







- NTU&Microsoft CVPR24
- https://github.com/Wangt-CN/DisCo
- 问题引入
- 提高human motion transfer模型的泛化性;
- 给出 f , g f,g f,g作为参考图片的前背景,然后给出单个pose p = p t p=p_t p=pt或者pose序列 p = { p 1 , p 2 , ⋯ , p T } p = \{p_1,p_2,\cdots,p_T\} p={p1,p2,⋯,pT},目标是生成对应的单张图片 I t I_t It或者视频 V = { I 1 , I 2 , ⋯ , I T } V = \{I_1,I_2,\cdots,I_T\} V={I1,I2,⋯,IT},生成的结果需要同时和提供的 f , g , p f,g,p f,g,p相符合,并且具有泛化性,以可以生成训练数据之外的场景,并且可以任意组合上面三种条件;
- methods
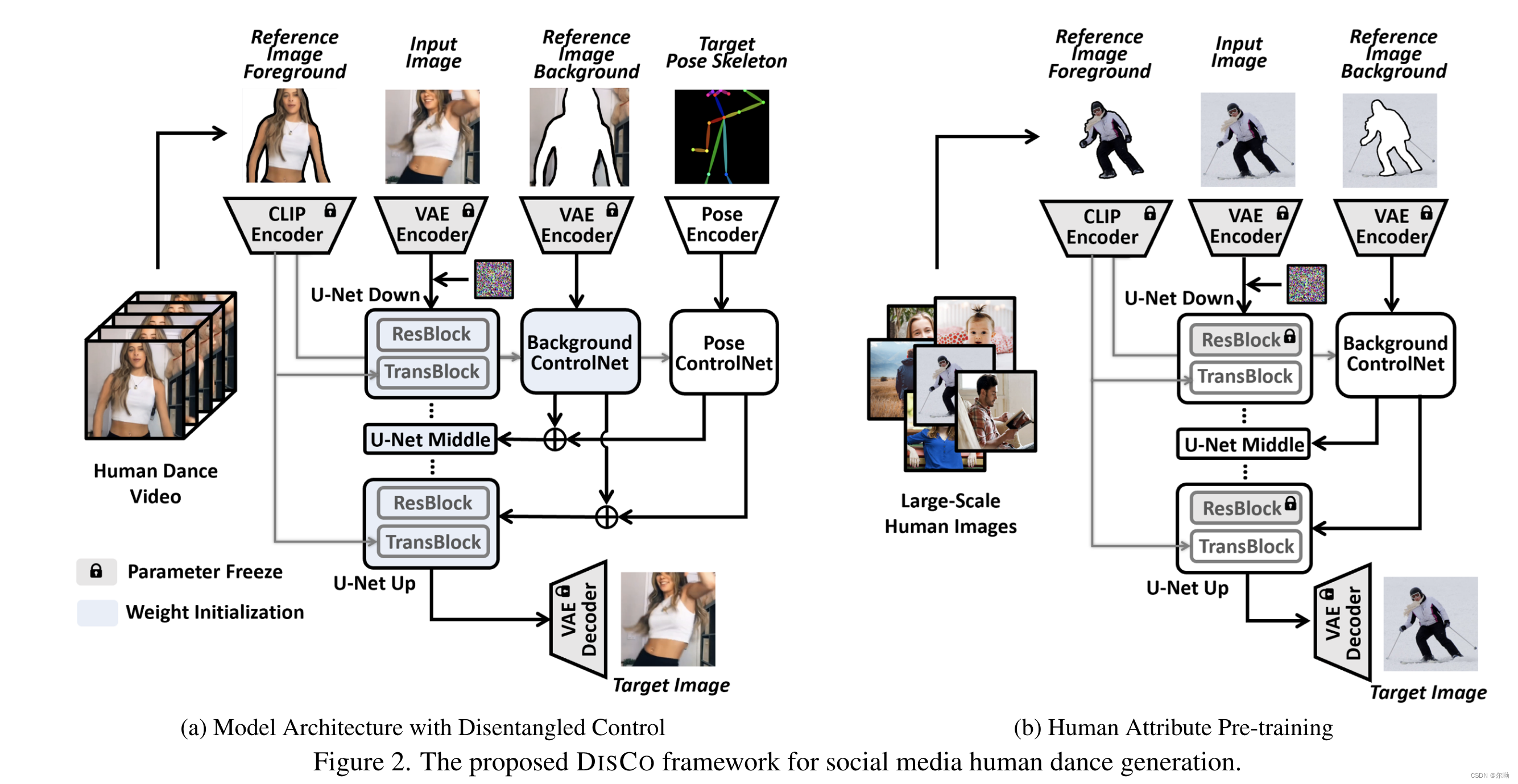
- 前景的条件控制:模型使用image variation SD来初始化,将cross attn中的text embedding c t e x t ∈ R l × d c_{text}\in\mathbb{R}^{l\times d} ctext∈Rl×d换成clip得到的image embedding c f ∈ R h w × d c_{f}\in\mathbb{R}^{hw\times d} cf∈Rhw×d,这个embedding是在全局池化层之前的;
- pose和背景的控制通过controlnet完成;
- Human Attribute Pre-training:增强模型的泛化性,通过在预训练,预训练模型去掉了pose controlnet;
- 实验:
- TikTok dataset数据集训练和测试;

















 2094
2094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









