






摘要:本文撰写自某新能源企业的研发工程师 单葛尧 老师。本文详细介绍该新能源企业的大数据平台中 CDC 技术架构选型和 Flink CDC 的最佳实践。主要有以下几个内容:
CDC 方案选型
方案落地实施
平台的优越性
后续规划
我们是一家专注于新能源动力电池制造的企业,致力于推动能源技术的发展与应用。作为一家具有多年行业经验的企业,我们在新能源领域积累了深厚的技术实力和市场认知,业务涵盖了新能源产业链的关键环节。从上游的装备制造到下游的应用解决方案,为客户提供了全方位的服务。
随着企业业务的不断发展,对数据实时性的要求日益提高。如何管理复杂的 Flink 任务,提高任务的开发效率,降低任务的运维难度,成为我们亟待解决的问题。接下来,我将介绍在我们团队在新能源制造业中大数据平台 CDC 技术架构的选型和 Flink CDC 的最佳实践。
一、CDC 方案选型

目前,我们团队规划的数据平台架构如上图所示,数据源这一层主要以 Oracle 为主,且跨网络的分散在各个基地,考虑到数据源支持和时效性,我们需要支持 Oracle CDC 数据采集,结合我们的业务场景,我们调研了实时采集的如下方案:
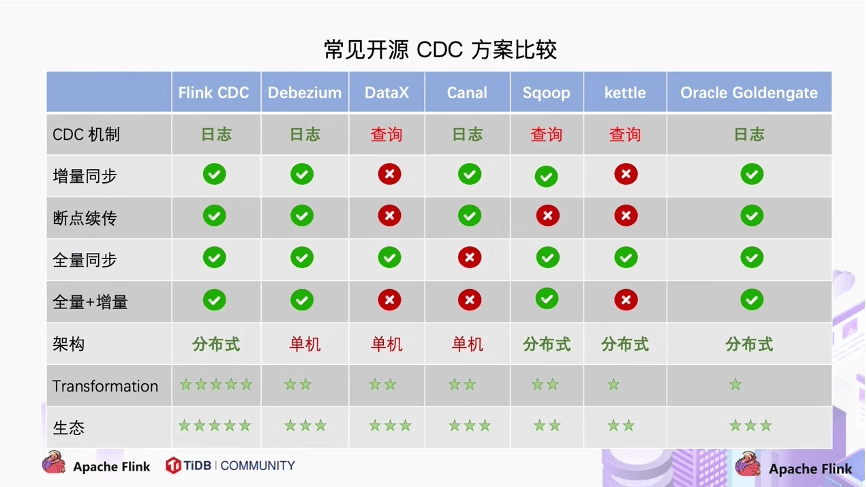
如上图所示,从 CDC 机制、增量同步、断点续传、全量同步、全量+增量、架构、数据计算、生态这八个方面做了对比,可以看出其中的佼佼者主要是 Flink CDC 和 Oracle OGG 以及 Debezium。
首先,让我们了解这三种技术的基本概况。Flink CDC 是 Apache Flink 的一个官方子项目,它利用流处理能力来捕获和转换源数据库的变更事件。OGG 是 Oracle提供的一种成熟的商业化 CDC 技术,广泛用于数据复制和实时数据分析。Debezium则是一个开源的分布式 CDC 系统,支持多种数据库和消息中间件,易于扩展和集成。
从实现机制上来看,Flink CDC 依赖于数据库的日志或 redo log来捕捉变更,并通过Flink的流处理引擎进行后续处理。它的优势在于与 Flink 生态的无缝整合,为批处理和流处理提供了统一的解决方案。此外,Flink CDC 支持丰富的转换和处理功能,如窗口操作、状态管理和时间处理,这对于复杂的实时分析场景非常有益。然而,它的局限性也较为明显,即对源数据库的依赖性较强,需要特定的日志格式或访问权限。
OGG 作为一种成熟的商业产品,提供了强大的数据捕获和传输能力。它通过解析源数据库的日志文件来捕获变更,并能够在不同的系统之间高效地传输数据。OGG 的优势在于其稳定性和广泛的兼容性,尤其是在处理大规模数据和高并发场景时表现出色。但是,OGG 的成本较高,且对于开源生态系统的支持不如其他方案那么丰富。
Debezium 则采用了不同的方法,它直接连接到数据库,通过订阅 binlog 或 redo log 来捕获变更事件。Debezium 的特点是其灵活性和易用性,支持多种数据库类型,并且可以方便地与 Kafka 等消息中间件集成。这使得 Debezium 非常适合于多源异构环境下的数据同步和实时分析。但是,Debezium 的性能可能不如Flink CDC和 OGG 那样出色,尤其是在处理大量数据时可能需要更多的优化工作。
在应用场景方面,Flink CDC 适合于需要复杂事件处理和流式分析的场景,尤其是那些已经采用Flink作为流处理平台的组织。OGG 则更适合于对稳定性和性能有极高要求的大型或关键任务应用。而 Debezium 由于其灵活性和易用性,适用于需要快速开发和部署CDC解决方案的场景,尤其是面对多样化的数据源和技术栈时。
此外,考虑到 OGG 成本高,链路长,且文档资源少,而 Debezium 配置复杂,而且在后续大数据流量或存在复杂的计算逻辑时难以为继,最终我们选择了 Flink CDC 作为 Oracle 的实时采集的工具方案。
二、方案落地实施:
我们团队在 Flink CDC 中的实施落地主要分为以下几步:
- 确保 Oracle 日志归档模式开启,开通 Oracle 整库补充日志,开通表级别的全列补充日志。
- 赋予操作用户各类权限,如表的操作权限,logminer 与 archive log 相关视图查询权限等。
- 开启跨基地网络权限,打通 Hadoop 集群对 Oracle 的访问权限。
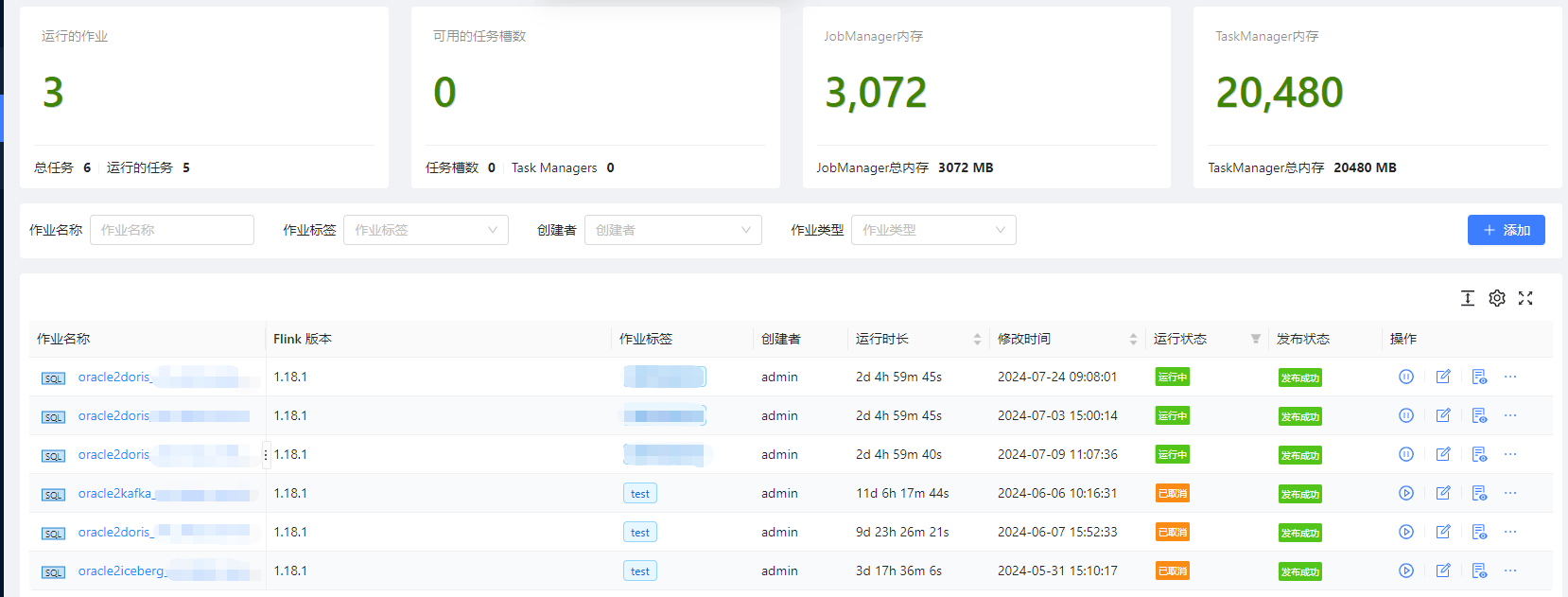
- 通过平台编写 Flink SQL 任务,将 Oracle 的数据直接存入到 Doris 中,下图为线上作业效果图。
开发的过程中虽然整体顺利,但也遇到了几个小插曲,在此与各位读者一起分享
- 该配置开启了 Oracle 日志在线挖掘模式,如果没有这个设置,会导致生产环境默认策略读取 log 较慢,且默认策略会写入数据字典信息到 redo log 中导致日志量增加较多。但该配置也有缺点,不写入数据字典到 redo log 中,会导致无法处理 DDL 语句。
'debezium.log.mining.strategy'='online_catalog',
'debezium.log.mining.continuous.mine'='true'
- 我们在同步 Oracle11g 的数据时,遇到了报错
Caused by: io.debezium.DebeziumException: Supplemental logging not configured for table xxx. Use command: ALTER TABLE xxx ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
该错误是因为对于 Oracle11 版本,Debezium 会默认把 tableIdCaseInsensitive 设置为 true, 导致表名被更新为小写,因此在 Oracle 中查询不到 这个表补全日志设置,导致误报这个 Supplemental logging not configured for table 错误”,我们只需要开启如下设置即可
'debezium.database.tablename.case.insensitive'='false'
- 我们的任务在运行一段时间后报错
Caused by: com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.DataException: file is not a valid field name
这是因为 schema change event parsing 导致的问题,已经在3.1版本得到了解决,下载3.1版本的包即可,详见Flink CDC 项目的 PR #2315。
- Flink Oracle CDC connector在采集分区表的时候存在问题,报错为
Caused by: io.debezium.DebeziumException: The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot
这是由于分区表未能被成功扫描到,我们进入到源码的类 OracleConnectionUtils 中可以看到
String queryTablesSql = "SELECT OWNER ,TABLE_NAME,TABLESPACE_NAME FROM ALL_TABLES WHERE TABLESPACE_NAME IS NOT NULL AND TABLESPACE_NAME NOT IN ('SYSTEM','SYSAUX') AND NESTED = 'NO' AND TABLE_NAME NOT IN (SELECT PARENT_TABLE_NAME FROM ALL_NESTED_TABLES)";
其中如果需要加入分区表的话,要在where条件中加入 PARTITIONED = ‘YES’,重新编译打包即可解决该问题。
当然写入Doris的速度也可能存在慢的现象,特别是 StreamLoad 中进程 stopped 与返回 loadResult 结果之间时间较长时的问题,得益于 Apache Doris 社区的帮助,我们总结以下几点优化方案:
-
看BE的资源是不是满了,检查 IO、CPU、内存
-
换成 2pc 导⼊,⾮ 2pc 会等待 publish,2pc 导⼊ publish 是异步的
-
mow 尝试换成 mor 表
-
show proc ‘/transactions’ 看看事务的状态,如果都是 committed,说明 publish 卡住了,如果 io 不⾼,可以增加 publish 的线程和超时
publish_version_timeout_second=60
publish_version_worker_count=16
- 增加 be.conf 的配置 ,适当提⾼下⾯的参数的配置
doris_scanner_thread_pool_thread_num=1024
webserver_num_workers=1024
fragment_pool_queue_size=4096
fragment_pool_thread_num_max=2048
doris_max_remote_scanner_thread_pool_thread_num=2048
三、平台的优越性:
此外 Apache StreamPark 也给我们带来了很多惊喜,在开发 FlinkSQL 任务的过程中,借助 StreamPark,极大的提升了开发时的效率,我罗列了我们开发团队觉得非常优秀的点:
1. 多版本Flink管理
在开发过程中,可能会因为需求Flink新版本的某项能力,或是某些组件对 Flink版本的强需求而引入多版本的 Flink,在 StreamPark 中,只需要配置一个 Flink 的路径并为其命名,即可在开发任务中轻松地选择我所需要的 Flink 版本。

2. 对于Git的集成
我们在引入 Apache Dolphinscheduler 时,曾多次接到数仓团队表明调度系统未能接入版本控制的遗憾,但在引入实时平台时,这个遗憾被弥补了。StreamPark 的 Git 式项目管理,极大的简化了我们在编写 JAR 后复杂的部署链路,一键编译、部署、配置,一气呵成。
3. 强大的作业运维能力及告警机制
StreamPark 有着完善的作业操作记录,可以清晰的记录所有任务 Release、Start、Cancel 的记录,对于 yarn application 形式的任务,记录了每次运行的 appId,便于后续的 yarn 日志翻阅、运行状态的监测等等。一旦报错,StreamPark 会迅速发送告警,如果配置了重启机制,可以实现分钟级的重启效率。
4. Flink SQL 在线开发
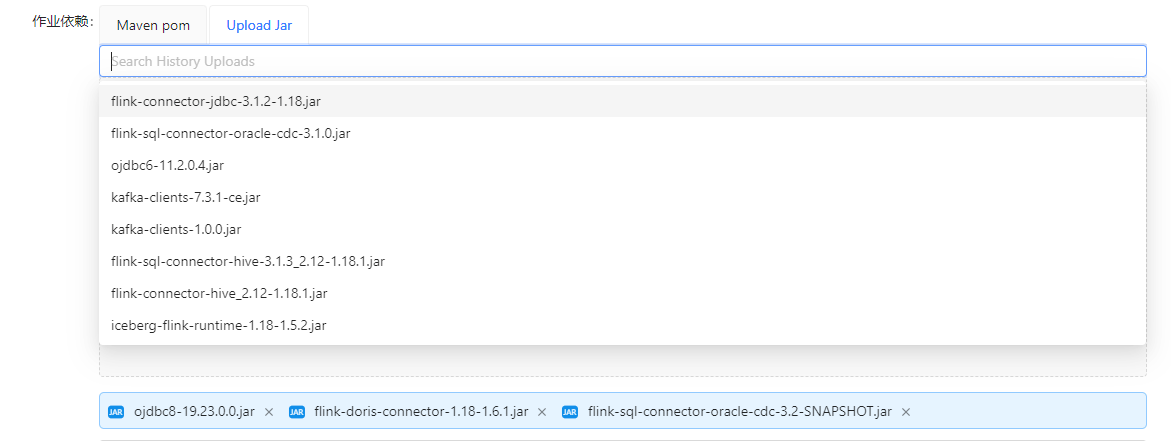
StreamPark 的类 IDE 样式的开发窗口相当优越,可以帮助我们检查低级的语法错误,简单的轻松地便可以配置各类想要配置的参数,如分配 JM、TM 的资源,配置预备提交的 yarn 队列,它的作业依赖配置更是相当简易,提供了填写 pom 和上传 jar 包两种形式,再也无需将包傻傻地通过hdfs上传,极大地提升了我们的开发效率。
四、后续规划:
感谢 Flink CDC,作为 Apache Flink 社区的重点项目,它提供给了我们开箱即用实时数据采集方案,极大的简化了 CDC 的实施过程,也规避了 OGG 昂贵的使用费用。
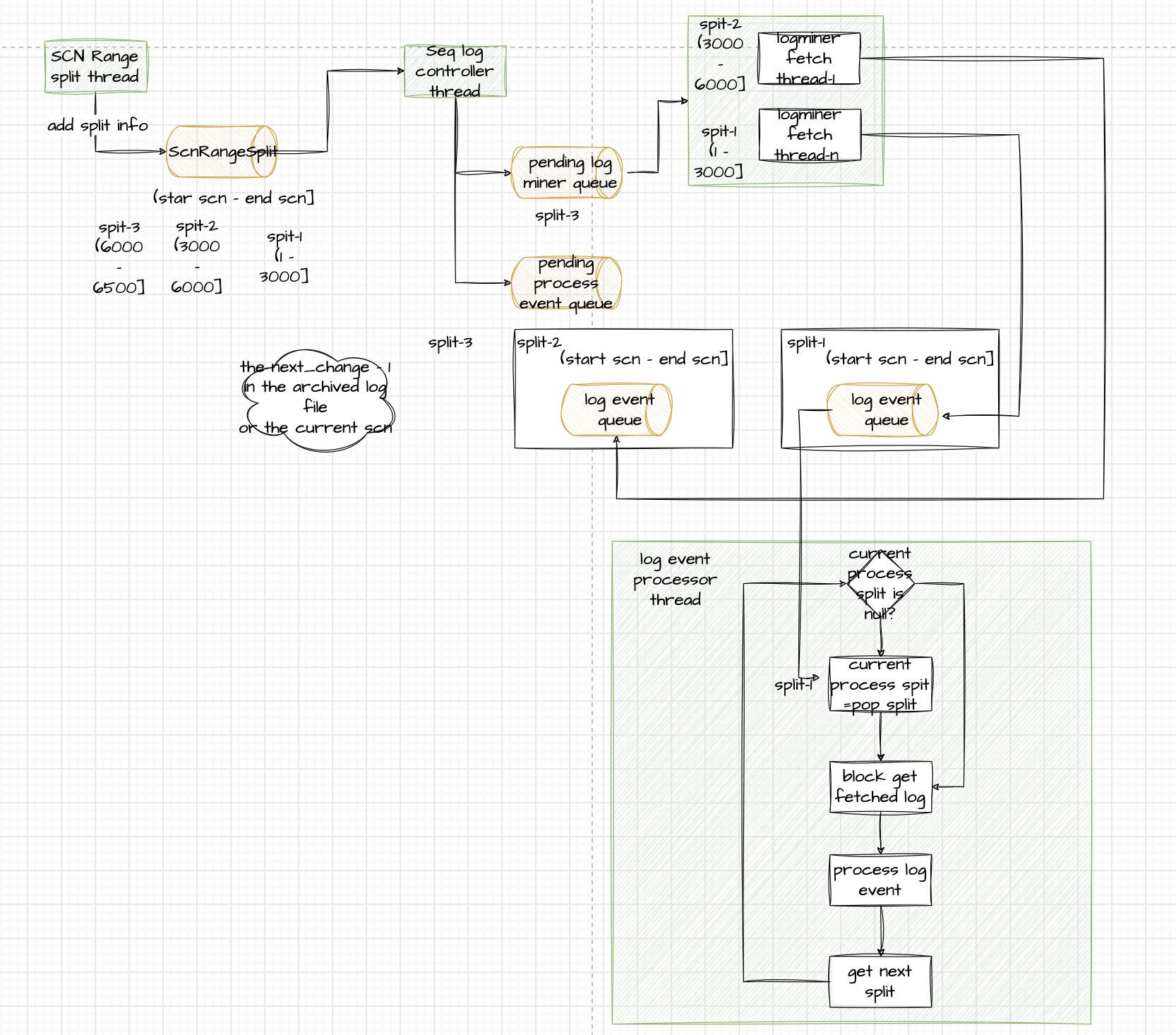
不过目前 Flink CDC Oracle Connector 也存在一些性能问题,众所周知,Oracle CDC依赖Debezium组件解析 Redo Log 与 Archive Log,Debezium 通过Oracle 的 Logminer 解析 Log。最大的问题就在于 LogMiner 的性能限制, 熟悉 Oracle 的开发者会知道,LogMiner是运行在 Oracle 内部, 并且运行在日志落地之后, 不可避免地需要消耗数据库的算力去完成工作, 为了降低这个不在主流程的进程的资源消耗, Oracle 对 LogMiner 做了非常严格的资源限制, 每个 LogMiner 进程, 他的资源消耗都不能超过 1 个 cpu 核心, 在大多数场景下, 这个将 LogMiner 的日志解析速度限制在1w条每秒以下, 在一些制造业的场景下, 这个速度是远远不够的, Oracle 是一个事务数据库, 一个大的 Update, 可能会带来数十万上百万的更新, 在这种情况下, 每秒1w的解析速度会使得下游延迟增大到数分钟级别, 更糟糕的是, 在数据库本身负载较高的情况下, 由于 LogMiner 的解析与数据库共享负载, 会让解析速度进一步下降。
后续团队考虑通过 Oracle 的机制, 将 redo log 异步传输到另外一台没有业务压力的 Oracle 实例上, 然后在另外一台机器上开启并发切分 scn range 事件,开启 LogMiner 线程并发的解析对应 scn range 事件,顺序的处理获取到的事件。
欢迎大家多多关注 Flink CDC,从钉钉用户交流群[1]、微信公众号[2]、Slack 频道[3]、邮件列表[4]加入 CDC 用户社区,以及在 Flink CDC GitHub 仓库[5]上参与代码贡献!
[1] “ Flink CDC 社区 ② 群”群的钉钉群号:80655011780

[2] ” Flink CDC 公众号“的微信号:ApacheFlinkCDC
[3] https://flink.apache.org/what-is-flink/community/#slack
[4] https://flink.apache.org/what-is-flink/community/#mailing-lists















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









