






 本文介绍了PP-ShiTu框架,使用PP-LCNet作为轻量化网络,结合主体检测和向量搜索,通过ArcMargin损失实现深度学习特征匹配。讨论了PP-PicoDet目标检测的改进技术和 ArcMargin在模型训练中的应用。同时,文章探讨了内存优化的DeepHash和快速匹配的faiss模块。
本文介绍了PP-ShiTu框架,使用PP-LCNet作为轻量化网络,结合主体检测和向量搜索,通过ArcMargin损失实现深度学习特征匹配。讨论了PP-PicoDet目标检测的改进技术和 ArcMargin在模型训练中的应用。同时,文章探讨了内存优化的DeepHash和快速匹配的faiss模块。
论文地址:https://arxiv.org/pdf/2111.00775.pdf
PP-PicoDet技术报告地址:https://arxiv.org/abs/2111.00902
PP-LCNet技术报告地址:https://arxiv.org/abs/2109.15099
ArcMargin文章地址:https://arxiv.org/abs/1801.07698
PP-ShiTu包含三个模块,即主体检测、特征提取和向量搜索。PP ShiTu的管道非常简单。获取图像时,我们首先检测一个或多个主体区域找到图像的主要区域。然后我们使用CNN模型从这些区域提取特征。特征是浮点数向量或二元向量。根据度量学习理论,特征意味着两个对象的相似性。两个特征之间的距离越短,原始两个对象就越相似。最后,我们使用向量搜索算法在图库中找到与我们从图像中提取的特征最接近的特征,并使用相应的标签作为我们的识别结果。
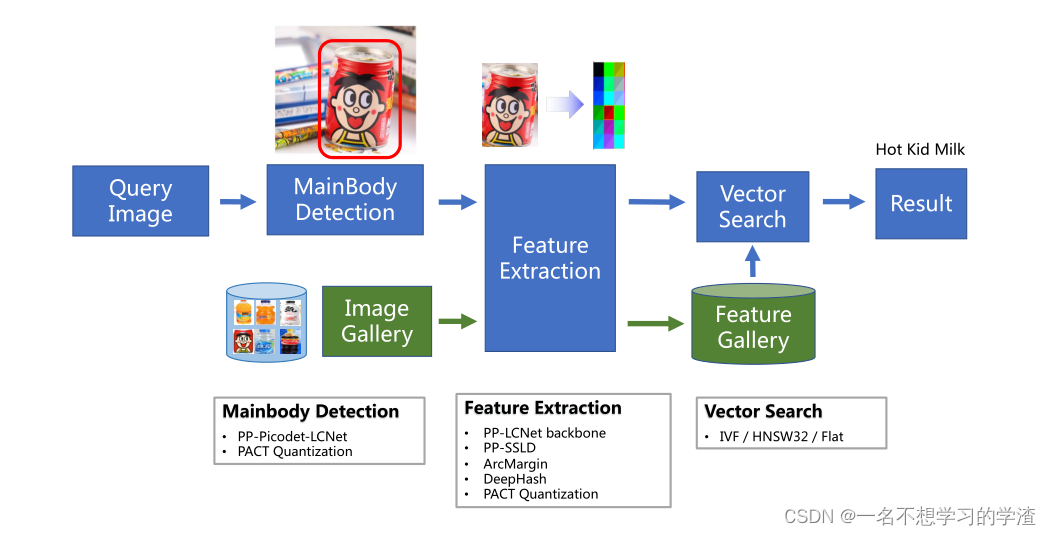
PP-ShiTu的框架
其中,为了让模型能够轻量化并且能够在CPU上面运行,所以采用轻量性网络结构PP-LCNet来作为目标检测中的主干特征提取网络 ,如下图所示。
虚线框代表可选模块。茎部采用标准的3×3卷积。DepthSepConv表示深度可分离卷积,DW表示深度卷积,PW表示逐点卷积,GAP表示全局平均池,其中深度可分离卷积就是mobilenetv1中所使用的是一样的。并且用H-Swish替换了网络中的激活函数,并且由于SE模块的应用会增加推理时间,所以根据相关实验,我们只需将SE模块添加到网络尾部附近的块中,就可以实现更好的精度速度平衡。SE模块中两层的激活功能是ReLU和H-Sigmoid。其中不知道SE模块的代码如可以看我这篇文章的mobilenetv3网络。
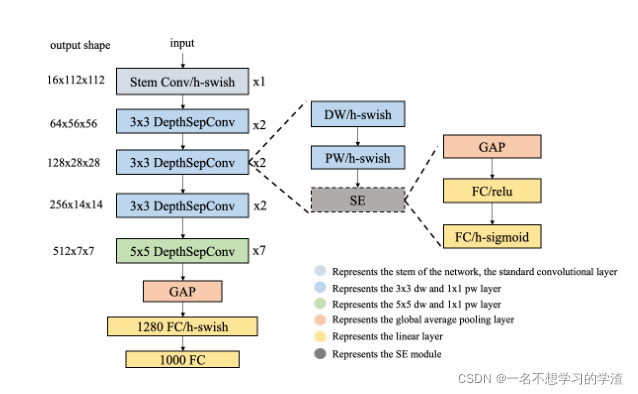
PP-LCNet模型框架
该论文所使用的主体框架目标检测是PP-PicoDet ,当然在一些经验上,他们使用了一些改进比如CSP网络与PAN FPN相结合,开发了一种称为CSP-PAN的新FPN结构,这有助于增强特征图提取能力。采用SimOTA(这是一种正负样本选择的一个比较特别的方法,该方法在yolox中也有使用到,大家可以去学学这部分的内容,还是比较绕的),并在网络训练过程中使用改进的GFocal loss功能等等方法。
当一个图片被PP-PicoDet进行检测后,会得到这样的预测框(包含着前景信息),然后网络会将这样的预测框截取下来,然后对这个预测框进行特征提取,并将图片库中的图片也放进特征提取网络中,从而能够得到两个向量。下面是特征提取网络结构:
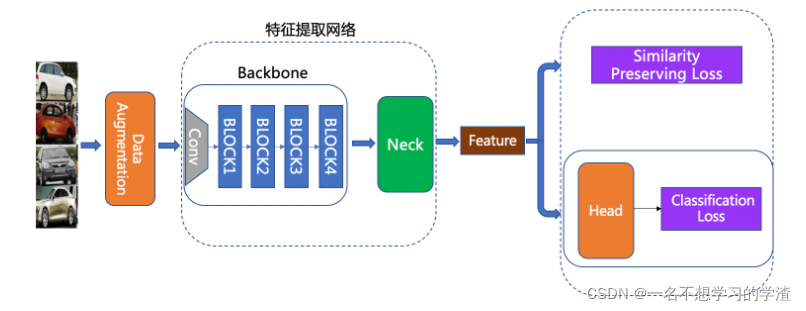
图中各个模块的功能为:#此处可以理解为一个分类网路模型就可以了,不要想的太难
- Backbone: 指定所使用的骨干网络。 值得注意的是,PaddleClas 提供的基于 ImageNet 的预训练模型,最后一层的输出为 1000,我们需要依据所需的特征维度定制最后一层的输出。
- Neck: 用以特征增强及特征维度变换。这儿的 Neck,可以是一个简单的 Linear Layer,用来做特征维度变换;也可以是较复杂的 FPN 结构,用以做特征增强。
- Head: 用来将 feature 转化为 logits。除了常用的 Fc Layer 外,还可以替换为 cosmargin, arcmargin, circlemargin 等模块。
- Loss: 指定所使用的 Loss 函数。我们将 Loss 设计为组合 loss 的形式,可以方便地将 Classification Loss 和 Pair_wise Loss 组合在一起。
然后再对这两个向量进行相似度匹配,那么此时就需要一种度量函数来得到这两个向量的相似值。这个度量函数就是ArcMargin loss
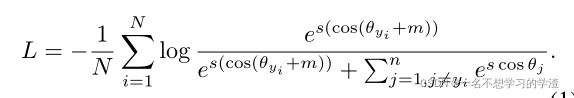
whereθj is the angle between the weight and the feature.The batch size and the class number are N and n, respec-tively. m is an angular margin penalty on the target angle θyi , and s is feature scale. θj是权重和特征之间的角度。批次大小和类别号分别为N和N。m是目标角度θyi上的角裕度惩罚,s是特征尺度
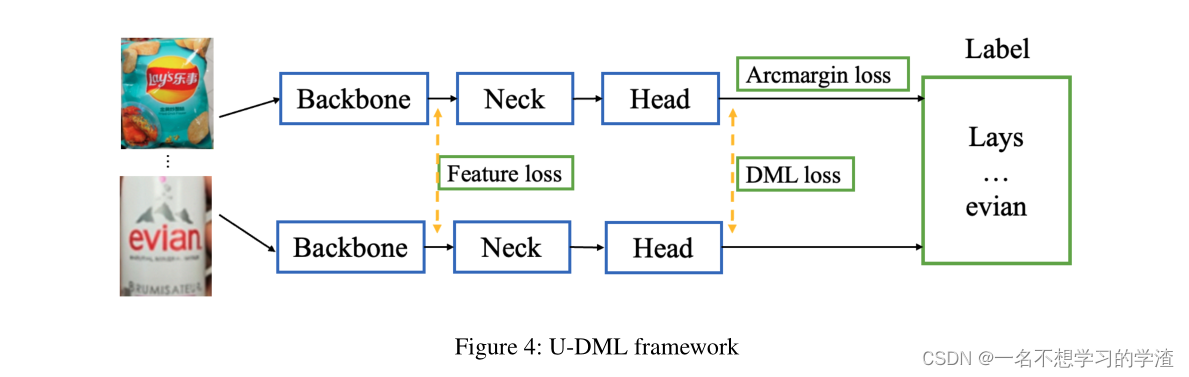
上面的就是老师和学生网络部分部分,就是利用教师网络来训练学生网络,因为教师网络的结构复杂所以就直接用学生网络(结构简单)直接向教师靠拢,并且向真实标签靠拢,因此就会产生两种损失,学生和老师的损失,学生和真实标签的损失。
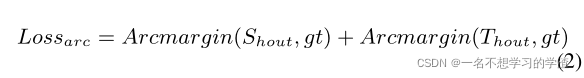
ArcMargin_loss
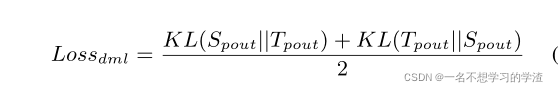
DML_loss
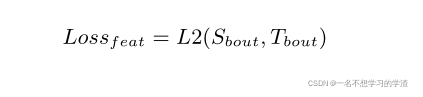
Feature_loss
其实上面的一部分,把我看的一愣一愣的,大家想弄懂可以看相关知识,并且仔细看论文。
后面为了减小内存,论文中有提出了DeepHash,DeepHash研究如何利用deep神经网络获取具有代表性的二值特征,deep神经网络使用位存储二值特征,并采用Hamming距离来度量两个特征向量之间的距离。并且对于快速匹配,论文中也是使用了faiss模块,网上的相关材料很多,大家可以自己去了解。

















 6212
6212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









