






Removing Backdoor-Based Watermarks in NeuralNetworks with Limited Data
寒假疯玩,新学期回归!!
这篇Removing Backdoor-Based Watermarks in Neural Networks with Limited Data是2021发在ICPR上的一篇,主要工作就是针对backdoor-based的神经网络的水印去除。
这一类的工作之前也有不少,经典的比如,用大量的数据独立同分布的去fune-tune水印网络,但是找到这些数据本身就不现实,何况有这么多数据那我自己重新训练一个网络就好了。还有比如加大学习率,fune-tune加水印的神经网络,但是这样做的话,太依赖于设计的方法了,学习率该怎么变?本身加trigger set的方式就多种多样,方法设计不好很可能最后都不一定会收敛,成功率不高。
本文作者就提出了一种用少量数据就能做到去除神经网络中水印的方法,接下来就细说一下方法和原理:
首先,作者认为加水印的本质就是遮挡住了一部分干净的数据(the common pattern of watermarks is that they occlude a part of the clean inputs)。后门,也就是将原本正常的输入,给他篡改label之后加入训练,希望得到的输出最后是我篡改之后的label,这样就相当于给我的神经网络加了个后门。训练好的模型,再验证的时候就能够直接验证这些数据,check输出是否是想要的label(没加水印的网络在这一部分数据上的表现更大概率肯定是输出正确的label),以此证明对这个网络的所有权。
而后提出,the injected watermarks in neural networks form strongly correlated paths from the input layer to the output layer of the model.其实就是说,当我给数据下毒之后,它必然在神经网络的某一部分得到了体现,比如某些paths。于是作者想要找到这些位置。比如全连接层,但是当retrain卷积之后的全连接层,发现改变非常有限。因此作者当然认为,这些影响的地方应该是在一些卷积核的地方(these paths are dominated by some special convolutional kernels generating large activation values with the presence of a watermark pattern)。比如 high-level feature space,那我们就来试一下,看下是不是真的有用!(当然最后在MNIST和CIFAR-10这两个数据集上试了一下确实是有用的。)
首先第一步,为了增强现在手上已经有的数据,进行一个Random Erasing处理。Random Erasing也就是对已有的图片,随机挑选其中的一块长方形的区域,在长方形里面添加高斯噪声,变成新的数据(具体如下)。然后再将这些已经得到的增强之后的数据用来对神经网络进行第一步的fine-tuning预处理。

当然我们最主要做的当然不是这个,刚刚说到,作者认为影响最大的是卷积层的高层的特征空间,所以我们想要改变的也就是这里。于是我们当然希望,干净的数据和不那么干净的数据在卷积层高层的分布的距离越来越近,这也就是我们训练的目标。也就是data points with watermark pattern 和clean data满足这样的一个优化:
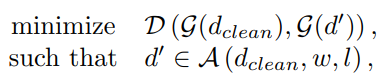
其中,
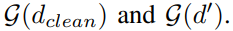
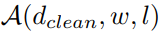
分别意味着clean data和data points with watermark patternn相对应的高层分布,和将水印w添加在位置L处得到的数据d(applying watermark trigger w at location l on data point d)。
但是显然,我们不知道也找不到,或者说没那么简单能找到这样的含有watermark pattern的数据。但是之前我们已经得到了增强之后的数据,这样的数据其实就可以拿来用啦。那么数据的事就解决了,现在要做的就是用这个分布作为惩罚项。那么总结来讲,现在我们已经做了两步工作,首先是fune-tuning,会有一个损失L_aug,然后是优化两种data之间的距离,也会有一个惩罚函数。
于是在全过程中,我们就能得到损失函数:(其中β是损失率)
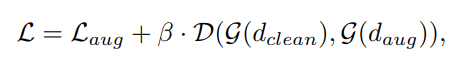
其中,函数D的选择,作者也给了两种Cross-entropy 和 Jensen–Shannon divergence。最后的实验也较多,我们就不再多说了。
其实这篇文章前面的部分花了较多的时间阐述相关的文献以及做法的优缺点,我感觉说的还是比较到位,全面的。而作者给出的这个猜想,关于添加的后门到底影响在哪里,感觉很有意思。方法比较常规,不过一个很大的弊端在于,对于一些隐水印(像用对抗样本生成的水印,加高斯噪声的做法估计没什么改变,不知道直接掩码一部分会不会好点,但是掩码掉一部分感觉又会丢掉一些重要特征,嗨害嗨。感觉有机会可以跑一下试试看效果),应该会收效甚微。总结来说攻击方法还是停留在可视化的水印上面。















04-29
 645
645
645
02-05
2072
2072
10-18
1884
1884
06-12
740
740
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









