







一、数据集介绍
NGSIM(Next Generation Simulation)数据集是美国FHWA搜集的美国高速公路行车数据,它包括了US101、I-80等道路上的所有车辆在一个时间段的车辆行驶状况。数据是采用摄像头获取,然后加工成一条一条的轨迹点记录。
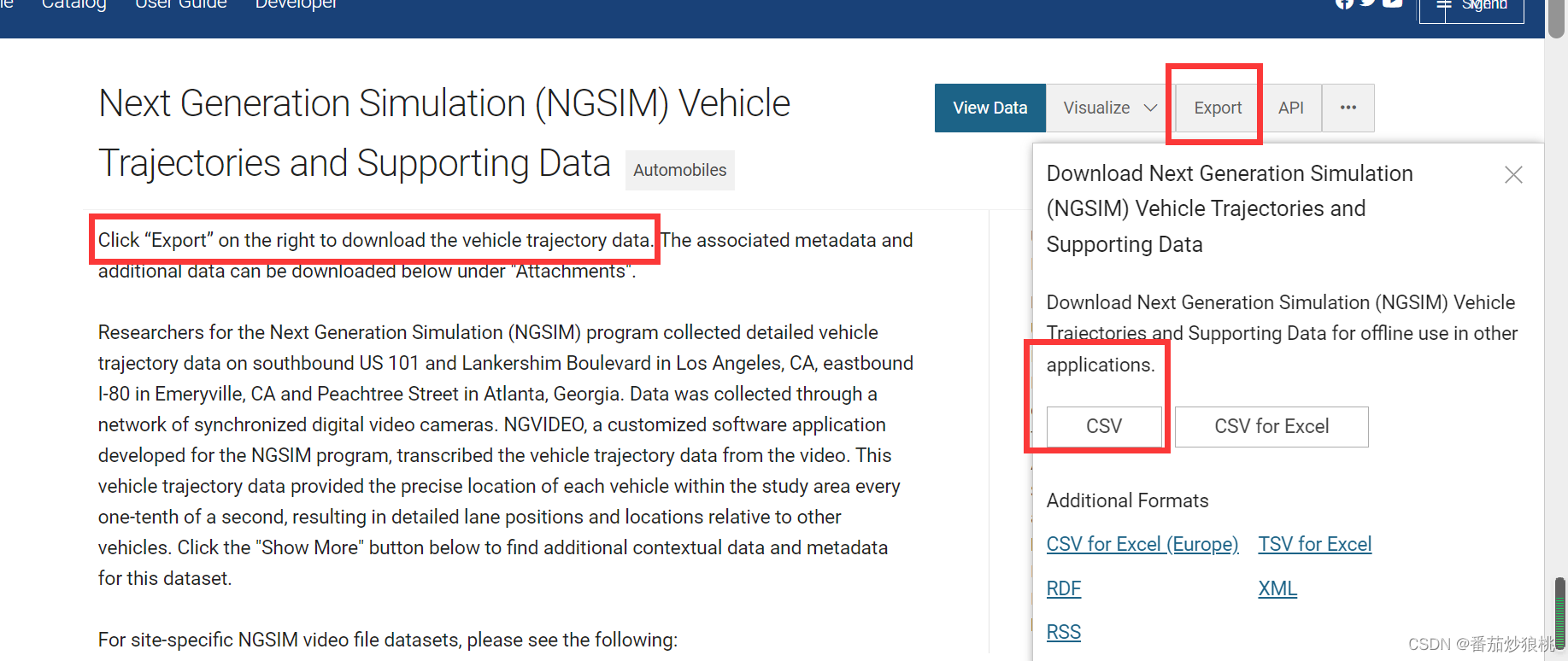
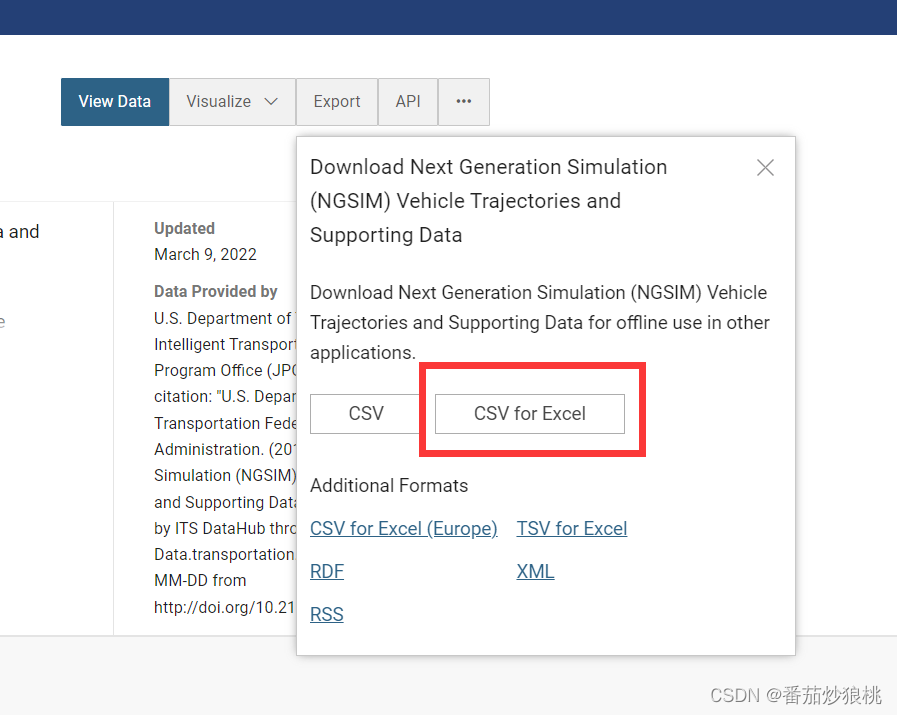
下载的时候注意点击Export然后选择CSV或CSV for Excel下载
二、常见数据类型总结
此处借鉴了知乎@令狐小侠侠大佬的回答
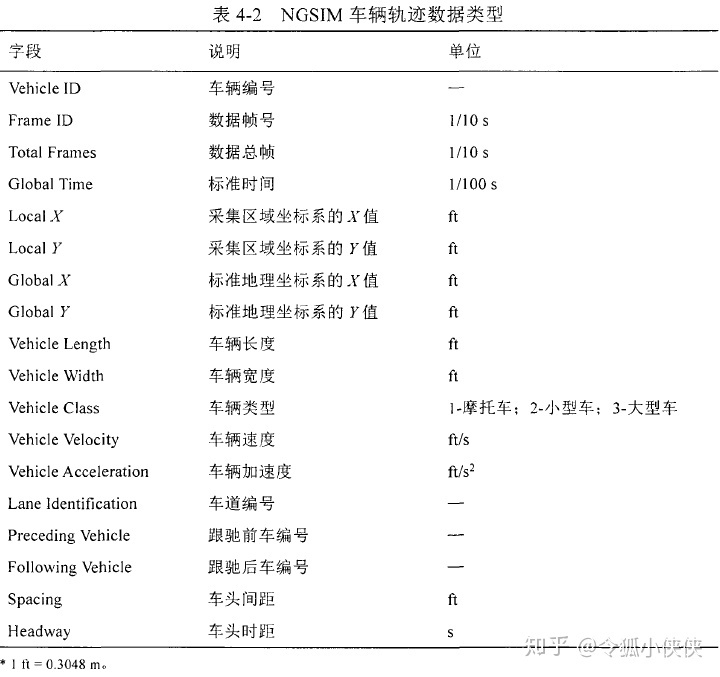
下面是详解:(仅针对部分重要且常用的数据类型进行介绍)
注:不同的道路其车道信息不同,行车数据差异较大

三、代码解析
以下是main函数部分
import pandas as pd
import os
import json
import random
#抽取出US101数据,定义应该函数按照全局时间进行筛选
def cutbyRoad(df=None, road=None):
'''
:param df: 打开后文件
:param road: 路段名称
:return: 切路df,按照全局时间排序
'''
road_df = df[df['Location'] == road]
return road_df.sort_values(by='Global_Time', ascending=True)
#需要的数据是某一区域内,某一时刻的车辆及它们未来10s的行车数据
#首先要获得某一区域某一时刻的车辆ID列表:
def cutbyRoad(df=None, road=None):
'''
:param df: 打开后文件
:param road: 路段名称
:return: 切路df,按照全局时间排序
'''
road_df = df[df['Location'] == road]
return road_df.sort_values(by='Global_Time', ascending=True)
#原数据集的单位,时间是ms,长度单位全是ft。给它转换一下:
def unitConversion(df):
'''
转换后长度单位为m,时间单位为0.1秒
:param df: 被转换df
:return: 转换后df
'''
ft_to_m = 0.3048
df['Global_Time'] = df['Global_Time'] / 100
for strs in ["Global_X", "Global_Y", "Local_X", "Local_Y", "v_length", "v_Width"]:
try:
df[strs] = df[strs] * ft_to_m
except:
df[strs] = df[strs].apply(lambda x: float(x.replace(',', ''))) * ft_to_m
df["v_Vel"] = df["v_Vel"] * ft_to_m * 3.6
return df
def cutbyPosition(road_df, start_y=0, start_time=0, area_length=50):
'''
给定起始时间,起始y,区间长度,输出区间内车辆list
:param road_df:限定路段后的df
:param start_y: 区域开始段,单位为m
:param start_time: 起始时间,0.1s
:param area_length: 区域长度单位为m
:return: vehicle_list为起始框内部车辆编号
'''
#设定开始时间(在US101的基础上限定全局开始时间
area_df = road_df[road_df['Global_Time'] == start_time]
#设置开始时间后,设定原点位置(即其实的纵坐标),相当于设定好了车道周围的区域(纵向范围)
area_df = area_df[(area_df['Global_Y'] - start_y <= area_length) & (
area_df['Global_Y'] - start_y >= 0)]
#unique()函数去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表
#返回在限定范围内对应的车辆编号(可能会有不同车辆重复利用的情况,因此进行删除)
vehicle_list = area_df['Vehicle_ID'].unique()
#返回限定范围内的车辆的编号(大于2辆才返回,若仅有自身则无需返回)
if len(list(vehicle_list)) <= 2:
return None
else:
return list(vehicle_list)
# start_y, start_time可以根据自己的需要取Global_Y,Global_Time的最大值最小值区间内值。
#定义函数迭代获取10s内车辆数据(此处为限定持续时间)
def cutbyTime(road_df, start_time=0, vehicle_list=None, time_length=10.0, stride=1):
'''
:param inint_df:road_df
:param start_frame: 开始帧
:param time_length: 采样时间长度,单位为s
:param stride: 采样步长
:return: 返回一组清洗完数据time
'''
#isin函数多用来清洗数据,删选过滤掉DataFrame中一些行
#Pandas isin()方法用于过滤数据帧。isin() 方法有助于选择在特定列中具有特定(或多个)值的行
#取出之前筛选好的路段:
temp_df = road_df[road_df['Vehicle_ID'].isin(vehicle_list)]
#DataFrame是一种数据类型,其单元格可以存放数值、字符串等,
#这和excel表很像,同时DataFrame可以设置列名columns与行名index
one_sequence = pd.DataFrame()
for vehicle in vehicle_list:#对在限定范围内的车辆ID进行检索
for time in range(int(time_length * 10 / stride)):#此处提取10个10s的片段
df = temp_df[#跳转到下一个时间段
(temp_df['Vehicle_ID'] == vehicle) & (temp_df['Global_Time'] == (start_time + time * stride))]
if df.shape[0] == 1:
one_sequence = pd.concat([one_sequence, df])
else:
return None
return one_sequence
#定义函数存储CSV
def saveCsv(df, file_name):
'''
:param df: 存入df
:param file_name: 文件名
:return: 无
'''
df = df.reset_index(drop=True) # 重置索引
if not os.path.exists('//'):
os.makedirs('//')
df.to_csv('data//' + file_name + '.csv', mode='a', header=True)
with open("……//dataExecute.json", "r") as f:
conf = json.load(f)
# 打开csv数据
init_df = pd.read_csv(conf['data_source'], usecols=conf['useCols'], nrows=1000000)
# 获得us-101数据,并且按照GlobalTime排序
road_df = cutbyRoad(init_df, road=conf['road'])
# 单位转成米(m)和秒(s)
road_df = unitConversion(road_df)
# 限定 坐标范围、时间范围
min_Global_Y, max_Global_Y = road_df['Global_Y'].min() + 100, road_df['Global_Y'].max()
min_Global_Time, max_Global_Time = road_df['Global_Time'].min(), road_df['Global_Time'].max()
# 坐标分组数、时间分组数
total_dist = int((max_Global_Y - min_Global_Y) / (conf['area_step']))
total_time = int((max_Global_Time - min_Global_Time) / (conf['time_step'] * 10))
print("共计{}--{}组数据,时间步长为{},距离步长为{}".format(total_dist, total_time, conf['time_step'], conf['area_step']))
total_data = 0
# 坐标、时间 开始的分组
for dist_index in range(conf["hist_dist"], total_dist):
for time_index in range(conf["hist_time"], total_time):
if conf["noise"]:
time_noise = random.randint(0, 100)
dist_noise = random.randint(0, 100)
else:
time_noise, dist_noise = 0, 0
# 开始时间和坐标
start_time = min_Global_Time + time_index * conf['time_step'] * 10 + time_noise * 10
start_y = min_Global_Y + dist_index * conf['area_step'] + dist_noise
vehicle_list = cutbyPosition(road_df, start_y=start_y, start_time=start_time,
area_length=conf['area_length'])
if vehicle_list is None:
# print('{}秒时刻,{}为起点区域内车辆过少,进入下个时段'.format(start_time * 0.1, start_y))
print('{}--{}内车辆过少,进入下个时段'.format(dist_index, time_index))
continue
one_sequence = cutbyTime(road_df, start_time=start_time, vehicle_list=vehicle_list,
time_length=conf['time_length'],
stride=conf['stride'])
if one_sequence is None:
# print('{}时刻,{}为起点区域内车辆存在消失,进入下个时段'.format(start_time * 0.1, start_y))
print('{}--{}内车辆存在消失,进入下个时段'.format(dist_index, time_index))
else:
total_data += 1
saveCsv(one_sequence, file_name=conf['road'])
print('{}/{} - {}/{} saved! Exist {} data! '.format(dist_index, total_dist, time_index, total_time,
total_data))
if total_data == conf["need_num"]:
print("数据采集完成")
break
if total_data == conf["need_num"]:
print("数据采集完成")
break
同时此处为了方便修改,利用json文件进行传参(下面的data_source更改为下载的CSV的地址)
{
"data_source": "……data//data.csv",
"road": "us-101",
"useCols": [
"Vehicle_ID",
"Frame_ID",
"Total_Frames",
"Global_Time",
"Global_X",
"Global_Y",
"Local_X",
"Local_Y",
"v_length",
"v_Width",
"v_Class",
"Location",
"v_Vel",
"Lane_ID"
],
"area_length": 80,
"time_length": 10,
"area_step": 20,
"time_step": 30,
"stride": 5.0,
"hist_dist":6,
"hist_time":0,
"noise": 1,
"need_num": 20
}
















 6134
6134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









