






本文主要讲解基于马尔科夫决策过程的规划。
文章目录
首先来介绍一下马尔科夫决策过程。
一、马尔科夫决策过程
1.1 Markov Chain、Markov Decision Process
1)具有马尔科夫性质的随机过程被称为马尔科夫链,马尔科夫链的性质是下一个状态的状态转移函数只与上一个状态有关,这么做是为了简化计算;
2)马尔科夫奖励过程是马尔科夫链加上奖励函数;
3)马尔科夫决策过程是马尔科夫链加上奖励函数再加上动作Action,也就是马尔科夫奖励过程加上动作,这只是一部分,没说全,马尔科夫决策过程的其他概念下面介绍到;
4)马尔科夫决策过程中的状态转移函数;在进行状态转移的过程中,奖励函数r也是一个随机变量,因为在状态s,采取动作a到达状态s’的时候奖励r每次都不一定相同,因此求状态转移函数的时候如果是在离散情况下就需要把在状态s,采取动作a到达状态s’,奖励为r的情况对奖励函数r进行累加,消掉奖励函数r得到如下的形式;
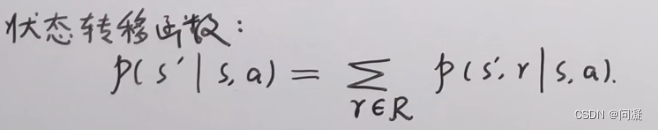
1.2 马尔科夫决策过程中的策略和价值函数
1)策略π是从状态s到动作a的映射,策略有两种:一种是随机性策略,随机性策略并不是真的随机,而是根据状态转移函数能够得到不同的动作,只是选取概率较大的那个进行执行;另一种是确定性策略,也就是在状态s的时候采取的动作a是固定的;
2)有了策略π之后,需要对策略π的好坏进行评价,那么怎么进行评价呢,对策略π进行评价需要轨迹(也就是包含状态、奖励、动作的轨迹),对策略π评价得到了回报Gt,接下来就引出状态价值函数;
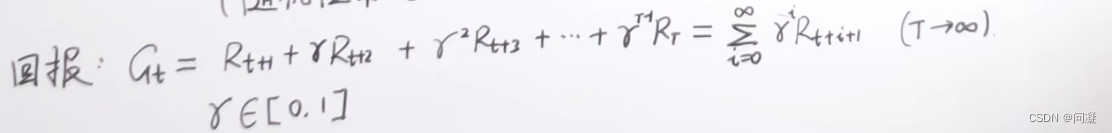
3)价值函数是对状态s进行评价的函数,形式如下:
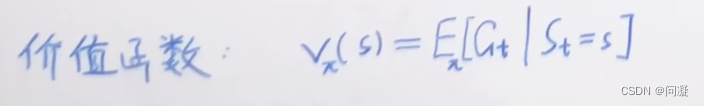
1.3 贝尔曼期望方程和贝尔曼最优方程
1)动作价值函数;动作价值函数是在状态s,采取动作a的时候对策略求期望得到的;
2)在状态s,采取动作a得到状态s’,得到奖励r的时候,因为动作价值函数里面包含状态s和动作a,所以它与价值函数联系就是动作价值函数对动作a求期望就得到了价值函数;

3)贝尔曼期望方程;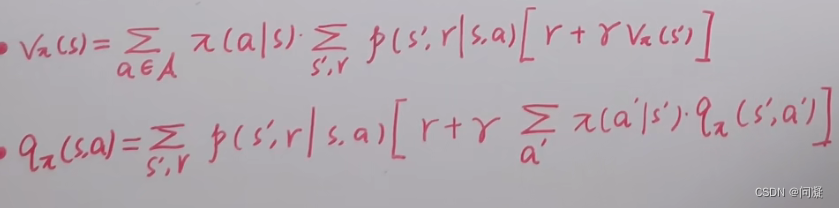
4)贝尔曼最优方程;
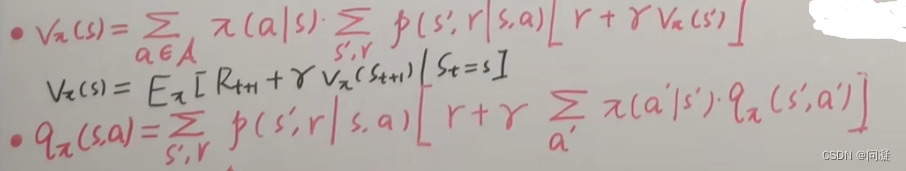
二、规划中的不确定性
2.1 规划中的不确定性
在现实生活中,规划有两方面的不确定性;一是完美执行动作不受任何干扰,二是对环境状态完全的感知;执行动作的干扰比如控制偏差、打滑、天气影响,对环境的感知不确定性包括感知的噪声、校准错误。
2.2 不确定模型
根据规划中的不确定性,把不确定性建模为两种模型:
1)Nondeterministic:不确定性的,车辆或者机器人完全不知道动作会受到什么样的干扰以及会出现多少偏差;
2)Probabilistic:概率性的,机器人可以通过经验、数据积累大概知道自己执行动作收到的干扰以及干扰程度。
2.3 Decision Makers (Game Player)
为了描述两个不确定性的模型,需要引入两个决策模型来对两种不确定性进行建模;
1)Robot:机器人是主要的决策模型基于感知得到的完美信息和执行完美的动作;
2)Nature:给Robot的执行增加不确定性的决策模型,对于Robot来说它是不可预测的;
引入Nature的原因:在以往运动规划中,只有Robot一个参与者,规划和执行都是对Robot而言的,但是在
Planning with uncertainties中,执行是Robot和Nature相互作用的结果,他们两个都是Decision Makers。
三、Planning with uncertainties
3.1 Planning with Uncertainties Formalization
1)A Game Against Nature (Independent Game):这个模型说的是机器人的动作空间U与nature的动作空间θ是相关的;
2)Nature Knows the Robot Action (Dependent Game):这个模型说的是机器人的动作空间U与nature的动作空间θ是独立的,不相关的;
3.2 One-step Worst-Case Analysis
One-step Worst-Case是在不确定的模型中包含独立和不独立的情况,机器人在这种情况下不能确定nature的行为,无法预测nature的行为,因此机器人此时必须在假设nature做出对机器人最不利的情况下的做决策;
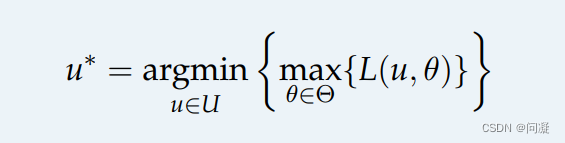
3.3 One-step Expected-Case Analysis
One-step Expected-Case是在确定的模型中包含独立和不独立的情况,机器人在这种情况下nature的行为大概可以被观测到,此时我们可以找到nature对机器人行为影响的期望值做决策;
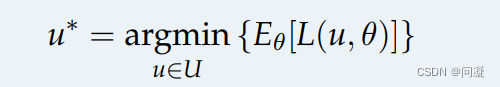
3.4 Multi-Step Discrete Planning with Nature
1)有一个初始的状态空间xs;
2)有一个机器人的动作空间U(x);
3)有一个nature的动作空间θ(x,u);
4)状态转移函数f(x,u,θ);
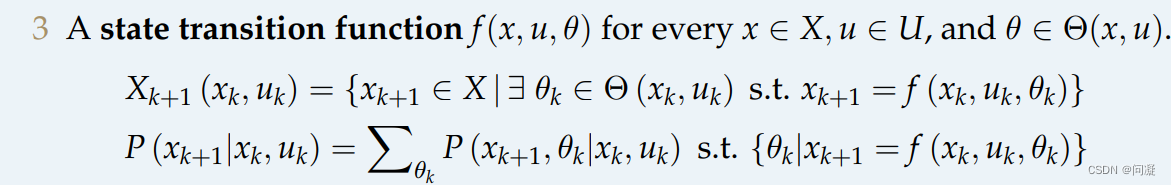
5)损失函数L;

这里的四元组(X,U,P,L)其实就对应着马尔科夫决策过程的(S,A,P,R),所以这里的规划其实就是基于马尔科夫决策过程的规划;
6)这里我们需要定义一个规划π,它是从状态空间到动作空间的映射,H(π,xs)是一条轨迹,包含了一系列的x、u、θ的信息;注意这里说的trajectory set是由π生成的决策树上采样得到的;
Planning with uncertainties的输出是一个plan,是决策树的形式,它并不是一个规划好的轨迹,而是根据到达的状态实时选择去执行哪一个动作,也就是走一步看一步的状态,根据不同的plan(plan就是π)诱导出不同的trajectory set,然后在trajectory set上定义cost-to-goal,cost-to-goal定义的目的是去衡量规划(π)的表现,然后衡量π的表现也有两种方式;
3.5 cost-to-goal in nondeterministic model and probabilistic model
对于nondeterministic model,评价performance的方式为最坏情况下π的表现;
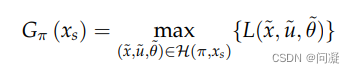
对于nondeterministic model,评价performance的方式为平均情况下π的表现;
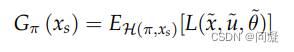
四、Minimax Cost Planning、Expected Cost Planning
4.1 Minimax Cost Planning
1)Minimax Cost Planning是在Nondeterministic Model下的规划求解的方法,因为此时无法对Nature的行为进行预测,所以假设Nature对Robot采取的是最不利的行为,那我们在求解策略的时候需要求解的是最好的策略,所以就采取最小的cost-to-goal的策略;
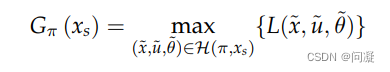
求解最优的策略是通过动态规划求解的;
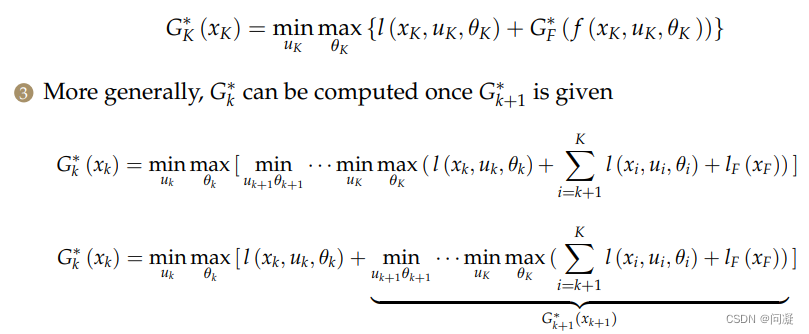
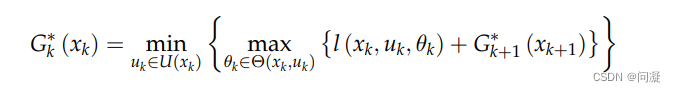
得到递推公式后比如给了一个有向图,就从终点开始递推,直到到达终点就得到了最好的策略;
4.2 Expected Cost Planning
Expected Cost Planning是在Probabilistic Model下的规划求解的方法,在Probabilistic Model下因为Robot大概知道Nature的行为对自己的干扰,所以采取平均cost-to-goal最小的策略;
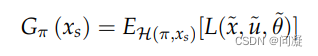
Expected Cost Planning同样是通过动态规划求解的,求解过程乳如下;
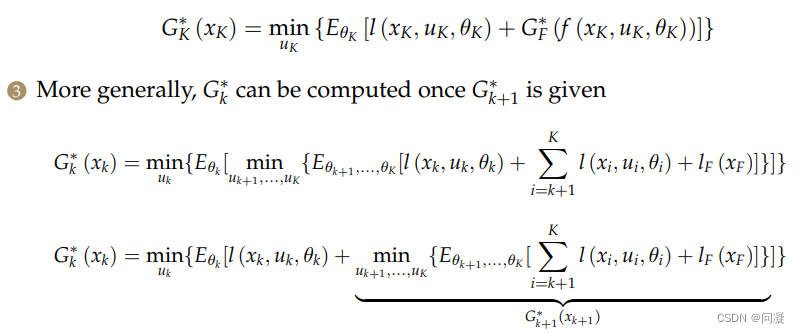
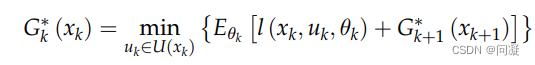
总结
基于马尔科夫决策过程的规划大概就是这样,如有不对,欢迎大家指正。
















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









