






配置
1.主机映射
设置主机名
hostnamectl set-hostname centos01
分别在主机centos01、centos02、centos03打开/etc/hosts文件,添加如下的主机映射,如下图:
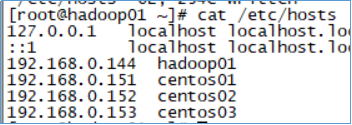
4条配置信息如下:
192.168.0.144 hadoop01
192.168.0.151 centos01
192.168.0.152 centos02
192.168.0.153 centos03
2.免密登录配置
1)分别在三个节中生成秘钥文件
`cd ~/.ssh/`
#如果~/.ssh/不存在 执行ssh localhost
ssh-keygen -t rsa
#生成公私钥对,执行过程直接回车
3.上传解压
上传到每一台主机的/opt/目录下解压,创建temp
在.ssh中
cd /opt
tar -zxvf hadoop-3.2.1.tar.gz
mkdir -p /opt/hadoop-3.2.1/temp
mkdir -p /opt/hadoop-3.2.1/temp/dfs/name
mkdir -p /opt/hadoop-3.2.1/temp/dfs/data
4.配置hadoop环境变量
进入hadoop-3.2.1/etc/hadoop/目录
cd /opt/hadoop-3.2.1/etc/hadoop/
打开如下三个文件sh文件。
hadoop-env.sh
mapred-env.sh
yarn-env.sh
添加环境变量JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_231
5.配置HDFS(在centos01下执行)
在cd /opt/hadoop-3.2.1/etc/hadoop/ 目录下
1)修改core-site.xml,添加如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value> //实际的主机名
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-3.2.1/temp</value>
</property>
</configuration>
2)修改hdfs-site.xml,添加如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.2.1/temp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.2.1/temp/dfs/data</value>
</property>
</configuration>
3)修改mapred-site.xml,添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
</configuration>
4)修改yarn-site.xml, 添加内容如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
cd …/…/sbin
5)修改workers文件,其他内容删掉
centos01
centos02
centos03
6)修改dfs和yarn脚本(17行)
vi start-dfs.sh
vi stop-dfs.sh
两处增加以下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi start-yarn.sh
vi stop-yarn.sh
两处增加以下内容(17行)
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
7)拷贝到centos02和centos03
scp -r /opt/hadoop-3.2.1/ root@centos02:/opt/
scp -r /opt/hadoop-3.2.1/ root@centos03:/opt/
8)打开/etc/profile,配置hadoop环境变量
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source /etc/profile
6.启动hadoop
格式化
hdfs namenode -format
启动服务
start-all.sh
7.查看各个节点启动进程
[root@centos01 hadoop]# jps
10882 ResourceManager
10244 NameNode
10389 DataNode
10617 SecondaryNameNode
11018 NodeManager
11371 Jps
datanode在centos01上也有
每台主机都是一个节点,都有NodeManager,都需要节点管理
都有DataNode,说明数据存储是分布在三台主机上的
其他的就是centos01上多出来的
centos01上多出来的主要就是namenode
namenode是我们范围hdfs的文件入口,文件系统的元数据信息
8.关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
9.打开网址(centos01)
http://192.168.0.151:9870/
http://192.168.0.151:8088/
10.上传hadoop-3.2.1.tar.gz文件
hadoop fs -put hadoop-3.2.1.tar.gz /
注:put: .': No such file or directory:hdfs://centos01:9000/user/root’(没有路径)
结果
1.http://192.168.0.151:9870/

2.http://192.168.0.151:8088/cluster/nodes















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









