






一. 写在前面
近期会开个新的专栏,我会把近期看到的比较有意思的论文做个总结,顺带分享给大家,旨在帮助读者高效了解领域相关论文,欢迎各位同学和老师一起讨论,有问题还请指正!不是很忙的话会持续更新。
今天带来的是ECCV 2024的一篇行人轨迹预测的文章,这篇论文读起来很顺畅,通俗易懂,写作值得学习,参考文献如下:

论文题目:Progressive Pretext Task Learning for Human Trajectory Prediction
二. 前言
这篇论文考虑了人类轨迹预测中的短期预测和长期预测分别存在的特点,即短期预测需要考虑即时的变化(短期动态变化),而长期预测则需要捕捉长期依赖性以获取全局的趋势。然而,传统的方法往往用一个单一的、统一的训练范式来解决短期和长期的预测,这种方式不得不使得模型在短期和长期预测表现之间妥协(鱼和熊掌不可兼得)。
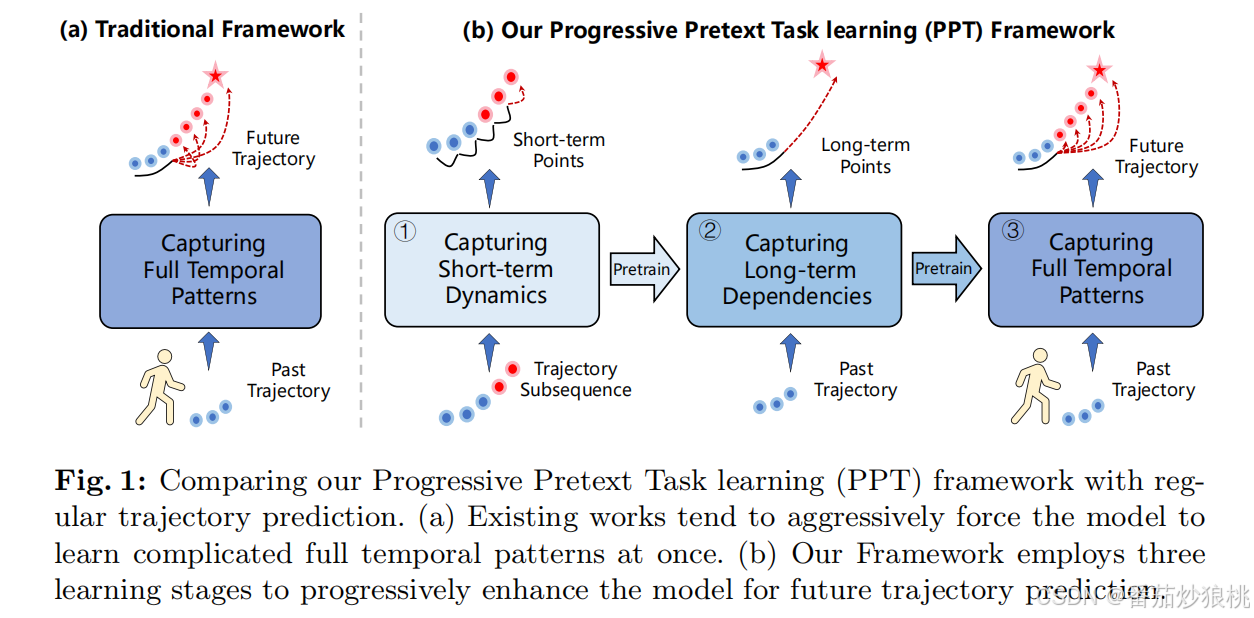
相比之下,作者提出了一种新的渐进式预设任务学习(PPT)框架,通过引入渐进式预设学习任务,帮助模型逐步捕捉整个未来轨迹预测的复杂短期动态和长期依赖。此外,作者们还提出了一个transformer-based轨迹预测器,并采用goal-based的策略进行预测(换而言之,先预测最终目的地,再预测起点和终点直接的轨迹)
三. 论文综述部分
(此小节方便起见基本都是直接翻译了,对领域了解较多的同学可以跳过)
人类轨迹预测的目的是在给定观察到的运动序列的情况下预测合理的未来路径。考虑到人类运动的不确定性,这项任务尤其具有挑战性,因为需要预测所有时间步长的精确位置坐标,这需要解决短期动态和长期依赖关系。
(1)人类轨迹预测
现有的工作可以简单地分为两个分支:一个分支侧重于场景地图的利用[19,25,34,46,56],另一个分支旨在挖掘运动模式和相互作用[13,17,26,28,36,39,42,47 - 50]。考虑到场景地图建模的计算成本,在本文中,我们遵循后者的分支,探索一种更有效的方法来理解轨迹内的时间运动模式。为完成这一任务,我们做了很多努力。例如,Gupta等人[13]最初提出利用基于gan的[10]网络,并通过直接将未来轨迹中的各个时间位置与GT对齐而不进行微分来训练模型。
Gu et al.[12]采用基于变压器的扩散网络,训练模型一次生成整个未来轨迹。然而,这些工作忽略了短期和长期预测学习模式的差异,这些差异导致联合优化过程中的次优性能。虽然最近基于目的地的方法[26,49,57]试图通过首先用一个预测器预测目的地,然后用另一个预测器插值中间位置来缓解这一问题,但它们忽略了目的地预测和中间位置预测之间的知识转移。这导致了目标预测器和轨迹预测器之间的显著差距。为了克服这些限制,我们设计了一个渐进式借口任务学习框架,该框架引入了两个精心设计的借口任务,以逐步增强模型,以捕获整个未来轨迹预测的短期动态和长期依赖关系。
(2)Transformer-baed人类轨迹预测
近年来,Transformer[41,44]体系结构在捕获复杂的顺序依赖关系方面表现出了令人印象深刻的能力。考虑到其有效性,研究人员[9,12,34,37,53,55]越来越多地将Transformer用于人类轨迹预测。例如,STAR[53]将人群建模为图形,并利用基于图形的Transformer来学习人群运动的时空交互作用。此外,Tsao等人使用Transformer作为主干模型,并提出了一些关于交叉序列建模的借口任务。然而,由于它们以自回归的方式生成轨迹点,在推理过程中总是效率低下。最近,MID和TUTR已经尝试在这个任务中探索非自回归变压器。然而,mid[12]依赖于扩散模型,这大大增加了推理时间。TUTR[37]忽略了轨迹中的时间运动动力学,导致性能次优。在这项工作中,我们提出了一种新的非自回归变压器来克服上述限制。与TUTR相比,我们的模型引入了一系列有效的可学习提示来表示未观察到的位置,显著提高了预测性能。
(3)渐进式预训练
到目前为止,渐进式学习技术已经在广泛的任务中进行了探索,包括图像生成[11,14]、图像增强[7,22]、目标检测[4,8,16,29]和运动预测[24,40]。具体而言,Karras等人提出从低分辨率图像开始,然后通过在网络中添加层来逐步提高分辨率。PGBIG[24]利用多个阶段逐步完善对未来帧的初始猜测。Fu等人介绍了一种用于弱光图像增强的渐进式学习策略。在自我知识提炼的过程中,他们逐渐增加弱光图像输入学生分支的比例,旨在逐步提高学生的学习难度。然而,渐进式预训练在人类轨迹预测领域仍未被探索。据我们所知,我们的工作是第一个探索人类轨迹预测中的渐进式预训练,引入了两个精心设计的借口任务,以逐步使模型能够捕获整个未来轨迹预测的短期动态和长期依赖关系。
四. 方法
问题定义:此模型旨在通过利用历史时刻对N个agents的二维坐标(T_1: T_h),预测未来T_f个时刻的N个agents的轨迹。(为了方便,后文统一为T_e=T_f+T_f)
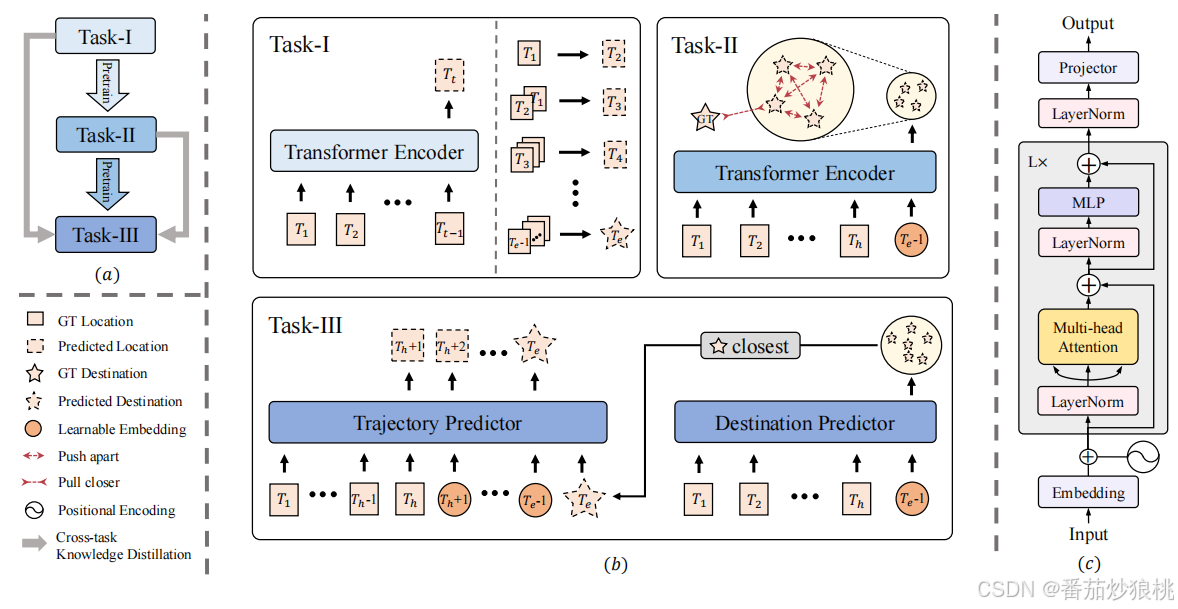
PPT应用Transformer encoder作为backbone(如上图(c)所示), 给定二维位置作为输入,例如,从时间Tm到Tn的二维轨迹序列S^{T_m:T_n},作者首先使用嵌入层将它们转换为输入特征,并通过若干改进的Transformer层((c)子图灰色框)进行编码,最终分别输出下一个时刻的轨迹,即二维轨迹序列S^{(T_m+1):(T_n+1)} ,换而言之,该backbone可以基于每个输入位置,分别预测对应的下一帧位置(eg.输入第t时刻的坐标,输出t+1时刻的位置)
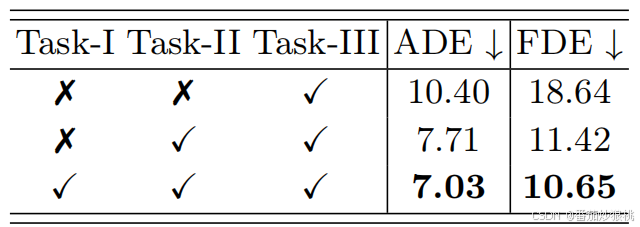
PPT主要包含三个子任务(3个stages):(1)逐步下位预测(翻译的比较直接) (2)终点预测 (3)综合轨迹预测
任务一:下位预测(预测下一time step的位置,聚焦于short-term dynamic)
给定观察到的任意长度的轨迹序列,第一个任务的目标是准确地预测下一个点的位置。此步骤旨在探索运动模式,并了解每个行人轨迹的短期动态。
如上图(b)所示,对于序列 S^{T_1:T_(t-1)},作者先随机采样子序列S^{T_{1}:T_{t−1}},以起到数据增强的作用,然后将其喂入模型θ_I中以预测下一个时刻S^{T_t}。
其实这一步骤就是通过掩码操作,利用现有的步骤,逐步预测下一时刻的轨迹。比如利用T1的观测预测T2时刻的轨迹,紧接着利用T1和T2的轨迹预测T3时刻的轨迹,以此类推,利用T1到T_e-1时刻的观测预测下一时刻T_e的轨迹。
任务二:预测目的地 (goal-based策略,关注long-term依赖性)
第二个阶段通过将历史观测S^{T_1:T_h}作为输入,利用步骤一(任务一)训练好的模型θ_I来预测目的地坐标S^{T_e}。作者们为了采用了Multi-modal的预测方式,即将目的地的输出特征提供给MLP以预测出K个候选目的地(说白了就是一次性预测多个目的地)。
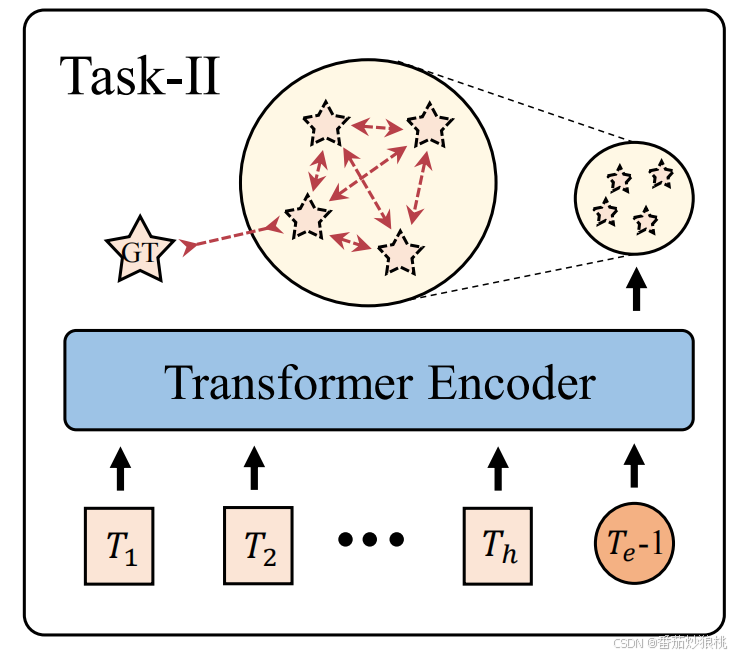
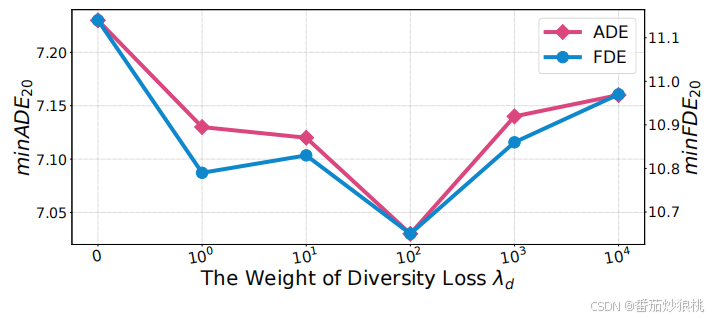
同时,为了保证预测的精度和独特性(防止K个预测目的地陷入相同的模态),作者在第二步中利用两个损失函数分别监督模型训练。
下面是精度Loss,用于计算预测的K个目的地\bar{E_k}和Ground truth目的地E之间的误差。

此外,下面是多样性Loss,监督模型产生更多样化的目的地,从而生成更多样化的轨迹。
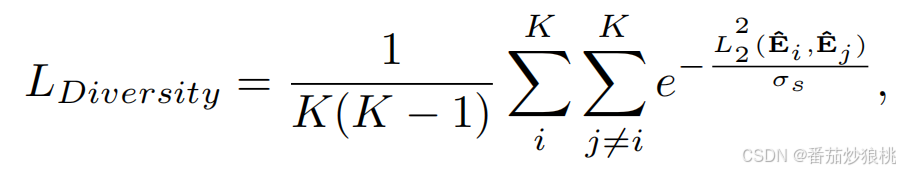
下面是第二个任务最终的Loss形式。
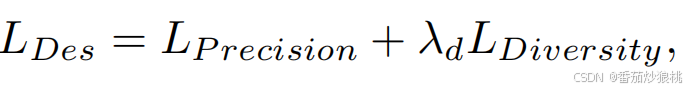
第二步训练得到的模型记为θ_II。需要注意的是,为了与模型θI的输入对齐,作者为每个位置分配了相应的位置编码。然而,由于缺乏未来轨迹的地面真值数据,无法访问第(T_e−1)的位置作为预测T_e时刻位置(目的地)的输入。因此,作者引入了一个可学习的提示嵌入,并将其附加在过去的轨迹序列之后,以一种跨越式的方式预测目的地(也就是我们现在只有T_h个时刻的坐标,那其中缺少的未来轨迹,即T_h+1到T_e-1怎么办呢?干脆就直接在历史时刻填充上)。相当于没有数据的部分,全部利用提示嵌入补充上,以与任务1训练的方式对应(其实这个方法在自动驾驶轨迹预测也挺常见的,goal-based方法)
任务三:预测最终轨迹(跨任务学习)
通过对Task-I和Task-II的训练,模型θII具有理解短期动态(从Task-I获得)和捕获未来轨迹内的长期依赖关系(从Task-II获得)的能力。在最后的任务中,模型将充分利用这些知识预测未来轨迹内的所有位置。
具体而言,作者将模型θII复制为目的地预测器和轨迹预测器,如上图所示。
作者从任务二生成的K个候选目的地中,选择一个最接近Ground Truth (GT)的候选目的地喂入轨迹预测器。
轨迹预测器的输入序列可分为三部分:从T1到Th的观测轨迹,从Th +1到Te−1的未观测未来轨迹,以及在Te的坐标(最近GT的目的地)。对于不可观察的未来轨迹(也就是该阶段还没有预测到的未来轨迹),模型使用可学习的提示嵌入作为输入。有了这些输入,轨迹预测器输出整个未来轨迹的二维位置,即S^{T_{h}+1:T_e}。
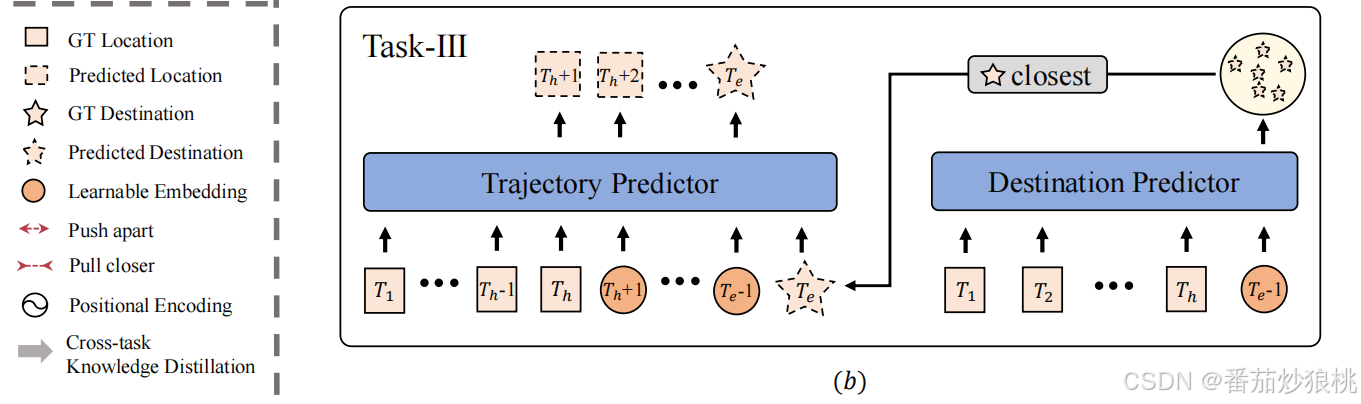
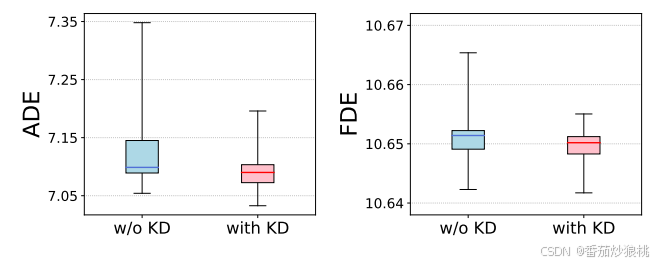
在任务三中,模型联合训练目的地预测器和轨迹预测器来回归整个未来轨迹。为了避免之前的任务的知识被遗忘,作者在Task-III中设计了一个Loss(称为跨任务的知识蒸馏策略)正则化之前的知识。
具体来说,作者分别用以下损失函数来惩罚θI和轨迹预测器,以及θII和目标预测器之间的输出差异:
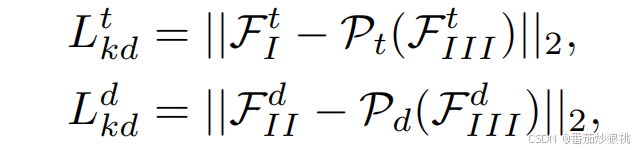
综上,这一阶段的损失函数为:
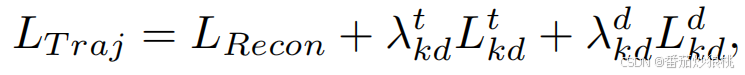
其中L_{Recon}是预测和真实未来轨迹之间的L2距离。λ^{t}_{kd}和λ^{d}_{kd}被用来控制不同损失项之间的权衡。
推理过程
注意,以上三个步骤仅为训练阶段的设置。在对所有三个任务进行训练后,逐步使模型能够预测整个未来轨迹,在推理阶段,仅仅使用训练好的目的地预测器和轨迹预测器进行预测(这样比较轻量化)。也就是首先利用目的地预测器来预测K个目的地。然后,模型将所有生成的目的地都作为轨迹预测器的输入,指导K个未来轨迹的生成。(换而言之,在推理阶段,直接生成K个目的地,并生成其对应的K个轨迹,即Multi-modal prediction)。
总结:渐进式预测下个时刻轨迹+goal-based策略+利用跨任务学习知识并预测轨迹
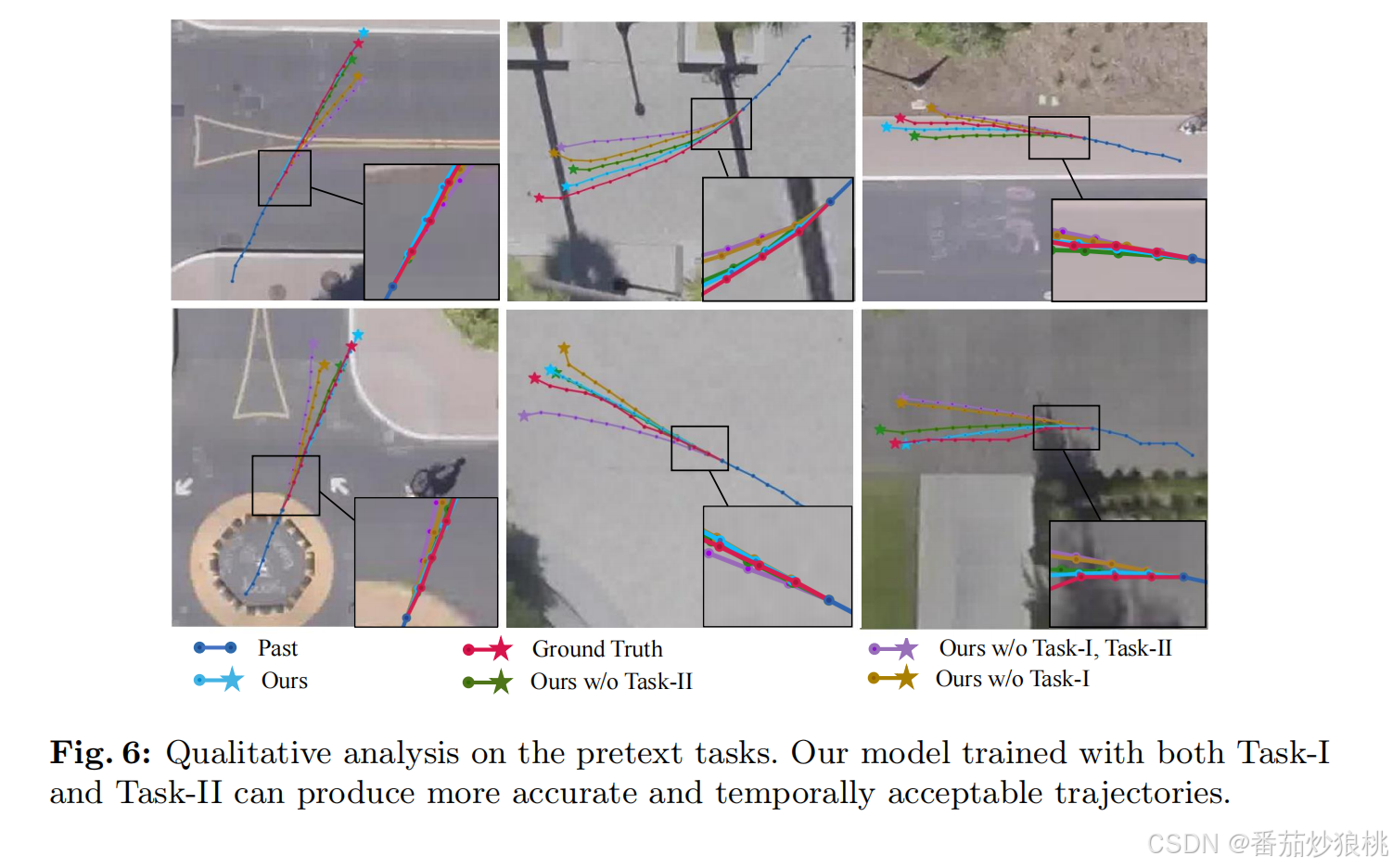
这篇文章注意在训练过程中分为三个步骤,第一个步骤通过预测下一个时刻的位置,聚焦于提取short-term dynamic,第二步骤通过预测K个目的地,学习long-term dependency(缺少数据的时段用提示嵌入补充上)。最后一个步骤通过一个知识整理策略吸收第一和第二个步骤学习到的知识,并利用之前训练好的模型预测整个轨迹。
五. 实验部分
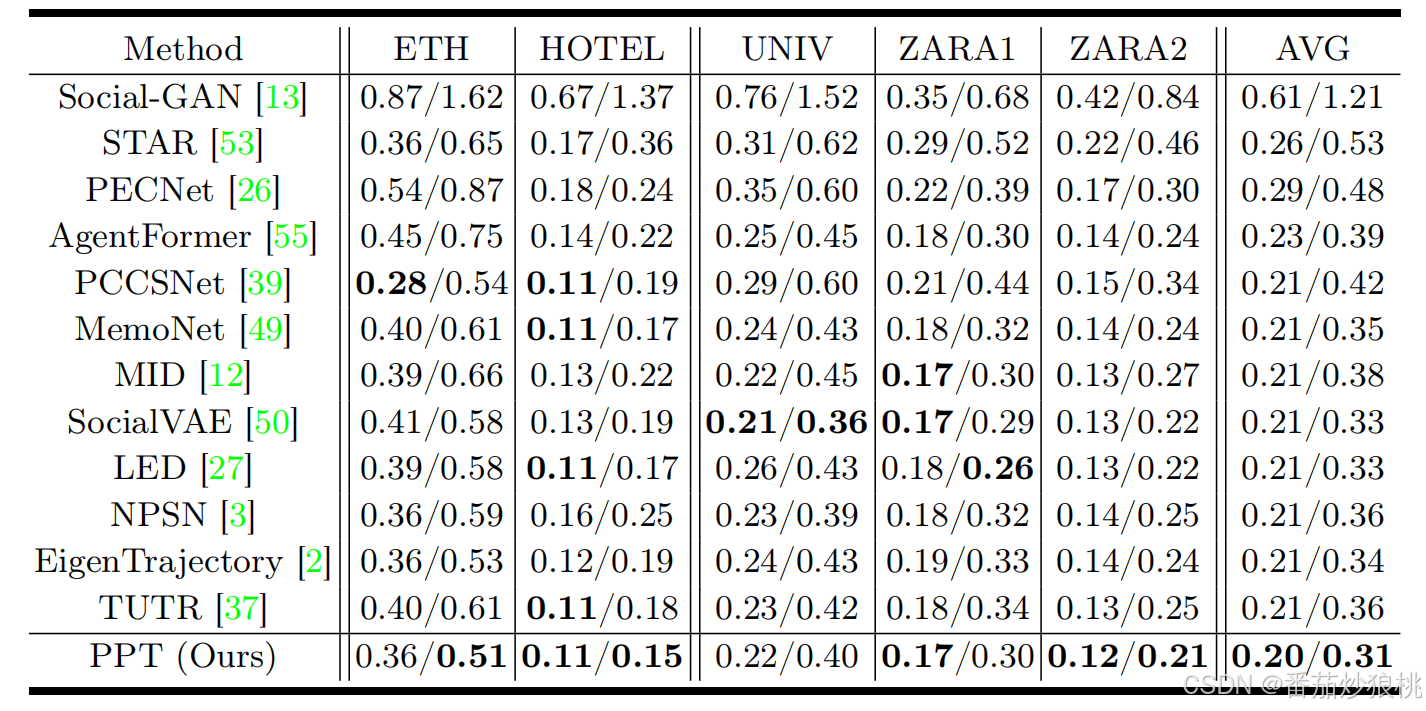
数据集:PPT 框架在四个广泛使用的公共行人数据集上进行了评估:斯坦福无人机数据集(SDD)、ETH/UCY数据集和大中央车站(GCS)数据集。
指标:作者采用平均位移误差(ADE)和最终位移误差(FDE)作为评估指标,分别测量预测轨迹与地面真实(GT)轨迹之间的平均位置距离和目的地距离。 考虑到未来固有的不确定性和人体运动的不确定性,作者为每个过去的轨迹生成 K=20 个未来轨迹,并计算出最小 ADE 和 FDE(Best-of-20 策略)性能。 对于所有数据集,作者将过去的 8 步(3.2秒)作为观察轨迹,并预测接下来的 12 步(4.8秒)。
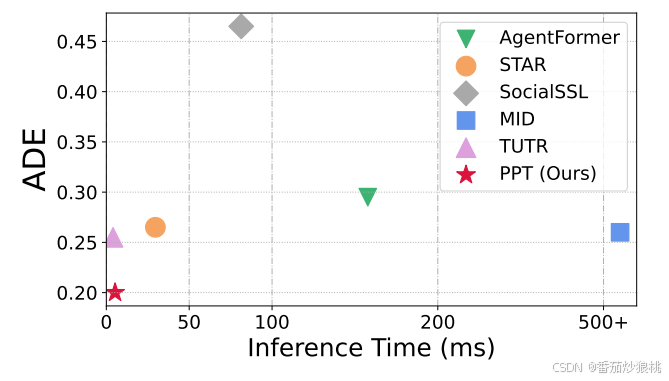
实验结果:不再赘述,具体可以看原文




















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









