







import torch
from torch.utils.data import Dataset
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
一、DataLoader(数据预处理)
import torch
import torch.utils.data as Data
torch.manual_seed(1)
BATCH_SIZE = 5
x = torch.linspace(1,10,10)
y = torch.linspace(10,1,10)
torch_dataset = Data.TensorDataset(x,y) #把数据放在数据库中
loader = Data.DataLoader(
# 从dataset数据库中每次抽出batch_size个数据
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,#将数据打乱
num_workers=2, #使用两个线程
)
1、DataLoader :(构建可迭代的数据装载器)
torch.utils.data.DataLoader(): 构建可迭代的数据装载器, 我们在训练的时候,每一个for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据的。

ataLoader的参数很多,但我们常用的主要有5个:
- dataset: Dataset类, 决定数据从哪读取以及如何读取
- bathsize: 批大小
- num_works: 是否多进程读取机制
- shuffle: 每个epoch是否乱序
- drop_last: 当样本数不能被batchsize整除时, 是否舍弃最后一批数据
要理解这个drop_last, 首先,得先理解Epoch, Iteration和Batchsize的概念:
- Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
- Iteration: 一批样本输入到模型中,称为一个Iteration
- Batchsize: 一批样本的大小, 决定一个Epoch有多少个Iteration
举个例子就Ok了, 假设样本总数80, Batchsize是8, 那么1Epoch=10 Iteration。 假设样本总数是87, Batchsize是8, 如果drop_last=True, 那么1Epoch=10Iteration, 如果等于False, 那么1Epoch=11Iteration, 最后1个Iteration有7个样本。
例子
#分割batch
batchdata = DataLoader(mnist,batch_size=bs, shuffle = True) #总共多少个batch?
2、输出:DataLoader 的输出包含:数据和标签
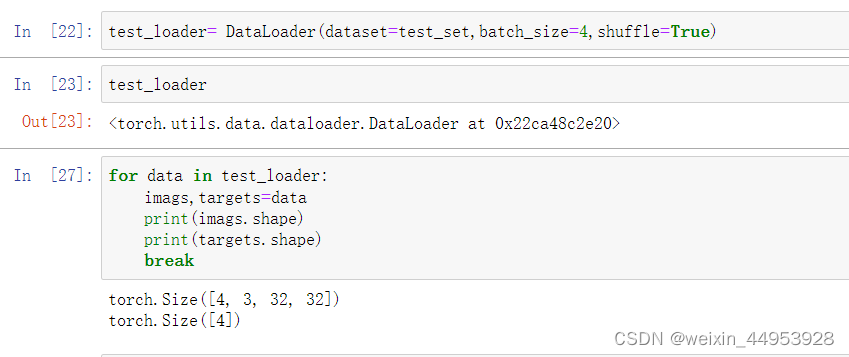

二、TensorDataset(数据预处理)
import torch
import torch.utils.data as Data
torch.manual_seed(1)
BATCH_SIZE = 5
x = torch.linspace(1,10,10)
y = torch.linspace(10,1,10)
torch_dataset = Data.TensorDataset(x,y) #把数据放在数据库中
loader = Data.DataLoader(
# 从dataset数据库中每次抽出batch_size个数据
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,#将数据打乱
num_workers=2, #使用两个线程
)
三、torch.utils.data.Dataset 介绍与实战
1.前言
训练模型一般都是先处理 数据的输入问题 和 预处理问题 。Pytorch提供了几个有用的工具:torch.utils.data.Dataset 类和 torch.utils.data.DataLoader 类 。
流程是先把原始数据转变成 torch.utils.data.Dataset 类,随后再把得到的 torch.utils.data.Dataset 类当作一个参数传递给 torch.utils.data.DataLoader 类,得到一个数据加载器,这个数据加载器每次可以返回一个 Batch 的数据供模型训练使用。
在 pytorch 中,提供了一种十分方便的数据读取机制,即使用 torch.utils.data.Dataset 与 Dataloader 组合得到数据迭代器。在每次训练时,利用这个迭代器输出每一个 batch 数据,并能在输出时对数据进行相应的预处理或数据增广操作。
2.Dataset (自定义自己读取数据的方法)
- pytorch 提供了一个数据读取的方法,其由两个类构成:torch.utils.data.Dataset 和 DataLoader。
- 如果我们要自定义自己读取数据的方法,就需要继承类 torch.utils.data.Dataset ,并将其封装到DataLoader 中。
- torch.utils.data.Dataset 是一个 类 Dataset 。通过重写定义在该类上的方法,我们可以实现多种数据读取及数据预处理方式
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])

3.通过继承 torch.utils.data.Dataset 定义自己的数据集类
torch.utils.data.Dataset 是代表自定义数据集的抽象类,我们可以定义自己的数据类抽象这个类,只需要重写__len__和__getitem__这两个方法就可以。
要自定义自己的 Dataset 类,至少要重载两个方法:_ len _, _ getitem _
- _ len _ 返回的是数据集的大小
- _ getitem _ 实现索引数据集中的某一个数据
下面将简单实现一个返回 torch.Tensor 类型的数据集:
from torch.utils.data import Dataset
import torch
class TensorDataset(Dataset):
# TensorDataset继承Dataset, 重载了__init__, __getitem__, __len__
# 实现将一组Tensor数据对封装成Tensor数据集
# 能够通过index得到数据集的数据,能够通过len,得到数据集大小
def __init__(self, data_tensor, target_tensor):
self.data_tensor = data_tensor
self.target_tensor = target_tensor
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index]
def __len__(self):
return self.data_tensor.size(0) # size(0) 返回当前张量维数的第一维
# 生成数据
data_tensor = torch.randn(4, 3) # 4 行 3 列,服从正态分布的张量
print(data_tensor)
target_tensor = torch.rand(4) # 4 个元素,服从均匀分布的张量
print(target_tensor)
# 将数据封装成 Dataset (用 TensorDataset 类)
tensor_dataset = TensorDataset(data_tensor, target_tensor)
# 可使用索引调用数据
print('tensor_data[0]: ', tensor_dataset[0])
# 可返回数据len
print('len os tensor_dataset: ', len(tensor_dataset))
输出结果:
tensor([[ 0.8618, 0.4644, -0.5929],
[ 0.9566, -0.9067, 1.5781],
[ 0.3943, -0.7775, 2.0366],
[-1.2570, -0.3859, -0.3542]])
tensor([0.1363, 0.6545, 0.4345, 0.9928])
tensor_data[0]: (tensor([ 0.8618, 0.4644, -0.5929]), tensor(0.1363))
len os tensor_dataset: 4
4、为什么要定义自己的数据集类?(实现用 pd.read_csv 读取 csv 文件)
因为我们可以通过定义自己的数据集类并重写该类上的方法 实现多种多样的(自定义的)数据读取方式。
比如,我们重写 _ init_ 实现用 pd.read_csv 读取 csv 文件:
from torch.utils.data import Dataset
import pandas as pd # 这个包用来读取CSV数据
# 继承Dataset,定义自己的数据集类 mydataset
class mydataset(Dataset):
def __init__(self, csv_file): # self 参数必须,其他参数及其形式随程序需要而不同,比如(self,*inputs)
self.csv_data = pd.read_csv(csv_file)
def __len__(self):
return len(self.csv_data)
def __getitem__(self, idx):
data = self.csv_data.values[idx]
return data
data = mydataset('spambase.csv')
print(data[3])
print(len(data))
[0.000e+00 0.000e+00 0.000e+00 0.000e+00 6.300e-01 0.000e+00 3.100e-01
6.300e-01 3.100e-01 6.300e-01 3.100e-01 3.100e-01 3.100e-01 0.000e+00
0.000e+00 3.100e-01 0.000e+00 0.000e+00 3.180e+00 0.000e+00 3.100e-01
0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00
0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00
0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00
0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00
1.370e-01 0.000e+00 1.370e-01 0.000e+00 0.000e+00 3.537e+00 4.000e+01
1.910e+02 1.000e+00]
4601

5、实战:orch.utils.data.Dataset + Dataloader 实现数据集读取和迭代
实例1:
数据集 spambase.csv 用的是 UCI 机器学习存储库里的垃圾邮件数据集,它一条数据有57个特征和1个标签。
import torch.utils.data as Data
import pandas as pd # 这个包用来读取CSV数据
import torch
# 继承Dataset,定义自己的数据集类 mydataset
class mydataset(Data.Dataset):
def __init__(self, csv_file): # self 参数必须,其他参数及其形式随程序需要而不同,比如(self,*inputs)
data_csv = pd.DataFrame(pd.read_csv(csv_file)) # 读数据
self.csv_data = data_csv.drop(axis=1, columns='58', inplace=False) # 删除最后一列标签
def __len__(self):
return len(self.csv_data)
def __getitem__(self, idx):
data = self.csv_data.values[idx]
return data
data = mydataset('spambase.csv')
x = torch.tensor(data[:5]) # 前五个数据
y = torch.tensor([1, 1, 1, 1, 1]) # 标签
torch_dataset = Data.TensorDataset(x, y) # 对给定的 tensor 数据,将他们包装成 dataset
loader = Data.DataLoader(
# 从数据库中每次抽出batch size个样本
dataset = torch_dataset, # torch TensorDataset format
batch_size = 2, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
def show_batch():
for step, (batch_x, batch_y) in enumerate(loader):
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
show_batch()
steop:0, batch_x:tensor([[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 6.3000e-01, 0.0000e+00,
3.1000e-01, 6.3000e-01, 3.1000e-01, 6.3000e-01, 3.1000e-01, 3.1000e-01,
3.1000e-01, 0.0000e+00, 0.0000e+00, 3.1000e-01, 0.0000e+00, 0.0000e+00,
3.1800e+00, 0.0000e+00, 3.1000e-01, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 1.3500e-01, 0.0000e+00, 1.3500e-01, 0.0000e+00, 0.0000e+00,
3.5370e+00, 4.0000e+01, 1.9100e+02],
[0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 6.3000e-01, 0.0000e+00,
3.1000e-01, 6.3000e-01, 3.1000e-01, 6.3000e-01, 3.1000e-01, 3.1000e-01,
3.1000e-01, 0.0000e+00, 0.0000e+00, 3.1000e-01, 0.0000e+00, 0.0000e+00,
3.1800e+00, 0.0000e+00, 3.1000e-01, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 1.3700e-01, 0.0000e+00, 1.3700e-01, 0.0000e+00, 0.0000e+00,
3.5370e+00, 4.0000e+01, 1.9100e+02]], dtype=torch.float64), batch_y:tensor([1, 1])
steop:1, batch_x:tensor([[2.1000e-01, 2.8000e-01, 5.0000e-01, 0.0000e+00, 1.4000e-01, 2.8000e-01,
2.1000e-01, 7.0000e-02, 0.0000e+00, 9.4000e-01, 2.1000e-01, 7.9000e-01,
6.5000e-01, 2.1000e-01, 1.4000e-01, 1.4000e-01, 7.0000e-02, 2.8000e-01,
3.4700e+00, 0.0000e+00, 1.5900e+00, 0.0000e+00, 4.3000e-01, 4.3000e-01,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
7.0000e-02, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 1.3200e-01, 0.0000e+00, 3.7200e-01, 1.8000e-01, 4.8000e-02,
5.1140e+00, 1.0100e+02, 1.0280e+03],
[6.0000e-02, 0.0000e+00, 7.1000e-01, 0.0000e+00, 1.2300e+00, 1.9000e-01,
1.9000e-01, 1.2000e-01, 6.4000e-01, 2.5000e-01, 3.8000e-01, 4.5000e-01,
1.2000e-01, 0.0000e+00, 1.7500e+00, 6.0000e-02, 6.0000e-02, 1.0300e+00,
1.3600e+00, 3.2000e-01, 5.1000e-01, 0.0000e+00, 1.1600e+00, 6.0000e-02,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 6.0000e-02, 0.0000e+00, 0.0000e+00,
1.2000e-01, 0.0000e+00, 6.0000e-02, 6.0000e-02, 0.0000e+00, 0.0000e+00,
1.0000e-02, 1.4300e-01, 0.0000e+00, 2.7600e-01, 1.8400e-01, 1.0000e-02,
9.8210e+00, 4.8500e+02, 2.2590e+03]], dtype=torch.float64), batch_y:tensor([1, 1])
steop:2, batch_x:tensor([[ 0.0000, 0.6400, 0.6400, 0.0000, 0.3200, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.6400, 0.0000, 0.0000,
0.0000, 0.3200, 0.0000, 1.2900, 1.9300, 0.0000, 0.9600,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.7780, 0.0000, 0.0000, 3.7560, 61.0000,
278.0000]], dtype=torch.float64), batch_y:tensor([1])
一共 5 条数据,batch_size 设为 2 ,则数据被分为三组,每组的数据量为:2,2,1。
实例 2:进阶
import torch.utils.data as Data
import pandas as pd # 这个包用来读取CSV数据
import numpy as np
# 继承Dataset,定义自己的数据集类 mydataset
class mydataset(Data.Dataset):
def __init__(self, csv_file): # self 参数必须,其他参数及其形式随程序需要而不同,比如(self,*inputs)
# 读取数据
frame = pd.DataFrame(pd.read_csv('spambase.csv'))
spam = frame[frame['58'] == 1]
ham = frame[frame['58'] == 0]
SpamNew = spam.drop(axis=1, columns='58', inplace=False) # 删除第58列,inplace=False不改变原数据,返回一个新dataframe
HamNew = ham.drop(axis=1, columns='58', inplace=False)
# 数据
self.csv_data = np.vstack([np.array(SpamNew), np.array(HamNew)]) # 将两个N维数组进行连接,形成X
# 标签
self.Label = np.array([1] * len(spam) + [0] * len(ham)) # 形成标签值列表y
def __len__(self):
return len(self.csv_data)
def __getitem__(self, idx):
data = self.csv_data[idx]
label = self.Label[idx]
return data, label
data = mydataset('spambase.csv')
print(len(data))
loader = Data.DataLoader(
# 从数据库中每次抽出batch size个样本
dataset = data, # torch TensorDataset format
batch_size = 460, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
def show_batch():
for step, (batch_x, batch_y) in enumerate(loader):
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
show_batch()
一共 4601 条数据,按 batch_size = 460 来分:能划分为 11 组,前 10 组的数据量为 460,最后一组的数据量为 1 。















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









