







数据分析师岗位需求分析
【一】分析背景:
准备转行数据分析,但缺乏对该行业的一个全方位的认知,所以利用Python爬虫爬取了当天前程无忧上2020/5/18数据分析师全文的信息,分析数据分析师岗位的相关信息。因为快半年没写爬虫了,中途出了好几次问题,最后第二天才把数据爬下来整理了(爬虫过程略,感兴趣的可以私信我共同讨论)。
【二】数据集描述
爬虫没有写的很好,所以数据看起来没那么友好。数据集总共10个字段,总共8028条数据.
数据集字段名都是中文,相关信息一目了然。不再做赘述。
【三】数据导入
1)python包导入及数据读取
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
import matplotlib,jieba,chardet,re
from wordcloud import WordCloud
orginaldata = pd.read_excel('.\Data\\数据分析师全文.xls')
2)数据简述
orginaldata.info()
orginaldata.shape
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 8028 entries, 0 to 8027
Data columns (total 10 columns):
职位名称 8028 non-null object
公司 8028 non-null object
工作地点 8028 non-null object
薪水 7398 non-null object
福利待遇 5801 non-null object
公司类型 7904 non-null object
公司规模 7536 non-null object
公司行业 7905 non-null object
其他信息 7905 non-null object
岗位详情 7905 non-null object
dtypes: object(10)
memory usage: 627.3+ KB
(8028, 10)
可以看出,数据集有8028行10列数据,其中只有“职位名称”,“工作地点”及“公司”三个字段没有缺失值。
回溯之前爬虫过程;空值的原因,①是该职位没有写该类信息 ②详情页跳转到公司的官网,爬虫没能正式生效。
3)查看数据基本构成
orginaldata.head()

可以看出数据很脏,需要花大力气清洗。
【四】数据清洗
1)岗位分布城市
数据集中的工作地点有些会带城区名,会影响我们对于城市的分布的判断,分列提取出工作城市。
data=orginaldata
data["工作城市"] = [i[0] for i in data0["工作地点"].str.split("-")]
data["工作城市"]

2)从其他信息中提取工作经验要求及学历要求。
①工作经验和学历要求提取
data['其他信息'].isnull().sum()
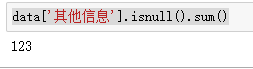
其他信息中有123条空值。
工作经验
ex = []
temp1 = data["其他信息"].str.split("|")
for i in temp1:
try:
if i[1].find("经") != -1 or i[1].find("生") != -1:
ex.append(i[1])
else:
ex.append("")
except:
ex.append("")
学历要求
edu=[]
x=1
for i in temp1:
if type(i) == list:
try:
if i[2].find("本科") != -1 or i[2].find("硕士") != -1 or i[2].find("大专") != -1 or i[2].find("高中") != -1 or i[2].find("中专") != -1 or i[2].find("博士") != -1 or i[2].find("初中") != -1 or i[2].find("中技") != -1:
edu.append(i[2])
x+=1
elif i[1].find("本科") != -1 or i[1].find("硕士") != -1 or i[1].find("大专") != -1 or 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









