






前言
本文具体讲解一下TD算法:主要讲Sarsa、Q-Learning算法。
一、TD Learning
1.Sarsa算法
首先来回顾一下TD算法:Ut = Rt + r * U(t+1) ;Qπ(st,at)是在状态st和动作at下,Ut的期望;
1)表格形式的Sarsa算法:我们的目标是学习Qπ(s,a);如果状态和动作的数量是有限的,那么我们可以画一张表格,表中的一行对应一个状态,一列对应一个动作,表中的每个元素对应一个动作价值,我们要做的就是用Sarsa算法来更新表格,每次更新一个元素;

每次观测到一个四元组(st,at,rt,st+1);
用策略函数π来计算下一个动作,把下一个动作记为at+1;
然后计算TD target yt;这里的Qπ(st+1,at+1)就是在表格中找到st+1,
再找到动作at+1,把那个元素取出来,该元素就是Qπ(st+1,at+1);Qπ(st,at)同理;最后把Qπ(st,at)写回表格对应的位置,更新了表格里的值;
算法每次用五元组(st,at,rt,st+1,at+1)来更新动作价值函数Qπ,该五元组首字母缩写就是Sarsa;
2)神经网络形式的Sarsa算法:我们的目标就是用神经网络q(s,a;w)近似Qπ(s,a);
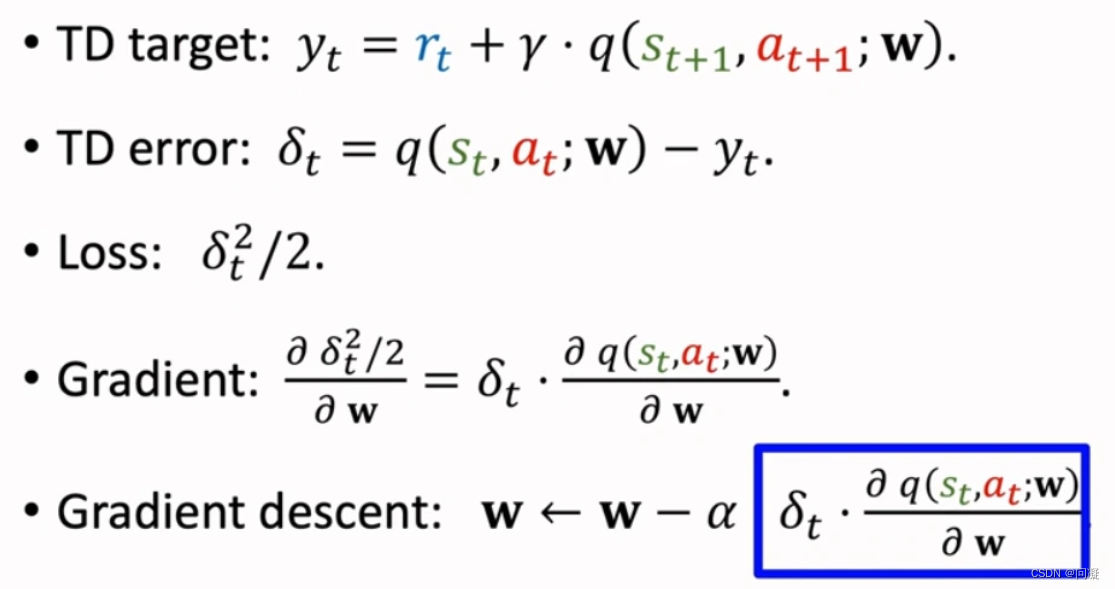 跟表格形式的Sarsa算法类似,不再赘述;
跟表格形式的Sarsa算法类似,不再赘述;
3)总结:
Sarsa算法的目标就是学习动作价值函数Qπ(s,a);表格形式的Sarsa算法直接学习Qπ(s,a);条件是状态和动作数量有限;
神经网络形式的Sarsa算法通过神经网络q(s,a;w)近似Qπ(s,a),每次通过五元组来更新神经网络的参数w;
2.Q-learning算法
Sarsa和Q-Learning都是TD算法,但是解决的问题不同:
Sarsa用来训练学习动作价值函数Qπ(s,a);
Q-learning用来训练最优动作价值函数Q*(s,a);
Q-learning的TD target和Sarsa的TD target如下图所示:
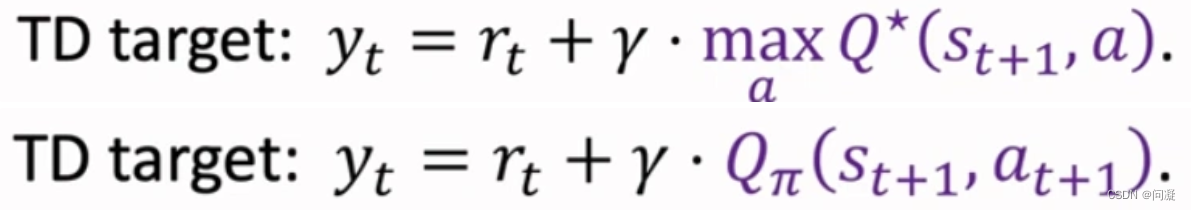 Q-learning对Q*(s,a)求最大化,而Sarsa没有最大化;
Q-learning对Q*(s,a)求最大化,而Sarsa没有最大化;
1)Q-learing算法的表格形式:
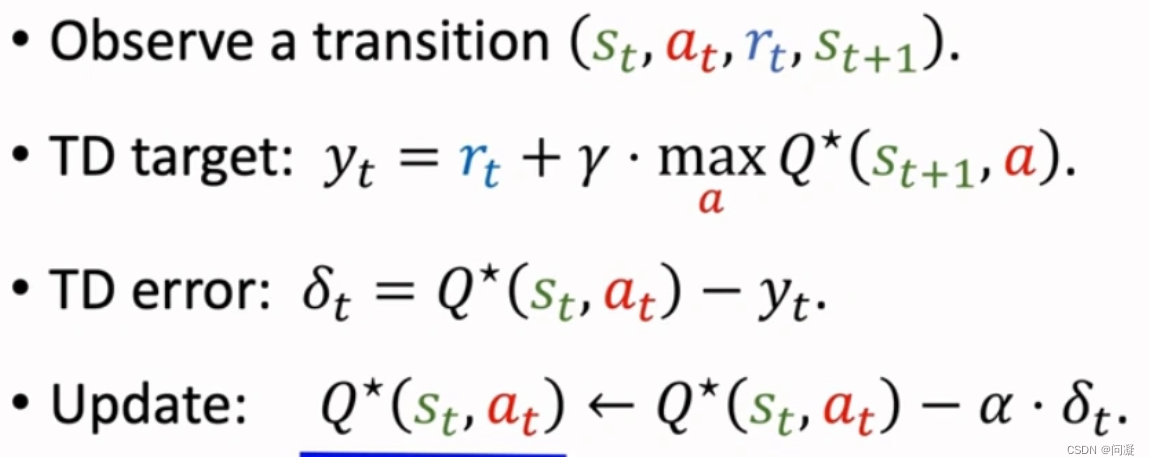 每次观测到一个四元组(st,at,rt,st+1);
每次观测到一个四元组(st,at,rt,st+1);
然后计算TD target yt;Q*(st+1,a)的计算是通过查表格,找到状态st+1那一行,找出最大的元素,最大的元素就是Q*(st+1,a);
最后把Qπ(st,at)写回表格对应的位置,更新了表格里的值;
2)Q-learing算法的神经网络形式:
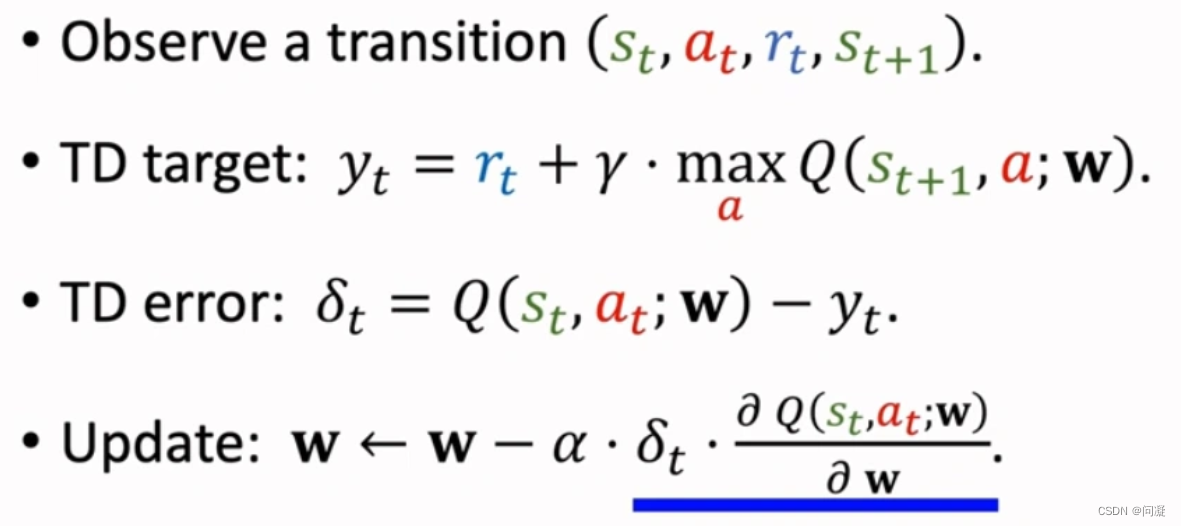 跟表格形式的Q-learing算法类似,不再赘述;
跟表格形式的Q-learing算法类似,不再赘述;
3)总结:
Q-learning的目标是学习最优动作价值函数Q*;表格形式的Q适用的条件是状态和动作数量有限,Q-learning算法每次更新表格中的一个元素;Q-learning算法的神经网络的形式是通过q(s,a;w)近似Q,Q-learning算法每次更新参数w;
3.Multi-step TD Target
1)

One-step 只用一个轨迹去计算TD Target,并且来更新动作价值;一个轨迹包括(st,at,rt,st+1),其中只有一个奖励rt,算出的TD Target叫做One-step TD Target;下一次用另一个轨迹去更新动作价值;一直重复下去;Multi-step TD Target使用多个奖励计算TD Target,然后对动作价值进行更新,比如同时使用两个奖励;

这样得到的TD Target叫做Multi-step TD Target;然后再用后面两个奖励再对动作价值进行更新;

这样做的效果比One-step TD Target效果要好;
2)Multi-Step Return

我们可以让汇报包含两个奖励rt和rt+1,还可以包含三个奖励rt和rt+1以及rt+2,然后可以递归下去,还可以包含m个奖励;这个公式叫做Multi-Step Return即多步汇报;
3)用于Sarsa算法的One-step TD Target和Multi-step TD Target

用多个奖励值能够把Qπ训练的更好,m=1就变成了标准的TD Target;
4)用于Q-learning算法的One-step TD Target和Multi-step TD Target

m是一个超参数,m大小合适的话,多步 TD Target会比一步 TD Target效果更好;
总结
以上就是今天要讲的内容,简单介绍了TD Learning中的Sarsa和Q-learning方法。
















 2231
2231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









