






Apache Paimon PMC 正式发布 Apache Paimon 0.8.0 版本。共有 47 人参与了该版本的开发,并完成了 350 多条提交。感谢所有贡献者的支持!
此版本是 Paimon 毕业成为 Apache 顶级项目后第一个发布,包含了大量新增的功能,此公告也是 Paimon 发布公告中最长的一篇。
01
01
版本综述
Paimon 的长期规划是成为统一的湖存储格式,满足时效分钟级大数据主流需求:离线批计算、实时流计算、OLAP 计算。此版本值得注意的改动有:
新增 Deletion Vectors,近实时更新与极速查询
调整 Bucket 默认值为 -1,提升新学者的易用性
新增通用文件索引机制,提升 OLAP 查询性能
优化读写流程的内存及性能,减少 IO 访问次数
Changelog 文件单独管理机制以延长其生命周期
新增基于文件系统的权限系统,管理读写权限
02
01
Deletion Vectors
Paimon 的 Deletion Vectors 模式可以让你的主键表 (配置 'deletion-vectors.enabled' 为 'true'),在不损失太大写入更新性能的同时,获得极大的读取性能提升,达到近实时更新与极速查询的效果。
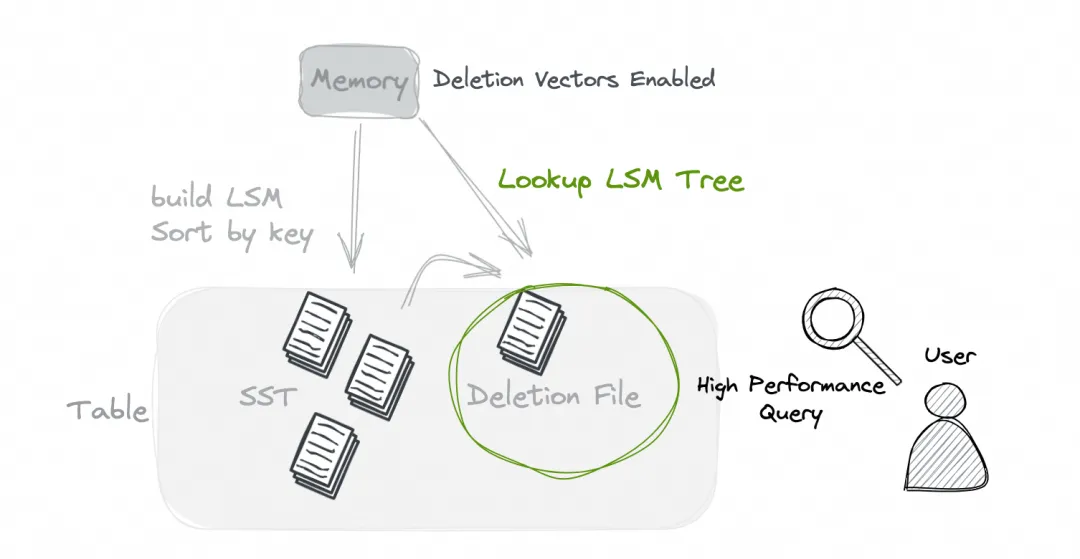
此模式会在 checkpoint 时做更多的工作以生成 Deletion 文件,所以推荐你的 Flink 流写作业有更大的 'execution.checkpointing.timeout' 值,以避免 checkpoint 超时。
使用最新 0.8.0 版本的 paimon-flink、paimon-spark、paimon-hive、paimon-trino 都能享受到此功能带来的查询性能的优化,starrocks 的集成会在 3.2.8 & 3.3.2 版本里包含。
推荐大部分主键表都开启此功能。
03
01
Bucket 默认值
CREATE TABLE T (
k INT PRIMARY KEY NOT ENFORCED,
v0 INT,
v1 INT
);对于以上的 SQL 创建表,Paimon 在过去的版本里使用了 bucket 为 1 的默认值,这导致部分新学者使用单并发的方式来测试 Paimon,这会有比较大的瓶颈,此版本将 bucket 调整为 -1:
对于主键表:bucket 为 -1 使用动态 bucket 模式,这会比固定 bucket 值多一些写入的消耗,不过它以方便的配置带来了分布式的处理。
对于 Append 表:bucket 为 -1 是可伸缩的模式,它有更好更方便的分布式处理。
此改动将大幅提升体验,不用配置任何参数的情况下,Paimon 能覆盖大部分场景。对于兼容性问题,老版本的表将继续默认使用 Bucket 为 1 的配置,只有新创建的表会受影响。
04
01
通用文件索引
此版本前,你可以使用 ORC 自带的索引机制来加速查询,但是它只支持 Bloomfilter 等少数索引,而且你只能在写入文件时生成好对应的索引。
为了解决这些问题,此版本提出了 Paimon 的通用文件索引 (配置 'file-index.bloom-filter.columns'),它会单独维护索引文件:
不止支持字段的索引,还支持对 Map Key 的索引构建。
计划支持随时构建已存在文件的索引,这可以避免你新增索引时去重写数据文件。
计划在后续的版本中,新增 Bitmap,N-Gram BloomFilter,倒排等索引。
目前的通用文件索引只是完成了基础框架,且只支持 Append 表,还需要在后续版本中继续改进。
05
01
读写性能优化
此版本中优化了读写关键链路的性能:
Write 性能优化:
优化了写入时的序列化性能,对于整体写有着 10-20% 的性能提升
大幅提升了 Append Table 多分区写入 (超过5个分区) 的性能问题
加大了 'num-sorted-run.stop-trigger' 的默认值,它会减缓反压
优化了动态 Bucket 写入的启动性能
Commit 性能优化:
大幅降低 Commit 节点的内存占用
去除了 Commit 里面无用的检查,write-only 的提交会快很多
Partition Expire 的性能得到大幅提升
查询性能优化:
大幅降低生成 Plan 时的内存占用
降低了 Plan 以及 Read 阶段对文件系统 Namenode 的访问,这也有利于对象存储的 OLAP 性能
Codegen 支持了 Cache,这将有效提升短查询的性能
通过序列化 Table 对象,Hive 查询大幅降低了访问文件系统 Namenode 的频率
大幅提升了 first_row merge-engine 的查询性能
06
01
Changelog 生命周期
在之前的版本中,对于主键表,Table 的默认 Snapshot 保存时间是1小时,这意味着1小时前的 Snapshots 将会被过期,这会严重影响流读的安全性,流读此表的作业不能挂起超过1小时,否者它会消费已经过期的 Snapshot,它将不能被恢复。
解决办法可以是在流读的作业中配置 consumer-id,写表的作业在决定快照是否已过期时,会查看文件系统中表的所有 consumers,如果仍有使用者依赖于此快照,则此快照将不会在过期时删除。但是,consumer 需要一些管理操作,而且不同的作业需要配置不同的 consumer id,需要一些管理成本。
此版本中,提出了一些新的解法,它可以让 Paimon 表像一个真正的队列一样,保存比较长时间的 Changelog。实际上,我们不能保存太多 Snapshot 的原因是 Snapshot 里面包含了多版本的 Compaction 的结果文件,它是非常大的,占用比较大的空间,而我们流读只需要 Changelog 文件,所以我们可以分离 Changelog 的生命周期:

当 Snapshot 过期时,我们建立对应的 Changelog,把多版本的 Compaction 文件删掉,只保留 Changelog 文件。这样你可以设置1天的 Changelog 生命周期。
CREATE TABLE T (
k INT PRIMARY KEY NOT ENFORCED,
...
) WITH (
'changelog-producer'='input',
'changelog.time-retained' = '1 d'
)目前版本只支持 Changelog 文件,所以需要你配置 changelog-producer 才能生效。
07
01
权限管理系统
此版本中,Paimon 提供了一个基于文件的权限系统。权限决定哪些用户可以对哪些对象执行哪些操作,这样你就可以用细粒度的方式管理表访问。目前,Paimon 采用基于身份的访问控制(IBAC)权限模型,权限直接分配给用户。
CREATE CATALOG `my-catalog` WITH (
'type' = 'paimon',
-- ...
'user' = 'root',
'password' = 'mypassword'
);
-- create a user authenticated by the specified password
-- change 'user' and 'password' to the username and
-- password you want
CALL sys.create_privileged_user('user', 'password');
-- you can change 'user' to the username you want, and
-- 'SELECT' to other privilege you want
-- grant 'user' with privilege 'SELECT' on the whole
-- catalog
CALL sys.grant_privilege_to_user('user', 'SELECT');
-- grant 'user' with privilege 'SELECT' on database my_db
CALL sys.grant_privilege_to_user('user', 'SELECT', 'my_db');
-- grant 'user' with privilege 'SELECT' on table my_db.my_tbl
CALL sys.grant_privilege_to_user('user', 'SELECT', 'my_db', 'my_tbl');此权限系统并不能防止老版本的访问,请升级所有的引擎到新的 Paimon 版本,权限系统才会生效。
08
01
其余核心功能
支持创建 Tag 时的 TTL 指定,这可以让你更随意的创建 Tag 来进行安全的批读
新增记录级别 TTL 配置 (record-level.expire-time),数据的 Expire 会在 Compaction 时进行,这可以通过淘汰过期数据来有效减少 Compaction 的压力
聚合函数 collect, merge_map, last_value, nested_update 支持了 retraction (DELETE / UPDATE_BEFORE) 消息的输入,具体使用请结合你的场景来测试
Sequence Field 重新设计,当两条数据的 Sequence Field 相等时,使用进入 Paimon 的先后顺序来决定顺序
新增了一种 Time Travel 方式,可以指定 Watermark 的批读
文档调整:Flink 和 Spark 有单独目录,包括和读、写、表管理等页面,希望大家喜欢
系统表:大幅提升了 files & snapshots & partitions 系统表的查询性能和稳定性
ORC:大幅提升 ORC 复杂类型 (array, map) 的写入性能;支持了 zstd 压缩,这是我们非常推荐的高压缩的算法
09
01
Flink
DataStream API
老版本并没有提供 DataStream API,建议大家去使用 Table API 与 DataStream 的互转来编写代码,但是,它是有一些难以解决的问题,比如用户希望在写入 Paimon 的同时,边路写入其它的 DataStream Sink,Table 互转的方式难以解决此问题,所以此版本提出了完整的 DataStream API:
FlinkSinkBuilder: 构建 DataStream Sink
FlinkSourceBuilder:构建 DataStream Source
我们依然不推荐你直接使用 DataStream API,建议优先使用 SQL 来解决你的业务问题。
Lookup Join
Flink Lookup Join 在此版本中使用 Hash Lookup 来获取数据,这可以避免 RocksDB 的数据插入带来的开销。
此版本也继续提升了 Hash Lookup,支持了压缩,并且默认为 lz4,changelog-producer 为 Lookup 也会由此受益。
并且 Flink Lookup Join 引入了 max_pt 模式,这是一种有趣的模式,它只会去 Join 最新的分区数据,这比较适配每个分区都是全量数据的维表。
目前 Flink Lookup Join 仍然值得去提升,比如目前并没有按照维表的主键去 Shuffle 主表的数据,目前的 Cache 利用率非常不友好,这会导致大量的 IO,这是 Flink 下个版本需要解决的问题。
其它 Flink 改动
批读分区表的性能得到大幅提升,之前由于设计问题,导致每次批会去扫描所有分区,目前已移除
Metrics 系统重新设计,移除了分区及 Bucket 级别的 Metrics,这会导致 Flink JobManager 长时间运行会发生 OOM
引入 commit.force-create-snapshot,强制生成 snapshot,这可以让某些业务强依赖 Snapshot 的生成
增强 Sort:引入 Hilbert Sort,这种 Sort 在字段超过5个时仍然会有一定效果,而 z-order 只推荐排序字段在5个内;Sort 新增 Range 策略,这可以避免由于行大小不一致导致的排序倾斜问题
CDC Ingestion 的时间函数支持了对 Epoch Time 的处理
优化了 Flink 指定 consumer-id 流读的扩展性以支持多分区的流读
对接了 Flink 1.19,COMPACT Procedure 支持了 Named Argument,我们遗憾的决定,由于维护了超过5个版本,不再支持 Flink 1.14,推荐使用 Flink 1.17+ 版本
10
01
Spark
Spark 继续优化了查询性能,支持表级别的统计信息的生成与使用。
Spark 使用 COW 技术支持了 Append 表的 DELETE 与 UPDATE,Spark DELETE 也支持了所有 MergeEngines 的主键表。Spark DELETE 和 UPDATE 也支持 subquery 的条件。Spark COMPACT Procedure 支持了 where 的方式。
其它一些改动是:
Spark Generic Catalog 支持了 function 相关功能
Delete Tag Procedure 支持了删除多个 Tags 的能力
遗憾的决定,由于维护了超过5个版本,不再支持 Spark 2,推荐使用 Spark 3.3+ 版本
11
01
生态与关联项目
Hive 迁移:支持了迁移整个 Hive Database 库到 Paimon
引入 Jdbc Catalog,这可以让你的业务摆脱 Hive Metastore 的依赖
Hive Writer 支持了 Tez-mr 引擎,我们目前只推荐 Hive Writer 在小数据量时使用
Paimon-Trino 最新版本只支持了 Trino 420+ 的版本,但是查询 orc 的性能得到大幅提升。
Paimon-Webui 项目研发有了比较大的进展,即将发布。
12
01
关于 Paimon
微信公众号:Apache Paimon ,了解行业实践与最新动态
官网:https://paimon.apache.org/ 查询文档和关注项目
希望大家都去项目 Github 页面点个 Star,你的支持是 Paimon 社区研发的动力


















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









