](https://img-blog.csdnimg.cn/d1fb9a895a7d414c9a18722a6bee10ec.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAMTIzWVFI,size_11,color_FFFFFF,t_70,g_se,x_16)
C++代码如下:
void insertSort(vector<int> &nums) {
//设记录序列长度为n
//外循环,插入次数为n - 1次
for (int i = 0; i < nums.size() - 1; ++i) {
int end = i; //end为已排序序列最后一个元素下标
int temp = nums[i + 1]; //temp用来保存待插入元素
//内循环,最多循环i次
while (end >= 0) {
if (nums[end] > temp) {
nums[end + 1] = nums[end];
--end;
} else {
break;
}
}
nums[end + 1] = temp;
}
}
直接插入排序时间复杂度为:O(n^2)。 虽然都是O(n ^2),但直接插入排序性能优于简单选择排序和冒泡排序。
直接插入排序空间复杂度为:O(1)。
5.希尔排序
直接插入排序在记录序列本身就是基本有序或者记录序列比较短时效率比较高,然而这两个条件比较苛刻,但是没有条件我们可以创造条件。
我们可以把待排序序列分为若干个子序列,此时每个子序列的记录序列就比较短了,对这些子序列分别进行插入排序,当整个序列都基本有序时,对整个序列进行一次直接插入排序,这样效率就提高了。
希尔排序的思想是,先选定一个小于N的整数gap作为第一增量,将所有距离为gap的元素分在同一组,对每一组元素分别进行插入排序,这样就能做到基本有序。然后取比N小的gap重复上述操作,直到gap = 1,相当于对整个序列进行了一次直接插入排序,排序完成。
例如:待排序序列为{9,1,5,8,3,7,4,6},序列长度为8.
整个排序过程如下:
- 令第一增量gap = 8 / 2 = 4,分成4组子序列,对每组子序列分别进行直接插入排序。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OiwlrDLu-1638801062051)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638539722985.png)]](https://img-blog.csdnimg.cn/d8fad0fb8056423dbbd161d13157a754.png)
- 第二增量gap = 4 / 2 = 2,分成2组子序列,对每组子序列分别进行直接插入排序。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VzaygX8F-1638801062051)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638539874285.png)]](https://img-blog.csdnimg.cn/fd103338b17d4736b0be58c5c84a36ed.png)
- 第三增量gap = 2 / 2 = 1,相当于对整个序列进行一次直接插入排序。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gSk6OiME-1638801062052)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638540025549.png)]](https://img-blog.csdnimg.cn/985bbae7c5ae4b22869b31b6e0f0dbb3.png)
- 排序完成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tWdEmjug-1638801062052)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638540073362.png)]](https://img-blog.csdnimg.cn/fb9f16ab7f0a4a2486c1206921b04da1.png)
C++代码如下:
void shellSort(vector<int>& nums) {
int n = nums.size();
int gap = n;
while (gap > 1) {
gap = gap / 2;
for (int i = 0; i < n - gap; ++i) {
int end = i;
int temp = nums[end + gap];
while (end >= 0) {
if (nums[end] > temp) {
nums[end + gap] = nums[end] ;
end -= gap;
} else {
break;
}
}
nums[end + gap] = temp;
}
}
}
希尔时间复杂度为:O(n^⅔)。 终于使得时间复杂度超越了O(n^2)。
直接插入排序空间复杂度为:O(1)。
6.0 了解O(NlogN)算法的基础知识
递归过程:递归过程是一个多叉树,计算所有树的结点的过程就是利用栈进行后序遍历,每个结点通过自己的所有子结点给自己汇总信息之后才能继续向上返回,栈空间就是整个树的高度。
例题①用递归方法找一个数组中的最大值。
int process(vector<int> &nums, int L, int R) {
if (L == R) {
return nums[L];
}
//>>操作是位运算,向右整体移一位,相当于除2,速度比出发运算要快。
int mid = L + ((R - L) >> 1);
int leftMax = process(nums, L, mid);
int rightMax = process(nums, mid + 1, R);
return max(leftMax, rightMax);
}
int main() {
vector<int> nums{3, 2, 5, 6, 7, 4};
int max = process(nums, 0, nums.size() - 1);
cout << max;
}
对数组[3, 2, 5, 6, 7, 4]调用process(nums, 0, 5)的递归逻辑图如下图,其中p(a,b)表示process(nums, a, b)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-50j9JZEu-1645673174621)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1645586313830.png)]](https://img-blog.csdnimg.cn/25885edaeaa2424889d5571a442f9e9d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAMTIzWVFI,size_20,color_FFFFFF,t_70,g_se,x_16)
Master公式:
T
(
N
)
=
a
×
T
(
N
/
b
)
+
O
(
N
d
)
T(N)= a×T(N/b)+O(N^d)
T(N)=a×T(N/b)+O(Nd)
T(N)表示目问题的数据规模是N级别的;T(N/b)表示递归子过程的数据规模是N/b的规模; a表示子过程被调用次数;O(N^d)表示剩下的过程时间复杂度。
满足master公式的递归可以用以下公式求解时间复杂度:
- log(b, a) > d -> 复杂度为O(N^log(b, a)})
- log(b, a) = d -> 复杂度为O(N^d * logN)
- log(b,a) < d -> 复杂度为O(N^d)
满足这样过程的递归可以用master公式求解时间复杂度。
如例题①可以用master公式表示为:T(N) = 2 * T(N/2) + O(1)
6.堆排序
6.1大顶堆和小顶堆
堆是具有下列性质的完全二叉树:
- 每个结点的值都大于等于其左右孩子结点的值,称为大顶堆
- 每个结点的值都小于等于其左右孩子的值,称为小顶堆。
- 完全二叉树可以用数组来存储。
如下图的大顶堆和小顶堆
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2OksoP07-1638801062052)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638756626810.png)]](https://img-blog.csdnimg.cn/42df2e6a3d8f42b182aff523618f5a72.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAMTIzWVFI,size_20,color_FFFFFF,t_70,g_se,x_16)
完全二叉树可以用数组来存储,因此完全二叉树的编号对应数组的下标,二叉树的编号结点具有如下性质,对于任意编号索引大于0的结点,有:
- 父结点的编号索引为:(k - 1) / 2。
- 左孩子的编号索引为:2 × k + 1。
- 右孩子的编号索引为:2 × k + 2。
堆的定义用上面的性质来描述的话,则有:
- 大根堆:arr[k] > arr[2 × k + 1] && arr[k] > arr[2 × k + 2]
- 小根堆:arr[k] < arr[2 × k + 1] && arr[2 × k + 1] < arr[2 × k + 2]
6.2heapInsert操作和heapfity操作
①如何把边插入一个数保持变成一个堆?(heapInsert过程)
用户每给一个数,不停向上跟父结点比,如果比父结点大则交换,这样可以保证在插入新的数之后保持形成大根堆。这个过程叫做heapInsert过程。
例:将用户输入给数组的数变成一个大根堆。

//heapInsert过程
//某个数现在处于index位置,继续向上移动
void heapInsert(vector<int>& nums, int index) {
while (nums[index] > nums[(index - 1) / 2]) {
swap(nums[index], nums[(index - 1) / 2]);
index = (index - 1) / 2;
}
}
②如何知道堆中最大值并把它从堆中去掉?
先用一个临时量记录堆第一个元素,就是堆的最大值。将堆最后一个元素放到第一个元素位置,并减少堆长度即heapSize – 1(把堆最后一个元素放到堆第一个元素位置),此时整体可能不是堆,此时需要调整(进行heapify操作)。从头节点(cur)开始,在它的左孩子和右孩子中选择一个最大值,和头节点比较,如果孩子最大值的值比头节点大则交换两者,直到cur结点没有左孩子和右孩子。
如:弹出堆数组[6 3 5 2 3 4]的最大两个值。

//某个数在index位置,能否往下移动
void heapify(vector<int>& nums, int index, int heapSize) {
int left = index * 2 + 1; //左孩子下标
while (left < heapSize) { //下方还有孩子的时候
//两个孩子中,谁的值大,把下标给largest
int largest = left + 1 < heapSize && nums[left + 1] > nums[left] ? left + 1 : left;
//父和较大的孩子之间,谁的值大,把下标给largest
largest = nums[largest] > nums[index] ? largest : index;
if (largest == index) {
break;
}
swap(nums[largest], nums[index]);
index = largest;
left = index * 2 + 1;
}
}
③如何将一个已有的数组变成一个大根堆?
heapify解决的是:如果一个二叉树根节点的左右子树都是一个堆,但是加上根节点就可能不是一个堆,用heapify可以将这种二叉树调整成一个堆。
那么对于一个已有数组,我们只要从后往前进行heapify操作即可将这棵树变成大根堆,即将已有数组变成一个大根堆。
for (int i = nums.size() - 1; i >= 0; --i) {
heapify(nums, i, nums.size());
}
6.3堆排序
堆排序就是利用堆进行排序的方法,升序排序用大顶堆,降序排序用小顶堆(优先级队列其实就是堆结构,默认是小顶堆)。 以升序排序为例,它的基本思想是:
- 将待排序的序列构造成一个大顶堆,此时整个序列的最大值就是堆顶的根结点。
- 将它与堆数组的末尾元素进行交换,此时末尾元素就是最大值。
- 将除了末尾元素的剩余的n - 1个序列重新构造成一个大顶堆,重复上述步骤,便能得到一个有序序列了。
//某个数现在处于index位置,继续向上移动
void heapInsert(vector<int>& nums, int index) {
while (nums[index] > nums[(index - 1) / 2]) {
swap(nums[index], nums[(index - 1) / 2]);
index = (index - 1) / 2;
}
}
//某个数在index位置,能否往下移动
void heapify(vector<int>& nums, int index, int heapSize) {
int left = index * 2 + 1; //左孩子下标
while (left < heapSize) { //下方还有孩子的时候
//两个孩子中,谁的值大,把下标给largest
int largest = left + 1 < heapSize && nums[left + 1] > nums[left] ? left + 1 : left;
//父和较大的孩子之间,谁的值大,把下标给largest
largest = nums[largest] > nums[index] ? largest : index;
if (largest == index) {
break;
}
swap(nums[largest], nums[index]);
index = largest;
left = index * 2 + 1;
}
}
void heapSort(vector<int>& nums) {
if (nums.size() < 2) {
return;
}
//相当于把数组变成大根堆
for (int i = 0; i < nums.size(); ++i) { //O(N)
heapInsert(nums, i); //O(logN)
}
int heapSize = nums.size();
swap(nums[0], nums[--heapSize]);
while (heapSize > 0) { //O(N)
heapify(nums, 0, heapSize); //O(logN)
swap(nums[0], nums[--heapSize]); //O(1)
}
}
int main() {
vector<int> nums{ 3, 2, 5, 6, 7, 4 };
heapSort(nums, 0, nums.size() - 1);
for (int i : nums) {
cout << i << " ";
}
}
//输出结果为: 2 3 4 5 6 7
7.归并排序
如果我们统计全国收入中位数、最大值等,一般中央都要划到各个省,各个省又要划到各个市,各个市又划到各个街道分开统计各自的一小部分数据,然后逐渐合并到中央,就得到了全国的数据。归并排序的思想也是如此。
归并排序:
- 整体就是一个简单的递归,左边排好序、右边排好序、让其整体有序
- 让其整体有序的过程中用了外排序方法(即merge函数的过程)
如:序列{16,7,13,10,9,15,3,2}进行归并排序。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Lfpd3wO-1638801062057)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1638780360804.png)]](https://img-blog.csdnimg.cn/2613e12a8e99495d8c6ebf001b3ef345.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAMTIzWVFI,size_20,color_FFFFFF,t_70,g_se,x_16)
C++代码如下:
void merge(vector<int>& nums, int L, int M, int R) {
vector<int> help(R - L + 1, 0);
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R) {
help[i++] = nums[p1] <= nums[p2] ? nums[p1++] : nums[p2++];
}
while (p1 <= M) {
help[i++] = nums[p1++];
}
while (p2 <= R) {
help[i++] = nums[p2++];
}
for (i = 0; i < help.size(); ++i) {
nums[L + i] = help[i];
}
}
void mergeSort(vector<int>& nums, int L, int R) {
if (L == R) {
return;
}
int mid = L + ((R - L) >> 1);
process(nums, L, mid);
process(nums, mid + 1, R);
merge(nums, L, mid, R);
}
int main() {
vector<int> nums{ 3, 2, 5, 6, 7, 4 };
process(nums, 0, 5);
for (int i : nums) {
cout << i << " ";
}
}
//输出结果为: 2 3 4 5 6 7
归并排序时间复杂度为:O(nlogn)。
归并排序空间复杂度为:需要一个临时空间存放归并好的区间的数据。
归并排序是一种稳定排序。
8.快速排序
7.1荷兰国旗问题
①问题1: 给定一个数组arr和一个数num,将小于等于num的数放在数组的左边大于num的数放在数组的右边(不要求有序)。要求额外空间复杂度为O(1),时间复杂度为O(N)。
遍历数组元素,根据以下两种情况处理:
- 当前数nums[i] < =num,nums[i]和≤区的下一个数交换,≤区右扩,i++
- 当前数nums[i]>num,i++
【例】给定数组nums[3 5 6 7 4 3 8],给定一个数num
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U0QQuWks-1657523204085)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1657507064673.png)]](https://img-blog.csdnimg.cn/920aae9d231347479b7184132ed34d4b.png)
【代码如下】
void process(vector<int> &nums, int target) {
int less = -1; //小于等于区
for (int i = 0; i < nums.size(); ++i) {
if (nums[i] <= target) {
swap(nums[++less], nums[i]);
}
}
}
②问题2:(荷兰国旗问题): 给定一个数组arr和一个数num,将小于num的数放在数组的左边,等于num的数放在数组的中间,大于num的数放在数组的右边。要求额外空间复杂度为O(1),时间复杂度为O(N)。
遍历数组元素,根据以下两种情况处理:
- 当前元素nums[i]<num,[i]和<区下一个交换,<区右括,i++
- 当前元素nums[i]==num,i++
- 当前元素nums[i]>num,[i]进而>区前一个交换,>区右扩,i不变
【例】给定数组nums[3 5 6 7 4 3 8],给定一个数num
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BrfYnFfU-1657523204087)(C:\Users\ThinkStation K\AppData\Roaming\Typora\typora-user-images\1657508917094.png)]](https://img-blog.csdnimg.cn/74c3ce60d9c34ad48d32b30de9f6e4e0.png)
【代码如下】
void process(vector<int> &nums, int target) {
int less = -1, more = nums.size();
for (int i = 0; i < more; ++i) {
if (nums[i] < target) {
swap(nums[++less], nums[i]);
} else if (nums[i] == target) {
continue;
} else {
swap(nums[--more],nums[i]);
i--;
}
}
}
7.2快排1.0版本
选择[L, R]范围上的最后一个元素为target,在[L,R]上大于等于target或小于target分为小于等于区和大于区。此时小于区的最后一个元素已经排序完成,分别在小于区和大于区递归调用。
【代码】
//在[L,R]范围上划分小于等于区和大于区
int process(vector<int>& nums, int L, int R) {
int less = L - 1; //小于等于区左边界
//从L到大于区左边界遍历,分为两种情况处理
for (int i = L; i <= R; ++i) {
if (nums[i] <= nums[R]) {
swap(nums[++less], nums[i]);
}
}
return less;
}
void quickSort(vector<int>& nums, int L, int R) {
if (L >= R) {
return;
}
int target = nums[R];
int mid = process(nums, L, R);
quickSort(nums, L, mid - 1);
quickSort(nums, mid + 1, R);
}
7.3快排2.0版本
利用荷兰国旗,在[L,R]范围上选择最后一个元素最为target,在[L,R]上根据大于target、小于target、等于target分出大于区、小于区、等于区,此时等于区的元素排序已经完成,分别在小于区和大于区递归调用。对比1.0版本,由于多了等于区,如果重复元素比较多,将比1.0版本省去很多比较步骤。
【代码】
//在[L,R]范围上划分小于区等于区大于区。
//返回数组vec长度为2,vec[0]是等于区左边界,vec[1]是等于区右边界
vector<int> process(vector<int>& nums, int L, int R) {
int less = L - 1, more = R + 1;
int target = nums[R];
vector<int> res(2);
for (int i = L; i < more; ++i) {
if (nums[i] < target) {
swap(nums[++less], nums[i]);
} else if (nums[i] == target) {
continue;
} else {
swap(nums[--more], nums[i--]);
}
}
res[0] = less + 1;
res[1] = more - 1;
return res;
}
void quickSort(vector<int> &nums, int L, int R) {
if (L >= R) {
return;
}
vector<int> vec = process(nums, L, R);
quickSort(nums, L, vec[0] - 1);
quickSort(nums, vec[1] + 1, R);
}
7.4快排3.0版本
在2.0的基础上随机选取一个元素作为target。对比2.0版本,如果完全倒序,时间复杂度将退回O(N^2),而采用随机选取元素将会保持时间复杂度为O(NlogN)。
//在[L,R]范围上划分小于区等于区大于区。
//返回数组vec长度为2,vec[0]是等于区左边界,vec[1]是等于区右边界
vector<int> process(vector<int>& nums, int L, int R) {
int less = L - 1, more = R + 1;
int select = L + rand() % (R - L + 1);
int target = nums[select];
vector<int> res(2);
for (int i = L; i < more; ++i) {
if (nums[i] < target) {
swap(nums[++less], nums[i]);
}
else if (nums[i] == target) {
continue;
}
else {
swap(nums[--more], nums[i--]);
}
}
res[0] = less + 1;
res[1] = more - 1;
return res;
}
void quickSort(vector<int>& nums, int L, int R) {
if (L >= R) {
return;
}
vector<int> vec = process(nums, L, R);
quickSort(nums, L, vec[0] - 1);
quickSort(nums, vec[1] + 1, R);
}















 1944
1944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









