






摘要:本文整理自 Paimon PMC Chair 李劲松老师在 8 月 3 日 Streaming Lakehouse Meetup Online(Pamion x StarRocks,共话实时湖仓架构)上的分享。主要分享 Apache Paimon V0.9 的最新进展以及遇到的一些挑战。
Tips:点击「阅读原文」跳转阿里云实时计算 Flink~
01
Paimon:飞速发展的 2024
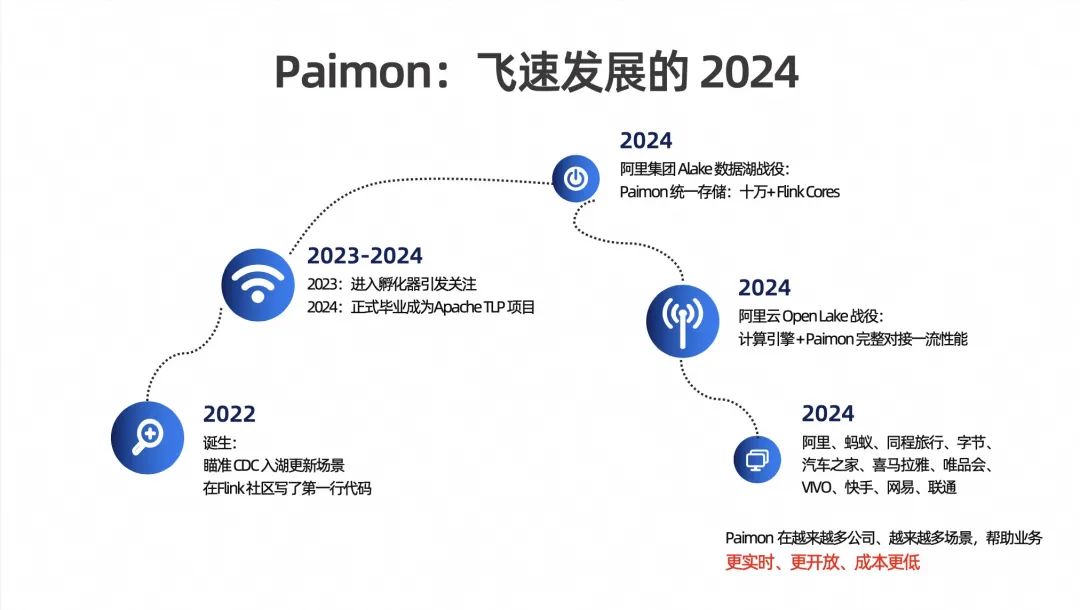
Paimon 诞生于 2022 年的 Flink 社区,并在 2023 年由 Flink Table Store 正式更名为 Apache Paimon,是一个完全由社区推动成长的项目。在短短不到3年的时间里,Paimon 已经有了飞速的发展,并且得到开源社区的一致认可,2023 年 Paimon 进入了 Apache 孵化器,并在 2024 年正式毕业成为了 Apache 顶级项目(TLP)。
如今,包括阿里在内的业界各公司都在积极拥抱 Apache Paimon 社区。2024年,阿里集团启动了Paimon 作为统一存储的 Alake 数据湖战役,目前各大业务方已经大规模上线了与 Paimon 相关的作业。这为阿里内部的业务带来了更加实时化、低成本和流批一体的湖上实时体验。阿里云在同一年启动了 Open Lake 战役,Paimon 与阿里内部各个计算引擎相结合,实现了高性能的读写操作。
目前来自国内各类规模的互联网公司以及其他行业的企业,已经将 Paimon 应用于生产环境中。这些公司通过使用 Paimon,不仅提高了业务的实时性和开放性,还实现了使用成本的降低。
02
Paimon:0.9 Features

预计在八月下旬将发布 Apache Paimon V0.9 版本,包含如上图十几个新功能。
大致面临了三个核心挑战:
第一个是主键表,主键表是 Pamion 一个核心能力,它是区别于 Iceberg 最大一个特点,所以主键表 Native 化查询性能是比较关键的。在0.8版本中,我们引入了 Deletion Vectors,并将在 0.9 版本中进一步巩固这一功能,并且非主键表也支持轻量化的 DELETE & UPDATE。
第二个核心挑战是生态。随着 Paimon 的发展,我们已经看到它在包括阿里在内的各行各业中得到了广泛应用。然而,随着数据湖生态系统的扩展,特别是在国际市场的推广中,我们面临着一些问题。那么,如何才能构建一个更强大的生态系统呢?例如,在 0.9 版本中,我们引入了一个核心功能,即生成 Iceberg Snapshots,使得 Paimon 能够兼容 Iceberg 的生态系统。此外,我们还在与AI结合方面进行了相关尝试,例如 Paimon Python,以及 Paimon-Rust,从而更好地面向 AI 应用。
第三个核心挑战是应对各种业务需求。阿里云主要使用对象存储,这会导致较大的延迟问题。这迫使我们需要解决文件读取和碎片化文件读取的问题。因此,我们优化了对象存储文件 IO,引入了元数据缓存,并修改了默认文件格式与压缩算法。
03
挑战一:更新与查询时合并

Paimon 面临的第一个挑战是更新和查询时合并的“Trade-off”问题。常见的两种模式是 Merge On Read 和 Copy On Write。Merge On Read 模式下,更新速度很快,但查询速度较慢;而 Copy On Write模式下,更新速度较慢,但查询速度较快。目前,许多用户希望在更新和查询之间找到一个平衡点,即希望更新速度快的同时查询速度也不慢,而不是在这两种模式中进行权衡。

为了满足这一需求,从 0.8 版本开始,Paimon 引入了 Deletion Vectors。这是一种 Merge On Write 的模式,通过写时标记老文件哪些行被删除,实现快速更新,同时尽量不影响查询性能。
04
Deletion Vectors
4.1 非主键表
Deletion Vectors 是在 Copy On Write 和 Merge On Read 的基础上实现的一种增量写入技术。
当进行数据更新时,Deletion Vectors 会标记出老文件哪些行的数据被删除,然后在读取数据时,这些标记会被用来过滤掉被删除的行。这样就实现了快速更新,这个就是 Deletion Vectors,一种简单且易于理解的技术。

对应到上图 Insert 就是写新的数据文件,Delete 就是标记老文件,哪些行被删除,Update 就是一个 Delete 和 Insert 的一个组合。通过这样的方式,在写入的时候成本高一点,但是查询的时候它的速度要快很多。
4.2 主键表

那么如何在主键表中融入 Deletion Vectors?Pamion 在这里做出了一些创新的设计,比如如何在 LSM 结构中融入 Deletion Vectors 的维护,原理可以看上图右边的俩张图。
在 LSM 结构当中一般来说数据直接写到 Level 0 即可,但是如果有 Deletion Vectors,就需要在 Level 0 升级和写入 LSM 高层的时候,将它对应的增量数据在高层当中查出来。比如说查询 Level 3 文件中的哪些行被删了,需要维护 Deletion Vectors 的 Bitmap。经过维护之后就会生成如右下图的 Bitmap,生成的对应 Bitmap 可以避免实际重写 Level 3 文件,同时仍然可以高效地查询 Level 3。
在主键表中,利用LSM点查能力来删除数据,并且在 0.9 当中也支持了异步 Compaction。
在这个过程上,Deletion Vectors 能达到的查询效果就是支持过滤下推到文件,也解放了查询的并发限制。而且更为关键的是,它支持了 StarRocks、Doris 等 Native 语言的简单集成。这样 Native 语言就不需要考虑复杂的 Merge,直接基于文件加 Deletion Vectors 即可进行高效的向量化查询。
4.3 测试

上图是来自 StarRocks 社区的一个测试。测试结果表明,即使在比较简单的场景中,性能提升也能达到3到5倍。在更复杂的场景中,性能提升甚至可以达到5到10倍,整体来看性能效果是非常好的。
4.4 计算引擎

Deletion Vectors 已经得到了众多计算引擎的 Native 对接。虽然在0.8版本时还不够完善,但在 0.9 版本之后得到了丰富,并与阿里云的一些产品集成。目前,已经对接了多个计算引擎,包括开源的 StarRocks、Doris,以及阿里云的产品如 Spark Native、Hologres、MaxCompute 和 Flink Native。
05
挑战二:生态

Pamion 的生态系统最初从 Flink Table Store 开始。Flink Table Store 0.1 版本在开发过程中投入了非常少的人力和时间,仅用了两三个月就完成了基本原型。
那么接下来两三年的核心任务就是生态系统的建设。生态系统的建设是一个复杂且缓慢的过程,涉及到多种计算引擎、Metastore、文件系统等各类适配和问题。在人力和资源有限的情况下,就只能选择最重要的计算引擎来覆盖生态系统。
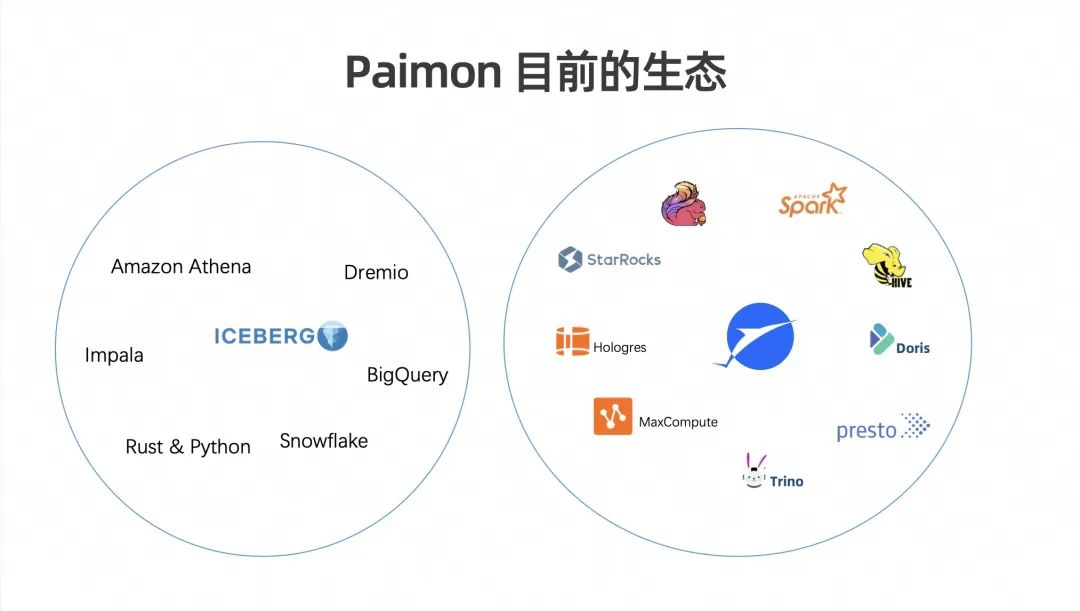
上图右侧的圆圈展示了 Pamion 目前的生态系统。涵盖了多种计算引擎和平台,包括 Flink、Spark、StarRocks、Doris、Presto、Trino、Hive,以及阿里的 Hologres 和 MaxCompute。这些组件涵盖了流处理、批处理和 OLAP,还包括了阿里云自研的一些生态系统。
目前在国外比较流行的这个 Iceberg 有哪些生态呢?上图左边的圆内,包括 Amazon Athena、Dremio、Impala、BigQuery、Snowflake 和丰富的 Rust & Python库。
那这样子对比看来,Pamion 目前的生态系统在大数据计算领域,尤其是在国内的大数据计算领域,表现相对不错。然而,如果将其放在北美市场来看,情况则有所不同。北美拥有各种云计算引擎和众多服务计算厂商,满足了多样化的需求。此外,北美和中国在AI相关需求方面也有显著的差异,而这恰恰是 Pamion 目前所欠缺的领域。
那么如何让 Paimon 也同样拥有这些厂商的支持呢?
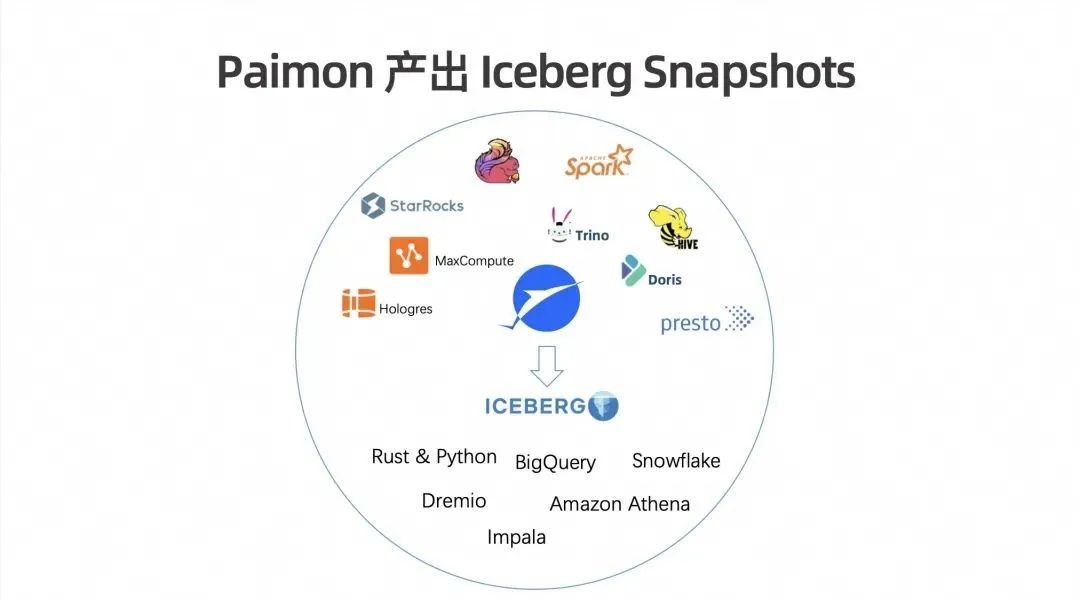
在0.9版本中,Pamion 引入了一个 Feature:Pamion 可以生成Iceberg Snapshots。由于 Iceberg 的大部分架构基础与 Pamion 的湖架构概念非常相似,这为 Pamion 提供了一个机会,即通过原生的Pamion 代码,而不依赖于 Iceberg,直接生成与 Iceberg 兼容的格式。这意味着在每次生成 Snapshots 时,都可以同时生成一份 Iceberg格式的副本。这使得通过Iceberg生态系统(如 BigQuery、Snowflake、Amazon Athena 等)来查询 Pamion 表变得更加简单,有利于 Pamion在北美市场的落地和使用。
然而,仅依靠 Iceberg 生态系统并不能完全展示 Pamion 的所有能力。例如,Pamion 拥有主键表和强大的 Merge Engine 功能,而这些是 Iceberg 表无法完全实现的。因此,Pamion 正在积极发展自己的多元生态系统,以更全面地展示其独特的技术能力和优势。

Pamion 社区最近发起了 Paimon Python 与 Pamion Rust 项目。
Paimon Python 基于 Py4j 封装 Java 实现,提供一个简单的实现,但它的性能却不是最优的。
而 Pamion Rust,一旦推出了第一个版本,就可以很容易地扩展出 Pamion 的 Python 版本。这将解锁 Python 和 Rust 的大部分生态系统,包括与 DataFusion 和DuckDB 的对接,以及 Python 在 AI 和大模型相关领域的应用。由于这些应用大多是用 Python 编写的代码,因此可以直接通过 Python 访问 Pamion 数据。
这种做法的好处是,使 Pamion Python 和 Pamion Rust 的发展,能够尽可能多地展示其独特的功能和优势。当然,不仅仅局限于此,Pamion 的 C++ 版本也在阿里内部孵化中,预计在十月份会推出 Pamion C++ 版本。
06
挑战三:对象存储
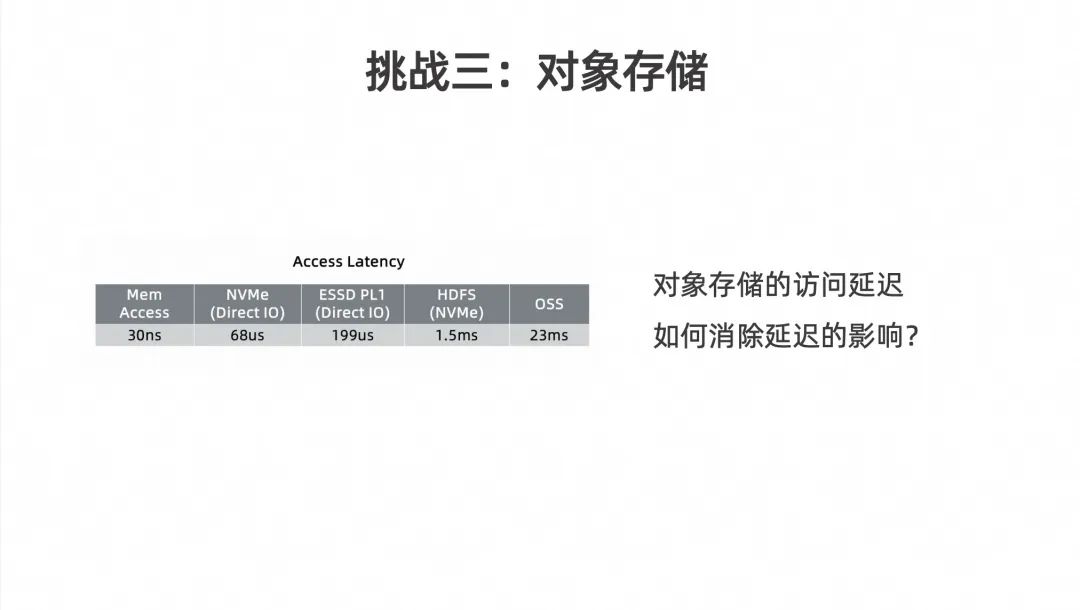
对象存储在运维、可扩展性和存储成本方面都有显著优势,尤其是在云端,它通常是更为经济的选择。因此,大部分阿里云上的业务都是基于对象存储构建的。然而,Pamion 能否直接将对象存储当作 HDFS 来使用,实际上仍存在一些差距。
如上表格展示了来自 Flink 社区的测试结果。表格中,从左到右展示了每次访问(RPS)的速度逐渐变慢的过程。
内存的访问速度是纳秒(ns)级别的;
NVMe 的访问速度是微秒(us)级别的;
ESSD 虽然稍微慢一些,但仍然是微秒级别的。
HDFS 由于是分布式存储,访问速度需要经过网络,因此是毫秒(ms)级别的,通常在一两个毫秒左右。
然而,当我们看 OSS(对象存储服务)时,访问时间显著增加,达到二十几毫秒。
这意味着,如果 Pamion 有大量的小文件和碎片文件,并且需要单机节点去访问这些文件,那么访问速度将成为一个巨大的瓶颈。
所以如何消除 OSS 这种对象存储延迟的影响呢?

首先,在文件格式的选择上,要尽可能选择压缩率更高的格式。在内部和部分外部测试中发现,Parquet 格式的压缩率比 ORC 稍好一些。当然,这取决于具体的测试数据。因此,在0.9版本中,Pamion 将 Parquet 作为默认的开源文件格式。
在阿里云上,经过多年的沉淀,开发出了一种独立于 ORC 的新格式,称为 AliORC。内部测试显示,AliORC 的压缩率比 Parquet 更高。因此,今后在阿里云上推荐使用 AliORC,而在开源版本中则推荐使用 Parquet。
关于压缩算法,Pamion 在0.9版本中将默认压缩算法更改为 ZSTD。测试表明,无论是读写性能还是压缩率,ZSTD 在大部分场景下都优于 GZIP、LZ4 和 Snappy。

最后,在0.9 版本中,Pamion 研发了 Caching Catalog 功能。它会自动维护对 Database 的 Cache 和对 Table 的 Cache 来避免Schema的访问,以及也会自动维护 Manifest 文件的 Cache。经过一些测试发现,对于需要反复读取表的场景,Caching Catalog 能够带来整体性能三倍的提升。
对于0.9 版本,这里仅提及了部分内容。在此,非常感谢各公司开发者朋友们对 Paimon 贡献的各种 Features,使我们的 Paimon 社区变得更加壮大。希望大家继续关注我们 0.9 版本的发布过程,同时也期待大家对后续版本的持续支持和关注。

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
新用户复制下方链接或者扫描二维码即可0元免费试用 Flink + Paimon
了解活动详情:https://free.aliyun.com/?pipCode=sc

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」跳转阿里云实时计算 Flink ~
点击「阅读原文」跳转阿里云实时计算 Flink ~















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









