






1、MapReduce
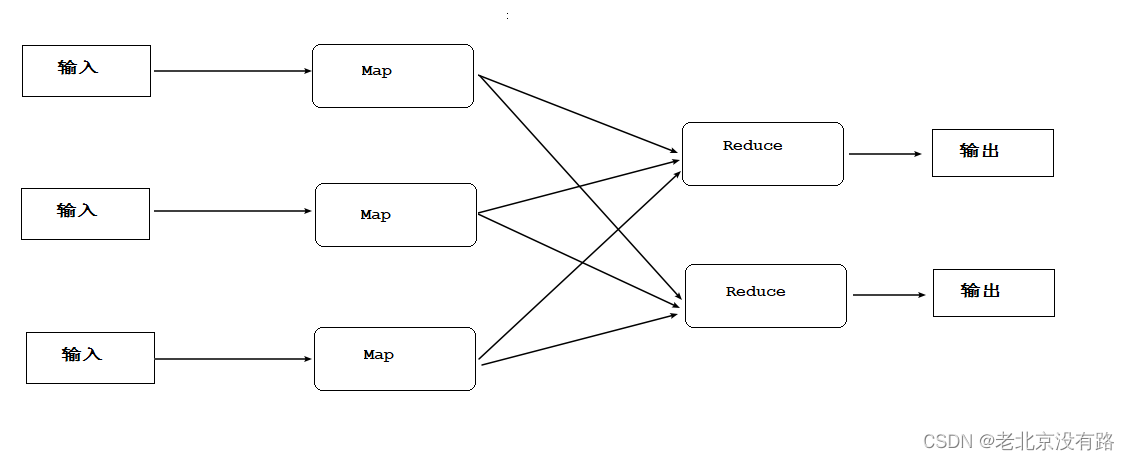
MapReduce 是一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map 和l Reducc两个阶段:
Map阶段: 将任务分解,即把复杂的任务分解成若干个“简单的任务”来行处理,但前提是这些任务没有必然的依赖关系,可以单独执行任务
Reduce阶段:将任务合并,即把Map阶段的结果进行全局汇总。下面通过一个图来描述上述MapReduce 的核心思想

2、MapReduce简易模型

MapReduce编程模型借鉴了函数式程序设计语言的设计思想,其程序实现过程是通过map()和l reduce()函数来完成的。从数据格式上来看,map()函数接收的数据格式是键值对,生的输出结果也是键值对形式,reduce()函数会将map()函数输出的键值对作为输入,把相同key 值的 value进行汇总,输出新的键值对

(1)将原始数据处理成键值对<K1,V1>形式。
(2)将解析后的键值对<K1,V1>传给map()函数,map()函数会根据映射规则,将键值对<K1,V1>映射为一系列中间结果形式的键值对<K2,V2>。
(3)将中间形式的键值对<K2,V2>形成<K2,{V2,....>形式传给reduce()函数处理,把具有相同key的value合并在一起,产生新的键值对<K3,V3>,此时的键值对<K3,V3>就是最终输出的结果。
3、 WorldCount代码编写
3.1map函数定义
/*
KEYIN: K1
VALUIN: V1
KEYOUT:K2
VALUEOUT:V2
*/
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
}
继承Mapper类,重写map方法
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
K1 : 行起始位置 数字 Long ---- > LongWritable
V1 : 一行数据 字符串 String -----> Text
K2 : 单词 字符串 String -----> Text
V2 : 固定数字1 数组 Long -----> LongWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
/**
*
* @param key K1
* @param value V1
* @param context 上下文对象 将map的结果 输出给reduce
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将一行数据 转换成字符串 按照空格切割
String[] arr = value.toString().split("\\s+");
for (String k2 : arr) {
//将单词输出给reduce
context.write(new Text(k2),new LongWritable(1));
}
}
}
3.2reduce函数定义
/*
KEYIN:K2
VALUEIN:V2
KEYOUT:K3
VALUEOUT:V3
*/
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
}
继承Reducer类型重写reduce方法
/*
K2:单词 String ----> Text
V2:固定数字 1 Long ----> LongWritable
K3:单词 String ----> Text
V3:相加后的结果 Long ----> LongWritable
*/
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
/**
*
* @param key K2
* @param values V2的集合 {1,1,1,1}
* @param context 上下文对象 输出结果
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
//将次数相加
for (LongWritable value : values) {
count+=value.get();
}
//写出 k3 v3
context.write(key,new LongWritable(count));
}
}
4、编写启动车程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Test {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//创建配置对象
Configuration conf = new Configuration();
//创建工作任务
Job job = Job.getInstance(conf, "wordCount");
//设置Map类
job.setMapperClass(WordCountMapper.class);
//设置Reduce类
job.setReducerClass(WordCountReducer.class);
//设置map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置读取文件位置 可以是文件 也可以是文件夹
FileInputFormat.setInputPaths(job,new Path("d:\\work\\abc"));
//设置输出文件位置
FileOutputFormat.setOutputPath(job,new Path("d:\\work\\abc\\out_put"));
//提交任务 并等待任务结束
job.waitForCompletion(true);
}
}

报错显示信息在resouces目录下添加log4j.properties
log4j.rootCategory=INFO,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n














 2129
2129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









