







手指是一种新的传感技术,通过分析声共振特征可以识别各种细粒度的手姿态。安装在拇指环上的表面换能器向身体注入声啁啾(20Hz到6000Hz)。分布在手腕和拇指上的四个接收器收集着啁啾。手的不同姿势为声啁啾创造了不同的路径,在四个接收器上产生了独特的频率响应。我们演示了手指平如何区分多达22个手部姿势,包括拇指触摸手上的12个指骨,以及10个美国手语姿势。一项有16名参与者的用户研究表明,我们的系统能够识别这两组姿势,准确率分别为93.77%和95.64%。我们讨论了广泛使用这种输入技术的机会和剩余的挑战。
介绍
尽管经过多年的研究和取得了实质性进展,但为可穿戴设备提供适当的输入手段仍然是一个相当大的挑战。持续使用可穿戴设备所需的尺寸和舒适性,以及在以最小难度和最小的难度和注意力的移动环境中操作的需要,使得键盘和触摸屏的选择不那么受欢迎。语音输入是一种可行的选择,但它并不总是最适合社会的解决方案。另一种选择是利用用户的手机作为其可穿戴设备(s)的输入设备。但是,这样的代理(或远程控制)在许多情况下,解决方案会使交互变得过于复杂,因为它需要用户首先去拿手机,这在许多情况下很不方便,比如当手被另一项任务占用时。此外,在某些情况下,用户可能需要以更谨慎的方式输入隐私和社交适宜性,比如在会议期间或与智能家居设备交互,如谷歌Home或亚马逊Alexa。最后,增强现实和虚拟现实的抬头显示器为非语音、无眼睛的输入提供了机会。
鉴于这种方便和社会合适的可穿戴输入解决方案的动机,我们介绍了手指平,一种新的手腕和拇指安装的传感解决方案,以实现单手输入。手指平依赖于检测各种手的结构(例如,拇指触摸指尖),基于这种结构如何影响注入在拇指和在手周围传播的声波的传播。人体是声音传播[20,12]的良好媒介,它的频率响应根据声波通过身体的路径而变化。手的结构的变化,是由手形成各种不同的姿势或手势引起的,为声波创造了足够不同的传播路径。为了利用这种现象来识别不同的手的姿势,手指从拇指底部每秒注射10次声啁啾(20Hz-6kHz)。这些啁啾穿过手,并被拇指和手腕上的麦克风接收。然后对接收到的信号进行分类,以匹配一组已知的姿态。
为了展示手指平的能力,我们设计并评估了两组姿态。第一个姿势集包括拇指敲击四个手指上的12个指骨,可以用于数字输入和T9键盘的潜在的文本输入1。另一组姿势由美国手语的十个数字姿势组成,进一步证明了可靠区分大量简单手姿势的灵活性。请注意,我们的系统可以有效地检测手势输入的端点。然而,分割后的实际数据分析是基于对静态手部配置(姿态)的分类。因此,我们将我们的方法表示为姿势或手的配置识别,而不是手势识别——即使它的目的显然是针对后者。我们的技术在日常活动中,身体上的噪声可能会导致更多的假阳性误差。然而,从日常活动中得出的假阳性可以通过一个可靠的激活姿态来解决。用户可以执行激活姿势来激活系统,然后启用完整的姿势进行识别。我们的技术还可能要求对不同的用户进行额外的校准。可以采用用户校准程序来解决这个问题。更多细节见本文。
本文的贡献是:
- 一种主动的声学感知系统,通过检索和识别在手上产生的声学特征来识别各种手的姿态。
- 单手手姿势集的设计,它将一个标准的12键数字垫映射到手的自然结构,可以用于数字输入和潜在的文本输入。输入的第二个姿势示例是10-10的美国手语姿势集。
- 对两个姿态集的经验评价,结果讨论了实际应用的可行性。
在本文的其余部分中,我们将首先讨论之前的工作,并突出本文的创新和贡献手指ping。然后,我们提出了该系统的基本理论,设计和实现,以及实证评价。在最后一节中,我们将讨论在日常应用中使用这种新技术的挑战和机遇。
相关工作
为可穿戴设备提供适当的输入多年来一直是社区的一个研究课题。各种感知模式和形式因素已经被探索,以改善可穿戴设备的输入体验。在这里,我们根据各种解决方案的形式因素和位置,对这些过去的研究进行了分类。
通过臂章输入
执行手势可以引入或改变手臂区域的各种信号,包括前臂或上臂。为了利用这种现象来识别手指或手势,这些臂章可以检测到不同的信号。[9,14]使用主动和被动声感知识别前臂上的轻拍位置,[17]使用肌电图信号。不幸的是,从用户的角度来看,佩戴臂章很少是一种方便的体验。
通过腰部装置输入
与臂章相比,腕表等腕带佩戴更多,也更方便。因此,许多研究人员开发了腕带式装置来识别手指手势,通过捕捉腕部区域周围的不同类型的变化,包括惯性运动[12,23,12]、计算机视觉[13]、力[5]、接近[8]、电信号[4]或声学信号[19,15,1]。
通过戒指输入
最近,随着可穿戴计算技术(如电池、处理器)的进步,研究人员已经能够在更小的可穿戴输入设备,如环。与腕带式设备类似,在大多数情况下戴戒指也适合社会。此外,由于戒指是戴在手指上的,它可以收集更多的信息,并在一个更好的位置来捕捉手指的姿势。因此,采用不同的传感模式构建的环已被探索用于对手指手势进行分类,如声学和运动传感[21,22]、计算机视觉[2]、磁传感[3,10]或电传感[24]。
所有这些以前的解决方案都涉及到被动感应,也就是说,放置在身体上的传感器是在检测由身体本身或身体外部的某些物质所产生的现象。手指平使用一种主动的声学感知机制来识别手的姿势,这意味着传感器解决方案产生一个动力信号,然后当它沿着手和手腕传播时被感知。主动声学传感也被应用于寻找容器[6]中的内容水平,并区分笔记本电脑和耳机配置[11]。虽然这种解决方案确实需要一个电源来传输和接收(而不是仅仅接收一个被动解决方案),但不同姿态的数量、分辨率和识别精度的提高证明了这种额外的限制是合理的。
手势的设计
在本文中,我们通过识别两组手姿态来证明手指的能力。
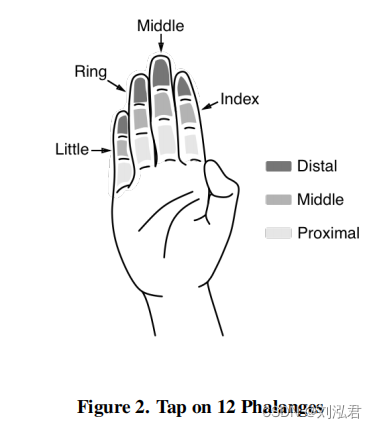
第一组姿势使用户能够通过用拇指触摸食指、中指、戒指和小手指的12个指骨(见图2)中的任何一个来输入数字。由于12个指骨的布局和一个数字板之间的相似性,这种布局可以用来输入数字或可能使用T9键盘输入文本,而不需要大量的精力来记住不同的手势。
第二组姿势是美国手语中的数字“1”到“10”,如图3所示。我们使用这组姿势来展示手指平识别手的各种其他姿势的潜力。此外,识别这组手的姿势可以用于翻译美国手语(ASL)的数字表达,为不懂美国手语的人。例如,已识别的结果可以以音频形式播放,以协助通信。此外,这些姿势还可以作为访问可穿戴电脑中不同功能的快捷方式。

操作的理论依据
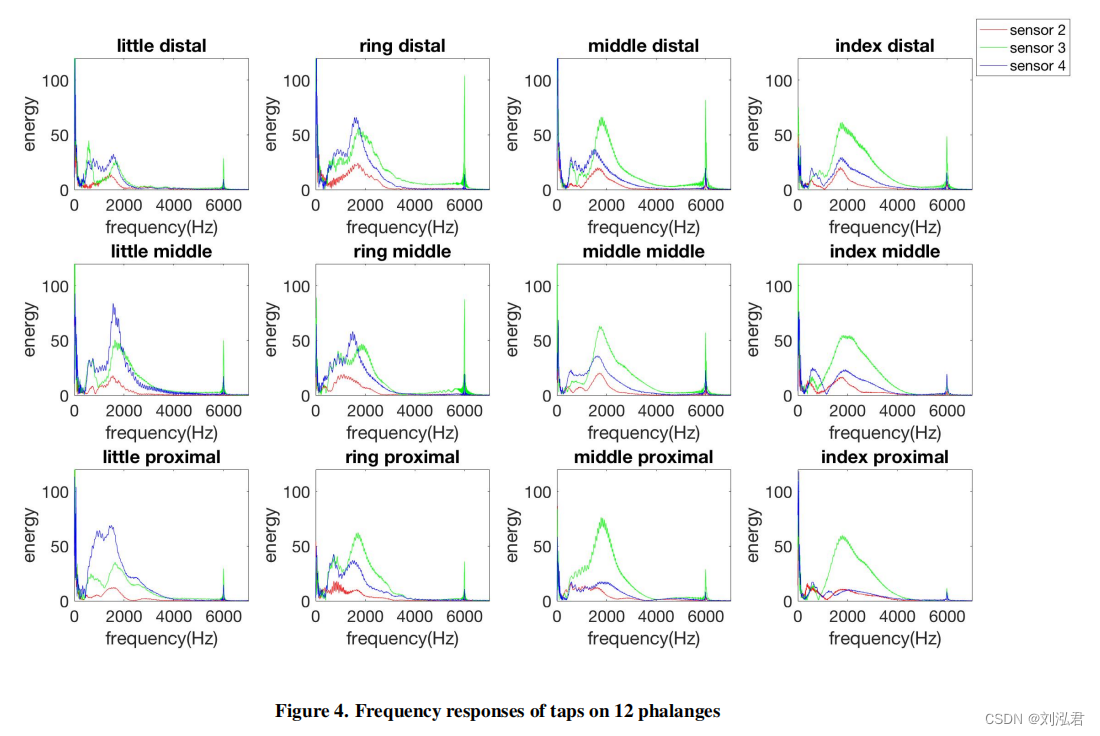
手指平利用了声波的光谱特性根据它们的路径而改变的物理现象在发送方和接收方之间移动。执行不同的手配置会影响声音通过手的方式。例如(图1),当拇指打开(不接触任何手指)时,信号只有一条主要路径可以从拇指上的扬声器传输到手腕上的接收器,即直接路径。一旦拇指触摸到其中一个指骨,就会创建一个用来传播声音的次要路径:从扬声器开始,通过被触摸的指骨和相应的手指,最后到接收器。在这种情况下,接收到的信号将来自至少两条主要路径:i)直接路径;以及ii)“绕道”路径,它穿过方阵和手指。根据接触的方阵,第二条路径——“绕道”——会发生变化,这也会改变不同频率的能量。它们可以被放大或减少,这取决于波所走的路径中的组织/骨骼的数量。不同的成分(如组织、骨骼)呈现不同的声频率响应。声波在人体中传播的这种特性为不同的手配置的频率响应构建了独特的指纹。对于如图3所示的非触摸姿势,也可以观察到同样的现象,其中第二条路径(绕道路径)取决于执行的手姿势而变化。图4显示了第一个姿势集(数字;下面解释如下)从手腕区三个接收器接收到的啁啾声的频率响应。
实现
硬件设计
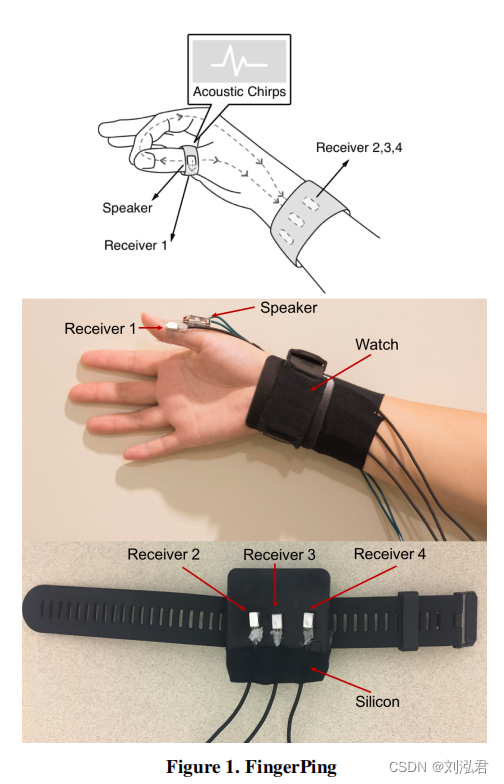
FingerPing由两个硬件组成:i)用于发射声音的表面传感器(发送器);和ii)四个接触麦克风-接收器,在声音信号穿过用户的身体后捕获声音信号。在接下来的内容中,我们将详细描述这两个组成部分。
表面传感器
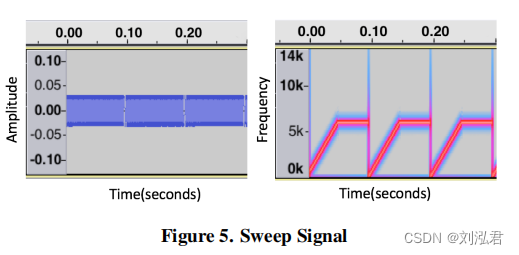
表面传感器2用于向手发出声音。传感器由一个函数发生器(安捷伦33500B)驱动,并使用有弹性的运动机能学胶带连接在拇指上。我们使用函数生成器每秒发送2个Vpp的啁啾。对于每一个啁啾,我们首先线性扫描从20Hz到6000Hz的频率范围,持续0.05秒,然后在6000Hz下再保持0.05秒,如图5所示。频率扫描的范围在实验评估(结果这里没有显示)中进行了优化,揭示了高达6000赫兹的频率在体内传播时保留了最大的信息,这也与文献中的发现(如[20])一致。
声音接收器
硬件的第二部分包括四个接触式麦克风(KnowlesBU-21771),用于从身体捕获信号,每个信号的大小为7.92mm乘5.59mm乘4.14mm。这些接触式麦克风提供了一个低噪音的地板和非常平坦的频率响应。其中一个麦克风连接在拇指上,其余三个排列在手腕上,如图1所示。我们制造了一个类似手表的设备,将麦克风连接在佩戴者的手腕上。一块硅胶被放置在表壳和麦克风之间,以固定传感器的位置,并匹配[16]的声阻抗,如[16]所示,这有助于更好的捕获的声信号的质量。
所有麦克风都连接到预放大器,以放大接收到的信号(系数:100)。放大的信号然后被传送到MacbookPro笔记本电脑,通过音频接口(防火墙800)进行数据处理。音频接口以44,100hz采样音频。该笔记本电脑运行一个用C语言编写的软件程序,使用PortAudio库与音频接口进行通信。然后,从音频接口读取的数据被发送到一个Java程序,以便通过网络套接字进行实时处理。
数据处理流程
对接收到的数据流(四个通道)的处理可以分为三个步骤,如下所述,如图6所示。音频接口的通道1到4分别映射到来自四个麦克风的信号。
为了识别给定的姿态,我们首先明确地定位(时间上)连续数据流分割中的每个啁啾。通道1是扬声器旁边麦克风的信号。啁啾的振幅在这里最高,受潜在的其他噪声的影响最小。我们执行峰值定位这个通道的音频信号找到最大绝对振幅,然后分段所有的啁啾同步通道使用窗口大小0.046秒(2048数据点方便使用快速傅里叶变换)集中在峰值位置提取的第一个通道。
为了识别给定的姿态,我们首先明确地定位(时间上)连续数据流分割中的每个啁啾。通道1是扬声器旁边麦克风的信号。啁啾的振幅在这里最高,受潜在的其他噪声的影响最小。我们执行峰值定位这个通道的音频信号找到最大绝对振幅,然后分段所有的啁啾同步通道使用窗口大小0.046秒(2048数据点方便使用快速傅里叶变换)集中在峰值位置提取的第一个通道。
姿态分割是基于与参考信号的比较。这个参考信号在系统启动期间被记录下来,当我们要求用户保持手并打开——即不执行任何姿势——并记录从所有四个麦克风的接收信号作为参考。
对于每个分段的啁啾,我们执行更快的傅里叶变换(FFT)来提取跨频率为0-10 kHz的能量分布。为了检测是否执行一个姿态,我们计算了系统启动期间记录的电流啁啾和参考啁啾之间的欧氏距离。如果距离大于一个由经验确定的阈值,我们就推断出一个姿态正在被执行。然后,我们使用来自所有四个通道的后续0.5秒的数据来进行手部姿态识别。这些数据也被保存起来用于后分析。
在第二步中,我们从从四个通道中收集到的每个啁啾中提取特征。对于每个啁啾,我们首先通过一个带通滤波器(100Hz-5,500Hz),这是基于早期探索的信息最丰富的频率范围。在过滤后的啁啾。然后提取35个特征,即:零交叉率、能量、熵、光谱质心、光谱通量、光谱色度、光谱滚动和频光谱系数[7]。然后,我们通过添加主频及其能量,以及通过FFT提取的从100Hz到5500Hz的光谱能量箱,将特征向量扩展到294。最后,我们将所有四个通道的特征向量合并,得到维数=1176的全局描述符,然后将其输入支持向量机姿态分类后端。我们使用由Weka[18]提供的SVM的顺序最小优化(SMO)实现。















 3424
3424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









