







每天30min学习python—空气质量指数
目录
1.0 实现功能
- 根据步骤,计算空气质量指数
知识点:
-
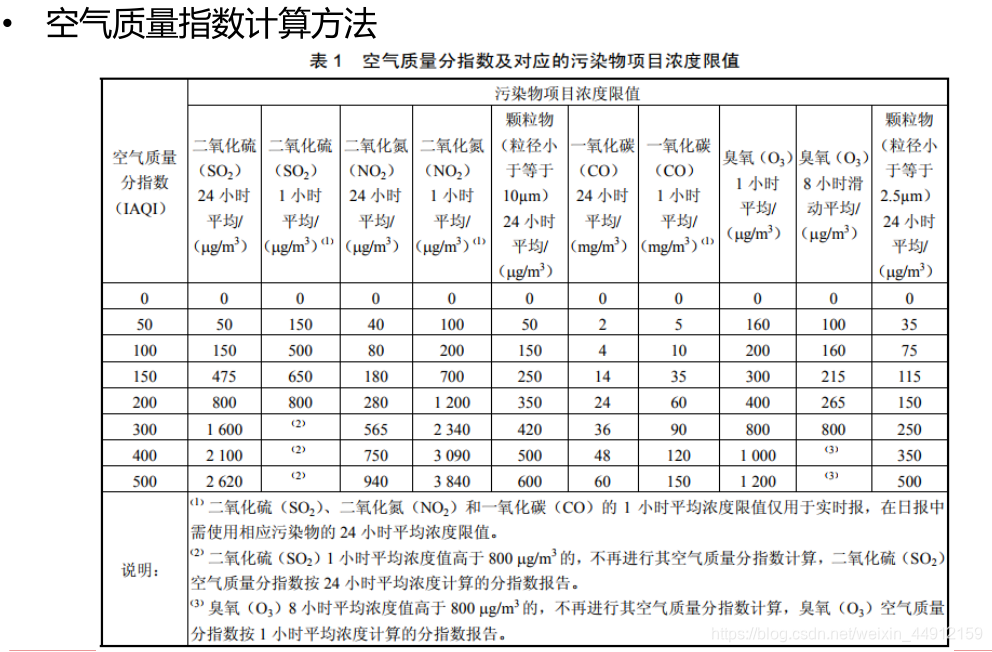
空气质量指数计算公式
-
( I A Q I p ) = I A Q I H H − I A Q I L o B P H − B P L o ( C P − B P L o ) + I A Q I L o \left(\mathrm{IAQI}_{\mathrm{p}}\right)=\frac{\mathrm{IAQI}_{\mathrm{H}_{\mathrm{H}}}-\mathrm{IAQI}_{\mathrm{Lo}}}{\mathrm{BP}_{\mathrm{H}}-\mathrm{BP}_{\mathrm{Lo}}}\left(C_{\mathrm{P}}-\mathrm{BP}_{\mathrm{Lo}}\right)+\mathrm{IAQI}_{\mathrm{Lo}} (IAQIp)=BPH−BPLoIAQIHH−IAQILo(CP−BPLo)+IAQILo
式中:IAQIp —— 污染物项目P的空气质量分指数;
Cp —— 污染物项目P的质量浓度;
BPHi ——表1中与Cp的相近的污染物浓度限值的高位值
BPLo ——表1中与Cp的相近的污染物浓度限值的低位值
IAQIHi ——表1中与BPHi对应的空气质量分指数
IAQILo ——表1中与BPLo对应的空气质量分指数
-
-
AQI = max{IAQI1,IAQI2,IAQI3…IAQIn }
-
例子:
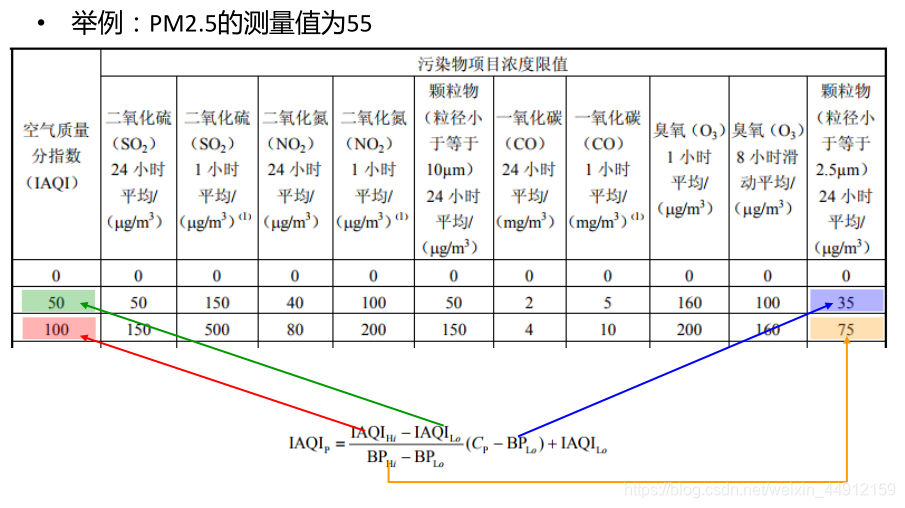
代码区:
"""
作者:Troublemaker
功能:检测API
版本:1.0
日期:2020/1/17 19:35
脚本:AQI_1.0.py
"""
def cal_IAQI(iaqi_h, iaqi_l, bp_h, bp_l, c_p):
iaqi_p = (iaqi_h - iaqi_l) / (bp_h - bp_l) * (c_p - bp_l) + iaqi_l
return iaqi_p
def get_value(value):
if 0 <= value < 36:
iaqi_p = cal_IAQI(50, 0, 35, 0, value)
elif 36 <= value < 75:
iaqi_p = cal_IAQI(100, 50, 75, 35, value)
elif 75 <= value < 115:
iaqi_p = cal_IAQI(150, 100, 115, 75, value)
elif 115 <= value < 150:
iaqi_p = cal_IAQI(200, 150, 150, 115, value)
elif 150 <= value < 250:
iaqi_p = cal_IAQI(300, 200, 250, 150, value)
elif 250 <= value < 350:
iaqi_p = cal_IAQI(400, 300, 350, 250, value)
elif 350 <= value < 500:
iaqi_p = cal_IAQI(500, 400, 500, 350, value)
return iaqi_p
def main():
print("测试IAQI值")
pm_value = float(input("请输入您当前pm2.5值"))
iaqi_p = get_value(pm_value)
print("pm2.5为 {} 时,对应的值为{}。".format(pm_value, iaqi_p))
if __name__ == "__main__":
main()
2.0 实现功能
- 读取JSON文件
- 将AQI前5的数据输出到文件
知识点:
-
JSON格式
- JSON(javaScript Object Notation)是一种轻量级数据交换格式
- 可以对复杂数据进行表达和存储,易于阅读和理解
- 规则
- 数据保存在键值对中
- 键值对之间由逗号分隔
- 花括号用于保存键值对数据组成的对象
- 方括号用于保存键值对数据组成的数组
- 采用对象、数组方式组织起来的键值对可以表示任何结构的数据
- JSON格式是互联网上主要使用的复杂数据格式之一
-
JSON库
- JSON库是处理JSON格式的python标准库
- 两个过程:
- 编码(encoding),将Python数据类型装换成JSON格式的过程
- 解码(decoding),从JSON格式中解析数据到Python数据类型的过程
函数 含义 json.dumps(content, file) Python数据类型 ——> JSON格式(相当于编码encoding) json.loads(file) JSON格式 ——> Python数据类型(相当于解码decoding) json.dump(content, file) 与dumps()功能一致,输出到文件 json.load(file) 与loads()功能一致,从文件读入 list.sort(func) func指定了排序的方法,func可以通过lambda函数实现
代码区:
"""
作者:Troublemaker
功能:检测API
版本:2.0
日期:2020/1/17 20:05
脚本:AQI_2.0.py
"""
import json
def py_to_json(content, file):
"""encoding"""
f = open(file, "w", encoding="utf-8")
json.dump(content, f, ensure_ascii=False)
f.close()
def json_to_py(file):
"""decoding"""
f = open(file, "r", encoding="utf-8")
content = json.load(f)
return content
def main():
"""主函数"""
read_file = input("请输入读取文件名")
py_data = json_to_py(read_file)
py_data.sort(key=lambda city: city["aqi"])
py_data_5 = py_data[:5]
write_file = input("请输入写入文件名")
py_to_json(py_data_5, write_file)
if __name__ == "__main__":
main()
3.0 实现功能
- 读取已经获取的JSON数据文件
- 将其转换成CSV文件
知识点:
-
CSV格式
-
CSV(Comma-Separated Values) 是一种通用的、相对简单的文件格式
-
在商业和科学领域上广泛使用
-
规则
- 以行为单位
- 每行表示一条记录
- 以英文逗号分割每列数据(如果数据为空,逗号也要保留)
- 列名通常放置在文件第一行
-
import csv
-
cvs.wirterow(list) 将列表中的元素写入文件的一行中
# 例如 writer = csv.writer(file) for content in contents: writer.writerow(content)
-
代码区:
"""
作者:Troublemaker
功能:检测API
版本:3.0
日期:2020/1/17 20:35
脚本:AQI_2.0.py
"""
import json
import csv
def py_to_json(content, file):
"""encoding"""
f = open(file, "w", encoding="utf-8")
json.dump(content, f, ensure_ascii=False)
f.close()
def json_to_py(file):
"""decoding"""
f = open(file, "r", encoding="utf-8")
content = json.load(f)
return content
def save_to_csv(contents, file_path):
"""save to csv"""
with open(file_path, "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
for content in contents:
writer.writerow(content)
def main():
"""主函数"""
read_file = input("请输入读取文件名")
py_data = json_to_py(read_file)
py_data.sort(key=lambda city: city["aqi"])
py_data_5 = py_data[:5]
# print(py_data_5[0].keys())
write_file = input("请输入写入文件名")
lines = []
lines.append(py_data_5[0].keys())
for i in py_data_5:
lines.append(i.values())
save_to_csv(lines, write_file)
if __name__ == "__main__":
main()
4.0 实现功能
- 根据输入的文件判断是JSON格式还是CSV格式,并进行相应的操作
知识点:
-
CSV文件读取
-
import csv
-
csv.reader() 将每行记录作为列表返回
# 例如 contetns = csv.reader(file) for content in contents: print(content)
-
-
OS模块
-
os模块提供了与系统、目录操作相关的功能,不受平台的限制
函数 含义 os.remove() 删除文件 os.makedirs() 创建多层目录 os.rmdir() 删除单级目录 os.rename() 重命名文件 os.path.isfile() 判断是否为文件 os.path.isdir() 判断是否为目录 os.path.join() 连接目录,如path1 连接path2为:path1/path2 os.path.splitext() 将文件分割成文件名和扩展名,如Troublemaker.csv 分割为Troublemaker和.csv。
-
代码区:
"""
作者:Troublemaker
功能:检测API
版本:4.0
日期:2020/1/17 21:35
脚本:AQI_2.0.py
"""
import csv
import json
import os
def read_csv(file):
"""read .csv"""
with open(file, "r", encoding="utf-8") as f:
contents = csv.reader(f)
for content in contents:
print(content)
def read_json(file):
"""read .json"""
with open(file, "r", encoding="utf-8") as f:
content = json.load(f)
print(content)
def main():
file_name = input("请输入文件名")
name, tail = os.path.splitext(file_name)
if tail == ".csv":
read_csv(file_name)
elif tail == ".json":
read_json(file_name)
else:
print("暂时不支持{}格式的文件".format(tail))
if __name__ == "__main__":
main()
5.0 实现功能
- 利用网络爬虫实时获取城市的空气质量。
知识点:
-
网络爬虫步骤
- 通过网络链接获取网页内容
- 对获得的网页内容进行处理
-
requests模块
-
requests模块是一个简洁且简单的处理HTTP请求的工具
-
支持非常丰富的链接访问功能,包括URL获取,HTTP会话,Cookie记录等
-
requests网页请求
函数 含义 get() 对应HTTP的GET方式 post() 对应HTTP的POST方式,用于传递用户数据
-
-
requests对象属性
函数 含义 status_code HTTP请求的返回状态,200表示连接成功,400表示连接失败 text HTTP相应内容的字符串形式,即URL对应的页面内容
代码区:
"""
作者:Troublemaker
功能:检测API
版本:5.0
日期:2020/1/17 22:35
脚本:AQI_2.0.py
"""
import requests
def get_url_text(url):
""" 得到网页文本"""
r = requests.get(url)
status = r.status_code
if status == 200:
print("连接成功")
text = r.text
return text
def main():
"""
主函数
"""
city_pinyin = input('请输入城市拼音:')
url = 'http://pm25.in/' + city_pinyin
url_text = get_url_text(url)
find_str = '''<div class="span12 data">
<div class="span1">
<div class="value">
'''
index = url_text.find(find_str)
begin_index = index + len(find_str)
end_index = begin_index + 2
air_quality = url_text[begin_index: end_index]
print('{}的空气质量为:{}。'.format(city_pinyin ,air_quality))
if __name__ == '__main__':
main()
6.0+7.0 实现功能
- 6.0:高效地解析和处理HTML,beautifulsoup4
- 7.0:获取所有城市的空气质量数据
知识点:
- BeautifulSoup
- 用于解析HTML或XML
-
步骤
- 创建BeautifulSoup对象
- 查询节点
- find,找到第一个满足条件的节点
- find_all,找到所有满足条件的节点
<a href="a.html" class="a_link">next page</a>
- 可按节点类型、属性或内容访问
- 按类型查找节点
- bs.find_all(“a”)
- 按属性查找节点
- bs.find_all(“a”, href=“a.html”, string=“next page”)
- bs.find_all(“a”, class_=“a_link”)
- 或者bs.find_all(“a”, {“class”: “a_link”})
代码区:
"""
作者:Troublemaker
功能:检测API
版本:6.0+7.0
日期:2020/1/17 23:35
脚本:AQI_2.0.py
"""
import requests
from bs4 import BeautifulSoup
def get_url_txt(url):
r = requests.get(url, timeout=30)
return r.text
def get_city_AQI(city_pinyin):
"""
获取城市AQI
"""
url = "http://pm25.in/" + city_pinyin
text = get_url_txt(url)
bs = BeautifulSoup(
text,
"lxml",
)
get_list = bs.find_all("div", {"class": "span1"})
AQI_list = []
for i in range(len(get_list) - 1):
get_content = get_list[i]
caption = get_content.find("div", {"class": "caption"}).text.strip()
value = get_content.find("div", {"class": "value"}).text.strip()
AQI_list.append((caption, value))
print("{}的空气质量指数为{}。".format(city_pinyin, AQI_list[0][1]))
def get_all_city_AQI():
"""获取所有城市名"""
url = "http://pm25.in"
text = get_url_txt(url)
bs = BeautifulSoup(
text,
"lxml",
)
all_city = bs.find_all("div", {"class" : "bottom"})[1]
cities = all_city.find_all("a")
city_list = []
for city in cities:
city_list.append(city.text)
return city_list
def main():
city_list = get_all_city_AQI()
for city_name in city_list[ :10]:
get_city_AQI(city_name)
if __name__ == "__main__":
main()
8.0 实现功能
- 将获取的所有城市的空气质量保存成csv数据文件
知识点:
- 利用之前学过的csv保存文件
代码区:
"""
作者:Troublemaker
功能:检测API
版本:8.0
日期:2020/1/18 13:02
脚本:AQI_8.0.py
"""
import requests
import csv
from bs4 import BeautifulSoup
def get_url_txt(url):
r = requests.get(url, timeout=30)
return r.text
def save_to_csv(file_path, header, contents):
"""
保存为csv文件
"""
print(contents)
with open(file_path, "w+", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(header)
for i,city_name in enumerate(contents):
if (i+1) % 10 == 0:
print("已处理{}条,总共{}条。".format(i+1, len(contents)))
city_aqi = get_city_AQI(city_name)
row = [city_name] + city_aqi
writer.writerow(row)
def get_city_AQI(city_pinyin):
"""
获取城市AQI
"""
url = "http://pm25.in/" + city_pinyin
text = get_url_txt(url)
bs = BeautifulSoup(
text,
"lxml",
)
get_list = bs.find_all("div", {"class": "span1"})
AQI_list = []
for i in range(len(get_list) - 1):
get_content = get_list[i]
caption = get_content.find("div", {"class": "caption"}).text.strip()
value = get_content.find("div", {"class": "value"}).text.strip()
AQI_list.append(value)
print("{}的空气质量指数为{}。".format(city_pinyin, AQI_list[0]))
return AQI_list
def get_all_city_AQI():
"""获取所有城市名"""
url = "http://pm25.in"
text = get_url_txt(url)
bs = BeautifulSoup(
text,
"lxml",
)
all_city = bs.find_all("div", {"class" : "bottom"})[1]
cities = all_city.find_all("a")
city_list = []
for city in cities:
city_list.append(city.text)
return city_list
def main():
"""
主函数
"""
city_list = get_all_city_AQI()
header = ["City","AQI","PM2.5/1h", "PM2.5/10h","CO/1h","NO2/1h","O3/1h","O3/8h","SO2/1h"]
file_path = "city10_AQI.csv"
save_to_csv(file_path, header, city_list)
if __name__ == "__main__":
main()
9.0+10.0 实现功能
- 9.0:利用Pandas进行数据处理和分析
- 10.0:数据清洗,可视化
知识点:
Series
-
类似一维数组的对象
-
通过list构建Series
- ser_obj = pd.Series(range(10))
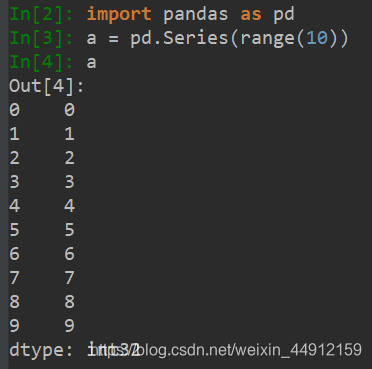
- ser_obj = pd.Series(range(10))
-
由数据和索引组成
- 索引在左,数据在右
- 索引是自动创建的
-
获取数据和索引
- ser_obj.index,ser_obj.values

- ser_obj.index,ser_obj.values
-
预览数据
- ser_obj.head(n),不输入n,默认预览前5个
-
通过索引获取数据
- ser_obj[index]
-
索引与数据的对应关系仍然保持在数组运算的结果中
-
通过dict构建Series
-
name属性
- ser_obj.name,ser_obj,index.name
DataFrame
- 类似多维数组/表格数据
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
- 通过ndarray构建DataFrame
- 通过dict构建DataFrame
- 通过列索引获取数据
- df_obj[col_index] 或者df_obj.col_index
- 增加列数据,类似dict添加key-value
- df_obj[new_col_index] = data
- 删除列
- del df_obj[col_index]
- 索引操作
- 列索引
- df_obj[“label”]
- 不连续索引
- df_obj[[“label1”, “label2”]]
- 列索引
- 排序
- sort_index,索引排序
- 对DataFram 操作时注意轴方向
- sort_index,索引排序
- 按值排序
- sort_values(by=“label”)
Pandas数据清洗
- 处理缺失数据
- dropna() 丢弃缺失数据
- fillna()填充缺失数据
- 数据过滤
- df[filter_condition] 根据条件对数据进行过滤
Pandas数据可视化
- plot(kind, x, y, title, figsize)
- x,y:横纵坐标对应的数据列
- title图像名称
- figsize图像尺寸
- 保存图像
- plt.savefig()
- 详细请参考:https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html
代码区:
"""
作者:Troublemaker
功能:检测API
版本:9.0
日期:2020/1/18 13:32
脚本:AQI_9.0.py
"""
import pandas as pd
import matplotlib.pyplot as plt
# 解决图标中显示中文问题
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
def main():
"""
主函数
"""
aqi_data = pd.read_csv("./letc09/china_city_aqi.csv")
# 基本信息
print(aqi_data.info())
# 数据预览
print(aqi_data.head())
# 数据清洗(保留AQI>0的数据)
filter_condition = aqi_data["AQI"] > 5
clean_data = aqi_data[filter_condition]
# 按指定排序返回最大值,最小值,均值
print("...............................................")
print("最大值:{},最小值:{},均值:{}。".format(clean_data["AQI"].max(), clean_data["AQI"].min(), clean_data["AQI"].mean()))
# top_n
top10_city = clean_data.sort_values(by=["AQI"]).head(10)
# bottom_n
bottom20_city = clean_data.sort_values(by=["AQI"], ascending=False).head(20)
print("空气质量前10城市:{},空气质量后20城市:{}。".format(top10_city, bottom20_city))
# 保存成CSV文件
bottom20_city.to_csv("bottom_20.csv", encoding="utf-8",index=False)
# top_30_city
top30_city = clean_data.sort_values(by=["AQI"]).head(30)
top30_city.plot(kind="bar", x="City", y="AQI", title="空气质量最好的30个city", figsize=(20,10))
plt.savefig("top30_aqi.png")
plt.show()
if __name__ == "__main__":
main()

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









