







task1
txt2image
先根据config一层层调用
-
先是ldm.models.diffusion.ddpm.LatentDiffusion
里面super().init(conditioning_key=conditioning_key, *args, **kwargs)
然后跑到DDPM类里面
DDPM里面调用了DiffusionWrapper -
然后ldm.modules.diffusionmodules.openaimodel.UNetModel
1困惑这个里面的timestepblock是干什的
2里面有一个encoderUnetModel
其实ddpm就相当于前半部分来获得z,一个encoder的过程
获得一个更好,更感知压缩的情况下attention到更多的特征
用这个ddpm的前半段取代了codebook的离散过程 -
其中encoder是和vqgan1相同的VAE??离散化(连续的高斯?)
ldm.models.autoencoder.AutoencoderKL -
condition 是ldm.modules.encoders.modules.BERTEmbedder
DDIM 减少了step
不满足马尔可夫链条件下的迭代
在ldm中运行
运行txt2image文件
先执行了ddpm文件,调用了LDM方法
里面有model= DiffusionWrapper()
ddpm 中, condition-key 变成了crossattn
unet config 是 openaimodel 文件里的Unetmodel
其中 DiffusionWrapper 里面 model=txt2image.yaml里面里面的配置
第一步在openaimodel里面配置Unet(这里面有transformer)
第一阶段应该是autoencoderKL
第二阶段有条件应该是Bertembedder,这里调用了x_transformer
里面额q与kv相比
然后执行了openaimodel 文件
clip 在ldm/encoders/modules里面用到
Class FrozenCLIPEmbedder(AbstractEncoder):
“”"Uses the CLIP transformer encoder for text

先调用 diffusionWrapper 作为model
参数有 unet-config 和 conditioning-key = ‘crossattn’
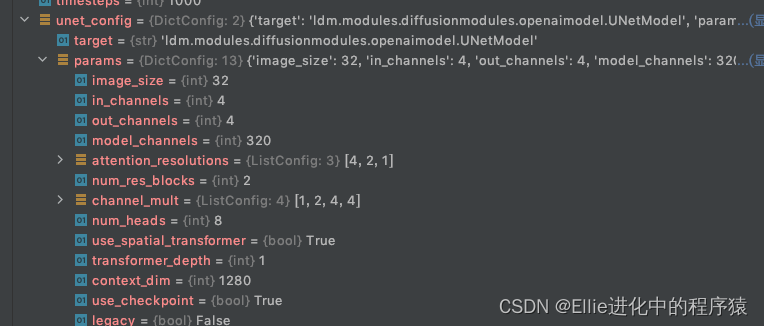
diff_model_config咱也不知是啥,但是是这样调用的
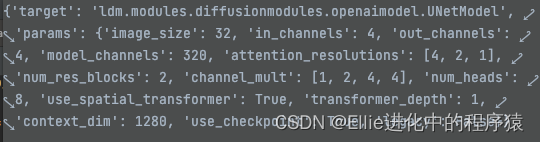
openaimodel下
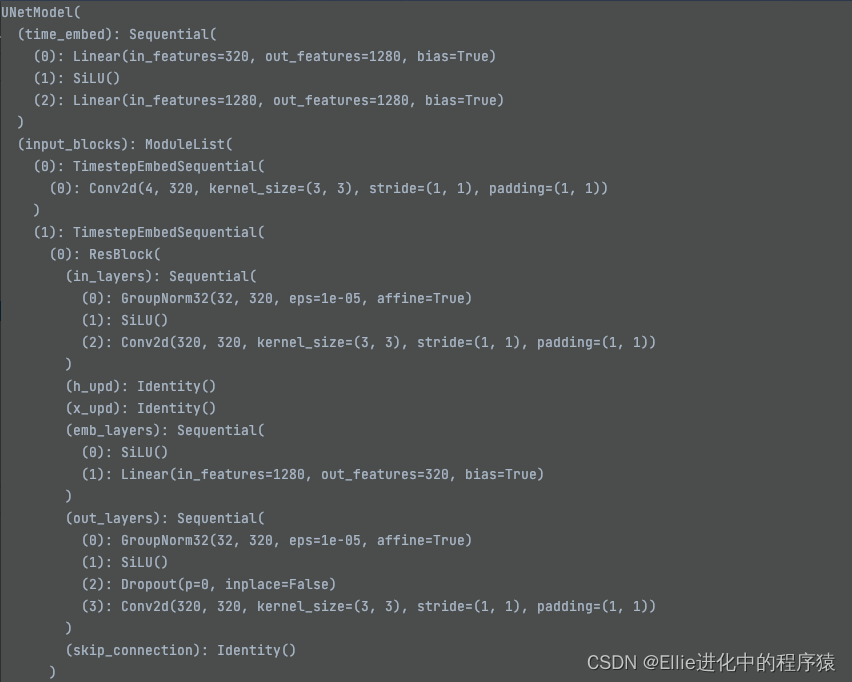
time_embed linear,silu,linear
其中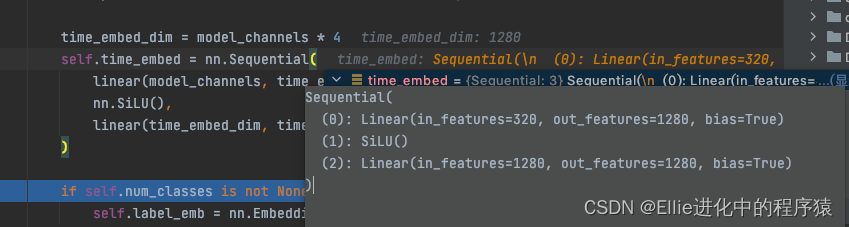
先是一个Unetmodel 不懂modelchannle为什么是320
channel-mult 是啥???
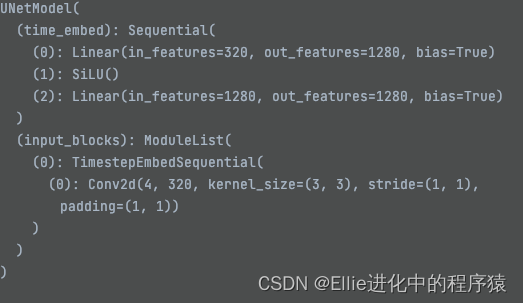
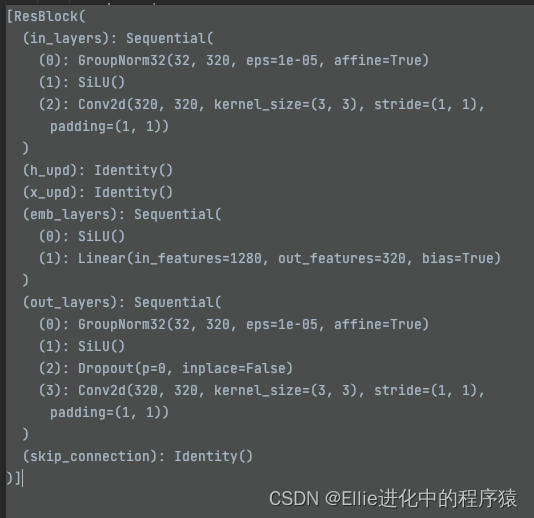
里面用到了restblock 有时间看一下restnet bro
nn.identity 输入是啥输出是啥
restBlock,,,,是2维度的?

zero——module 是二维的????,目前还不懂在干啥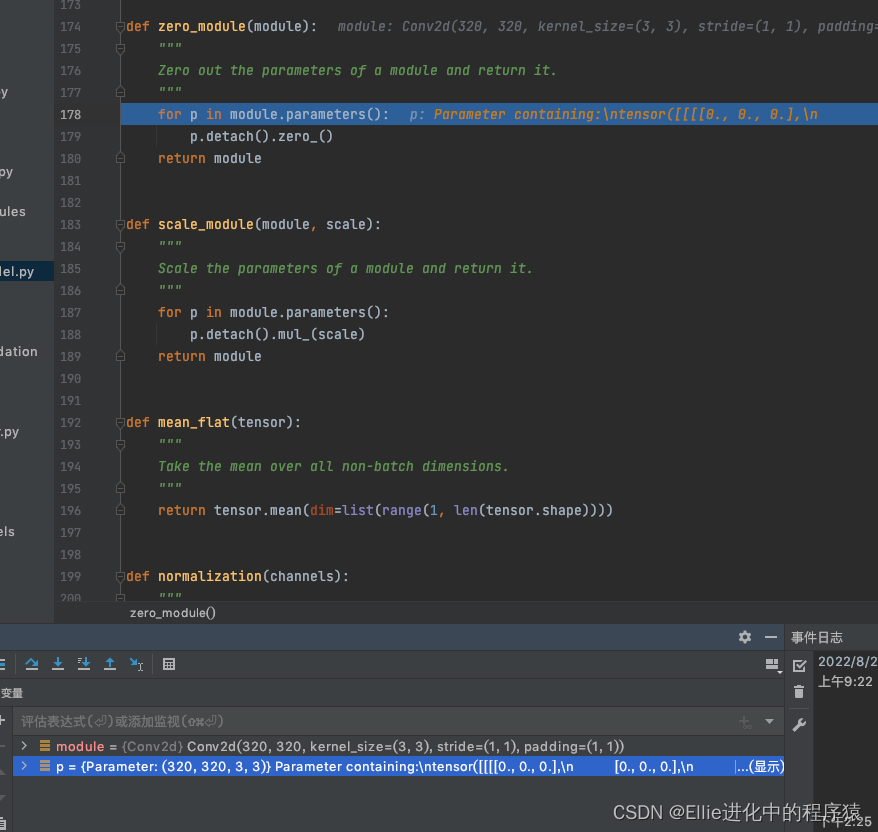
什么num_head 是8 是因为 embed_dim// num_heads_channels 得8、
dim_head = ch // num_heads 得40
越来越不懂,咋回事
去看attention 的实现吧bro
现在跳到attention了
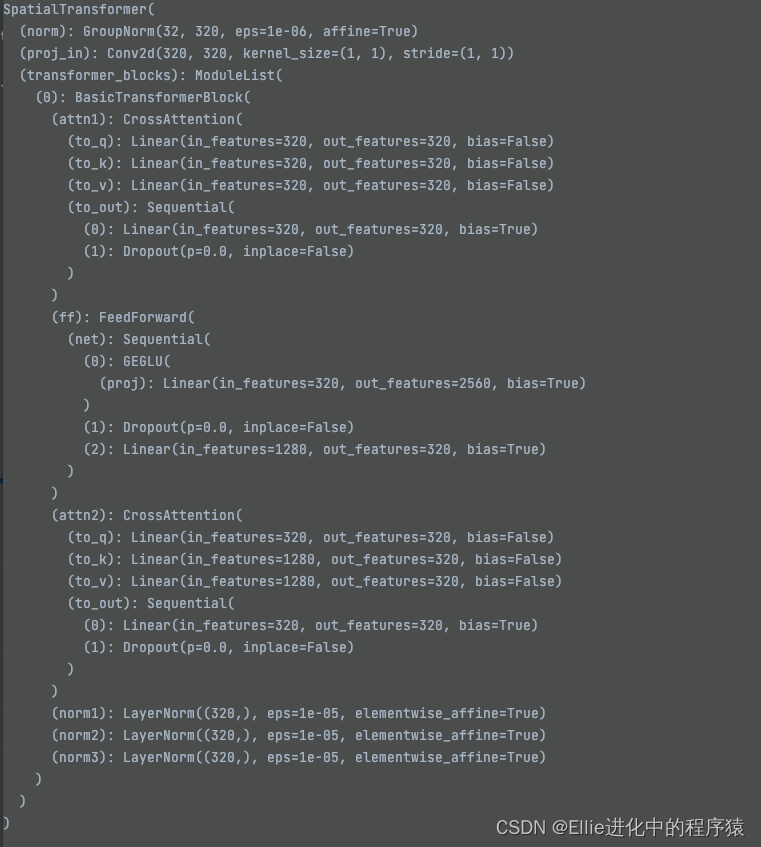
spatial transformer (空间变换)
https://blog.csdn.net/jiaojiaolou/article/details/90383340
STN的作用是想让CNN具备平移、旋转、缩放、剪切不变性,虽然说CNN中的Pooling可以让网络具备一点平移不变性,但这毕竟是隐性的,如果能让网络直接具备这样的能力岂不是更好
提到了仿射变换 将图片进行缩放平移旋转
实现两个空间向量之间的变化
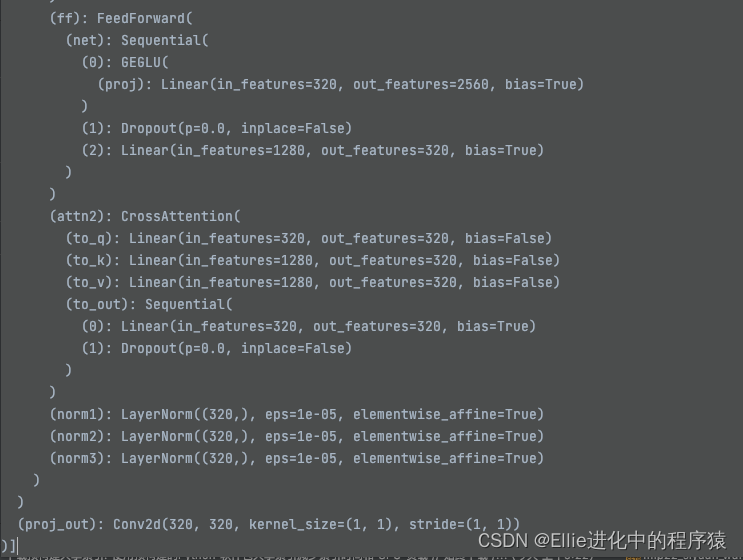
用了crossattention 来完成有条件啥
其中innerdim 是320, context_dim 是320
feedforward 向前传输
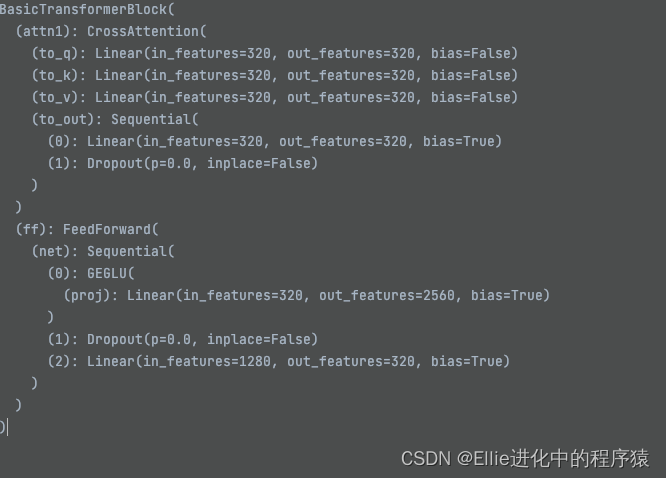
??? 上采样???

3个laryernorm
上面那个变换都是在openaimodel里面
resblock 变成了这样???
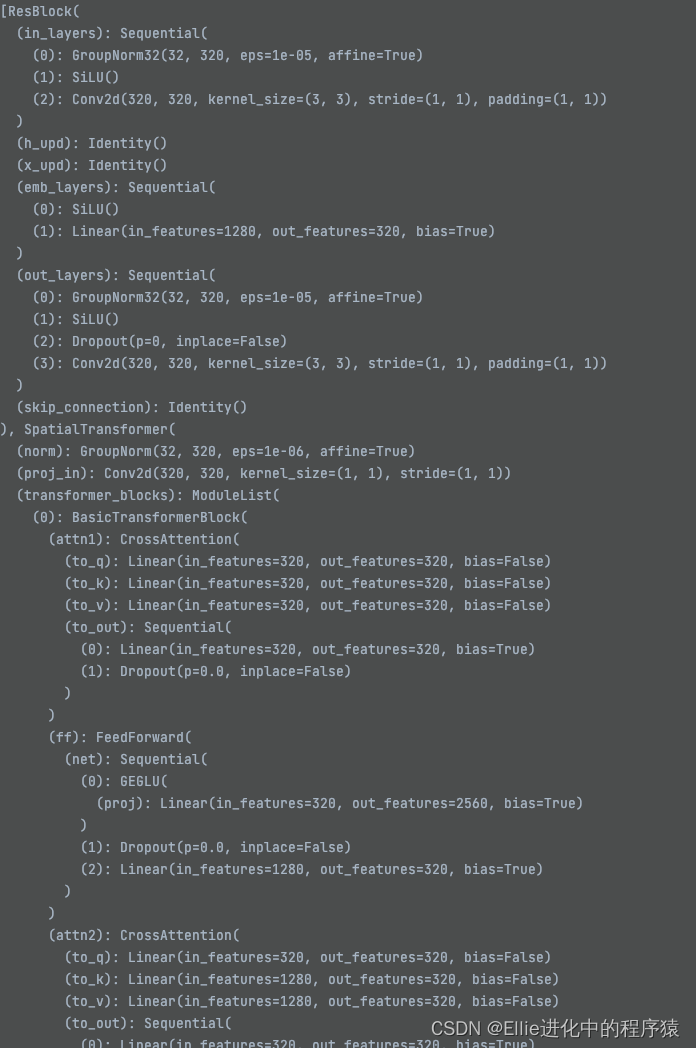
最后,让我们再看一下这个Unet的结构哈
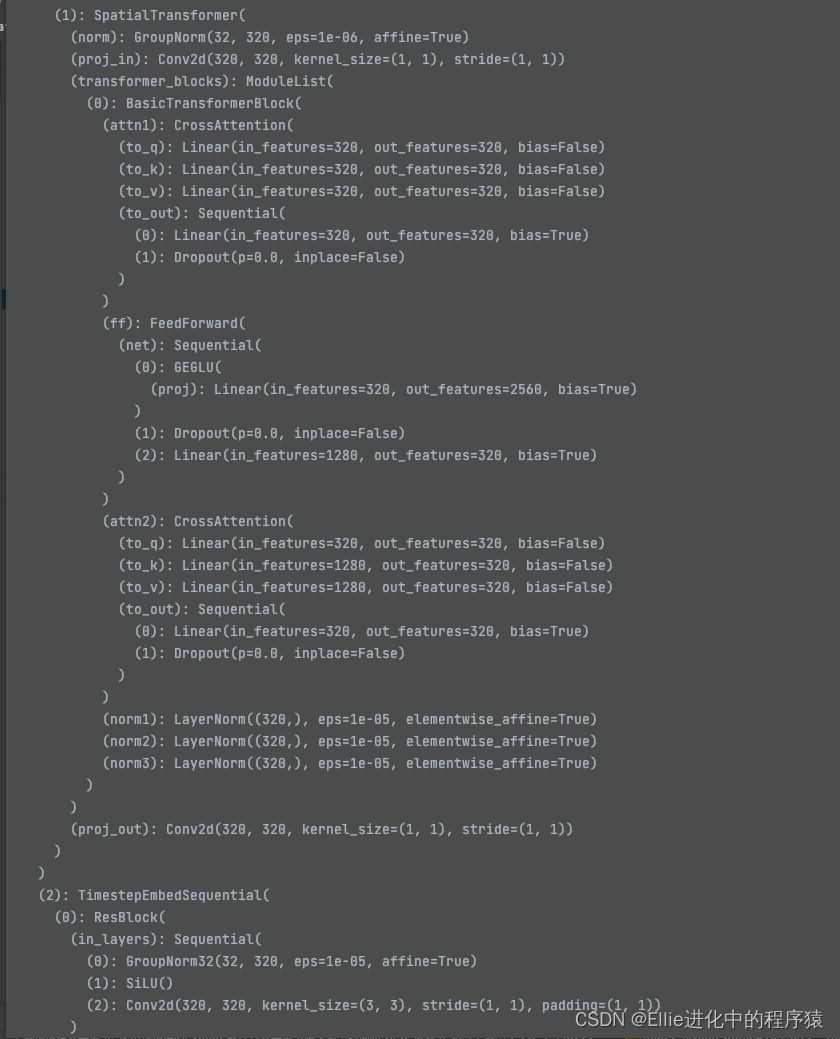
用了?时间序列?
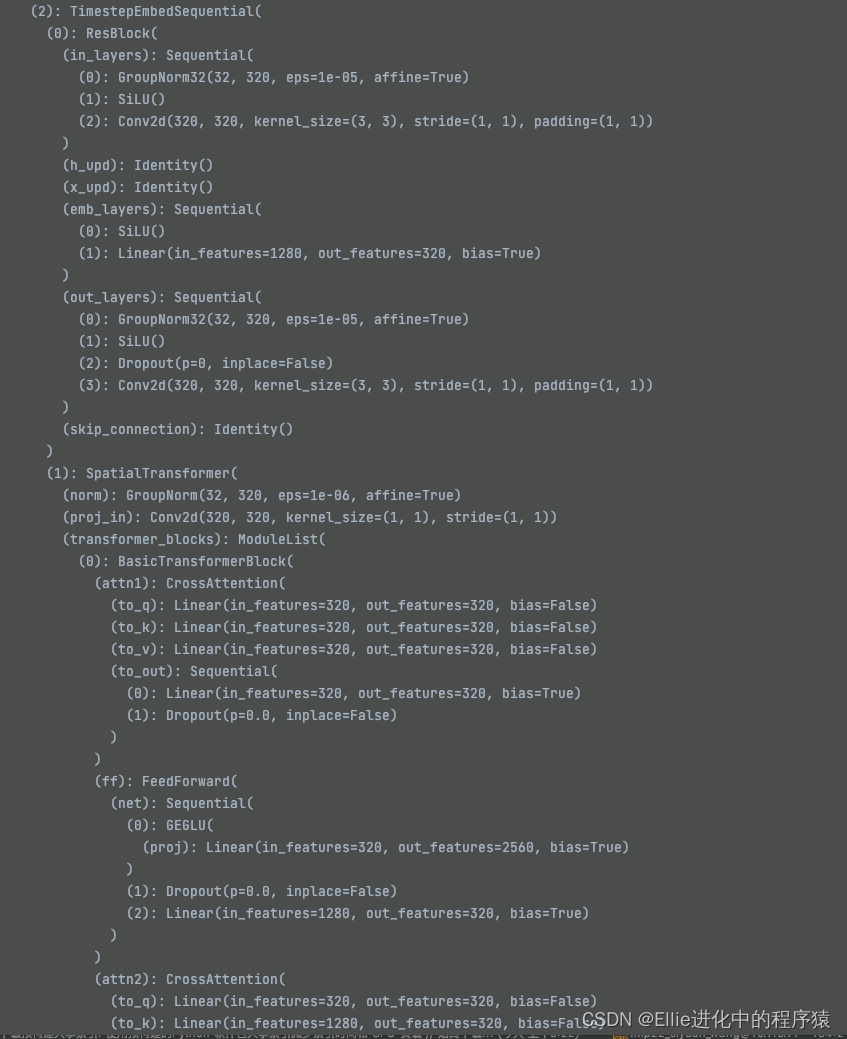
咱也不懂为啥这么设计的
也没人画个图
说清楚里面的结构
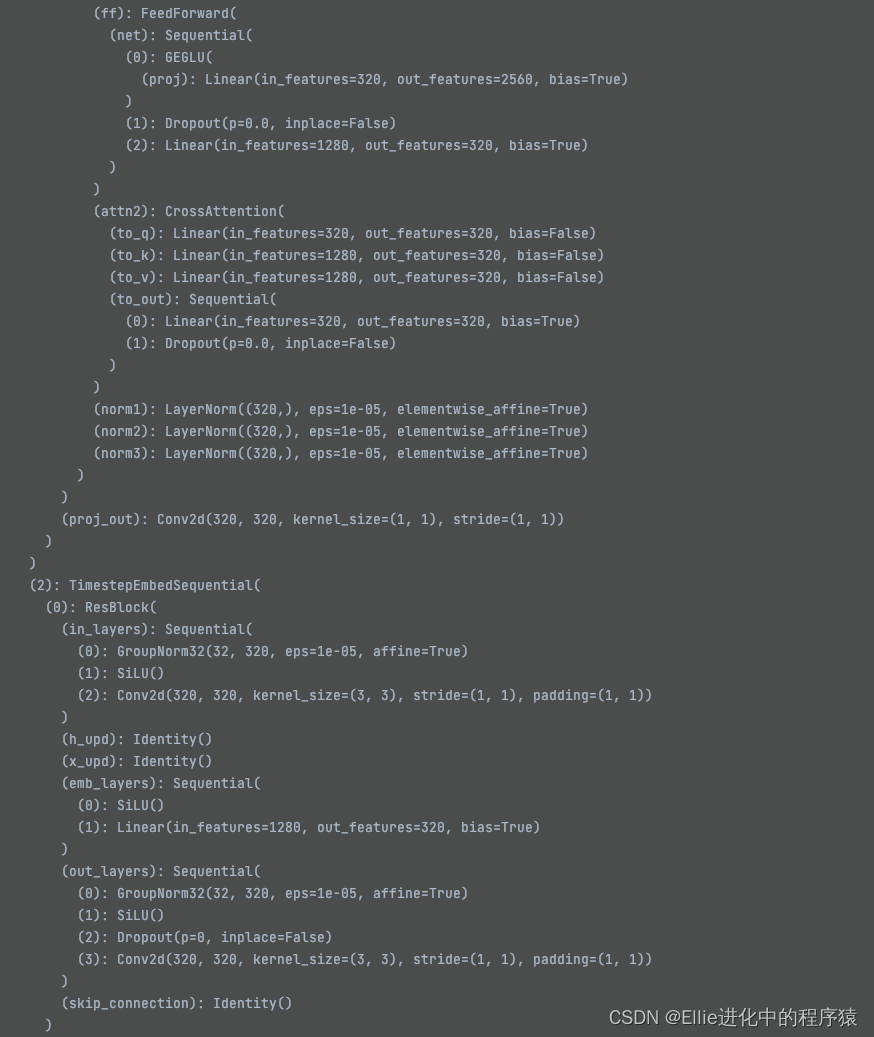
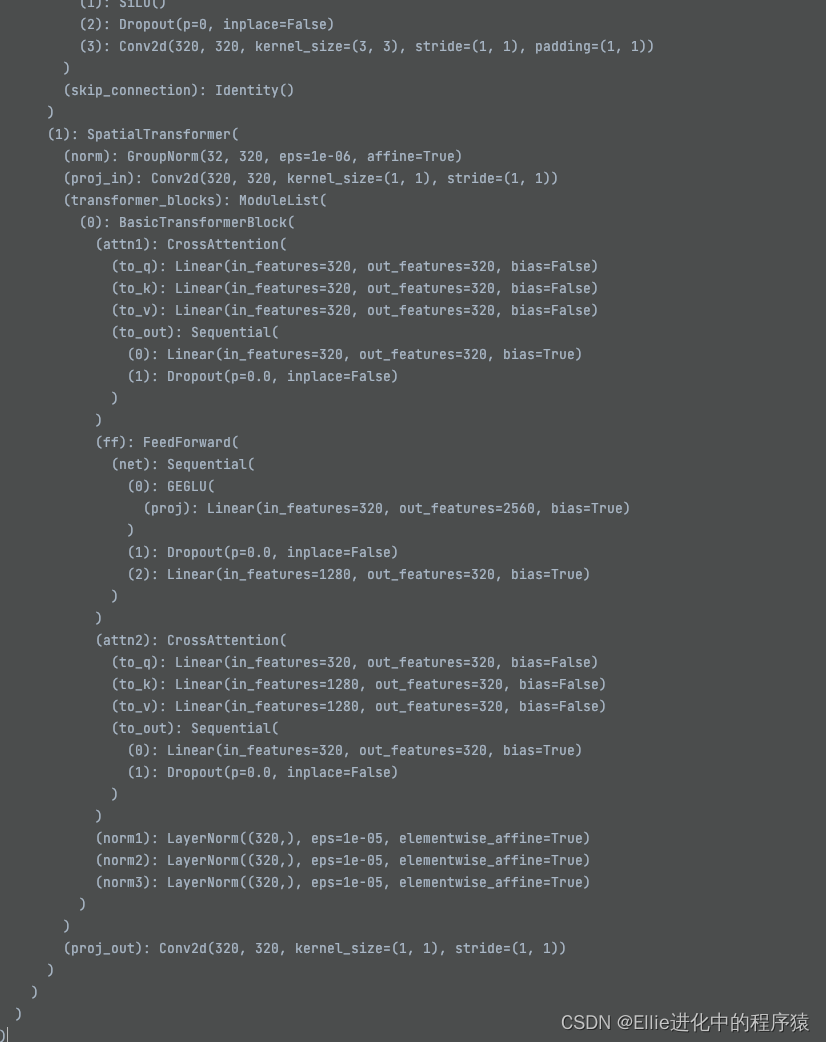
我都不信,这玩意我能学明白。。。。。
11个 TimestepEmbedSquential ??????
我真不懂了。。。。
接下来还是 Unet
middleblock 我谢谢
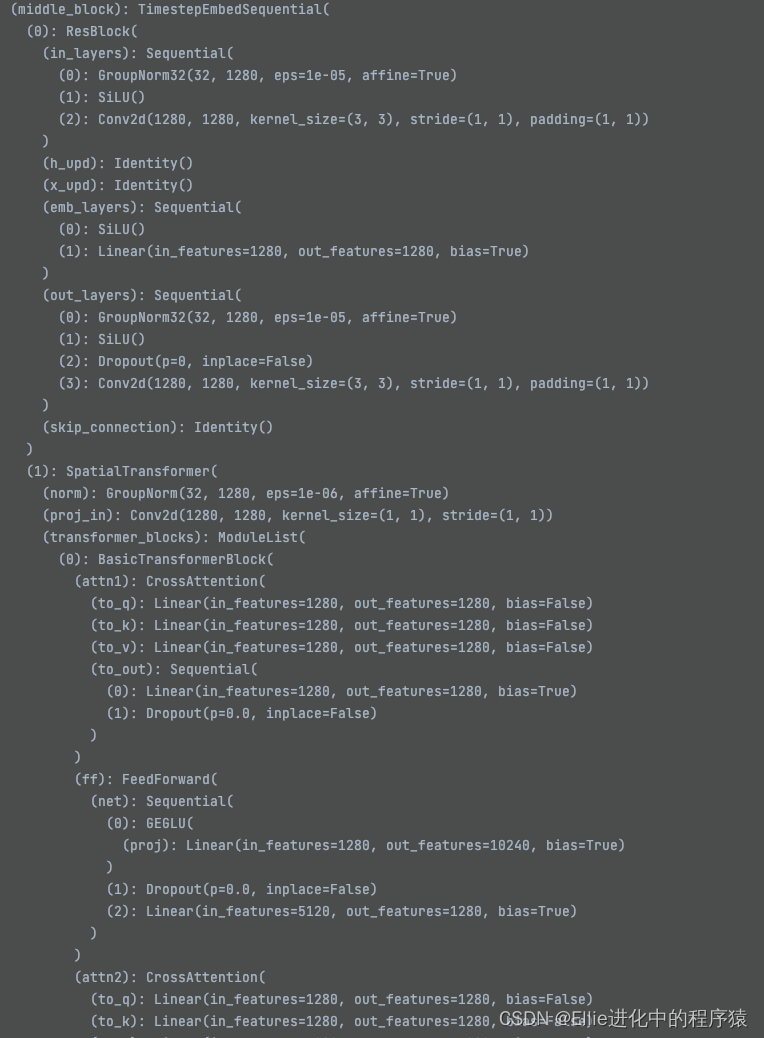
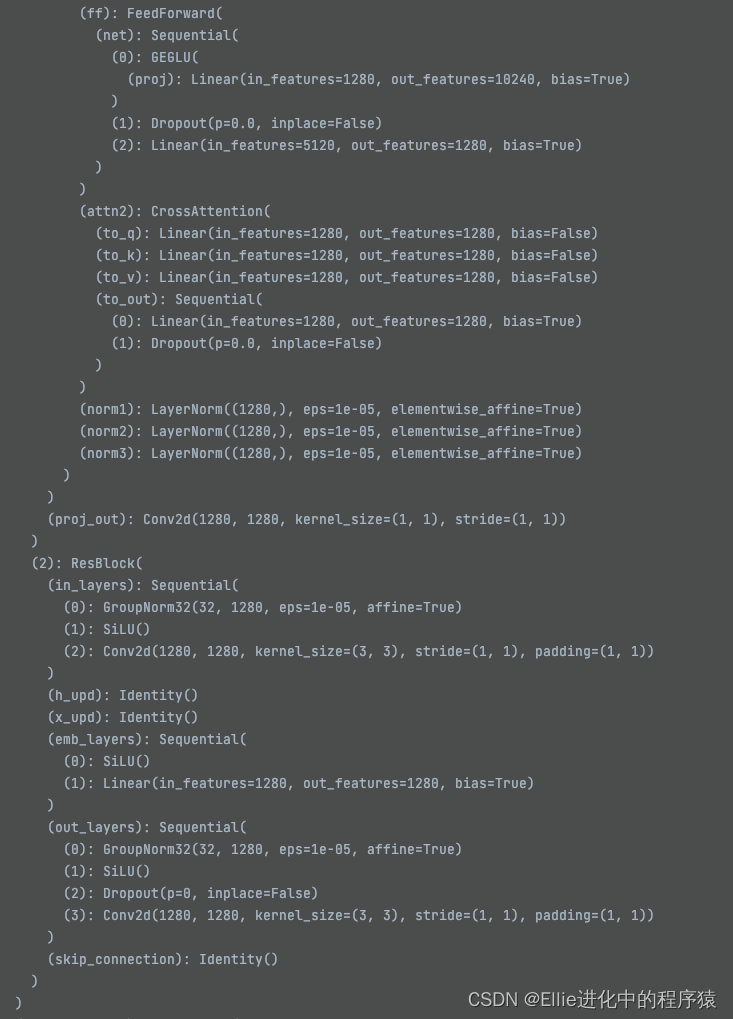
最后output
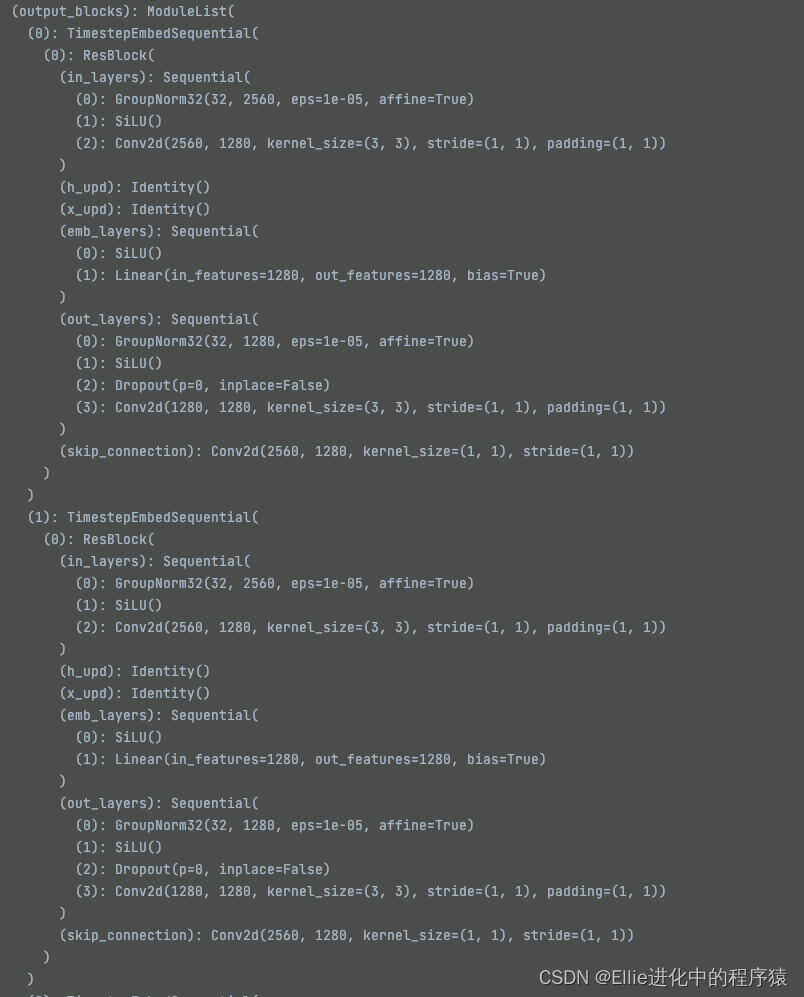
time2多了个upsample,好吧每个都不一样
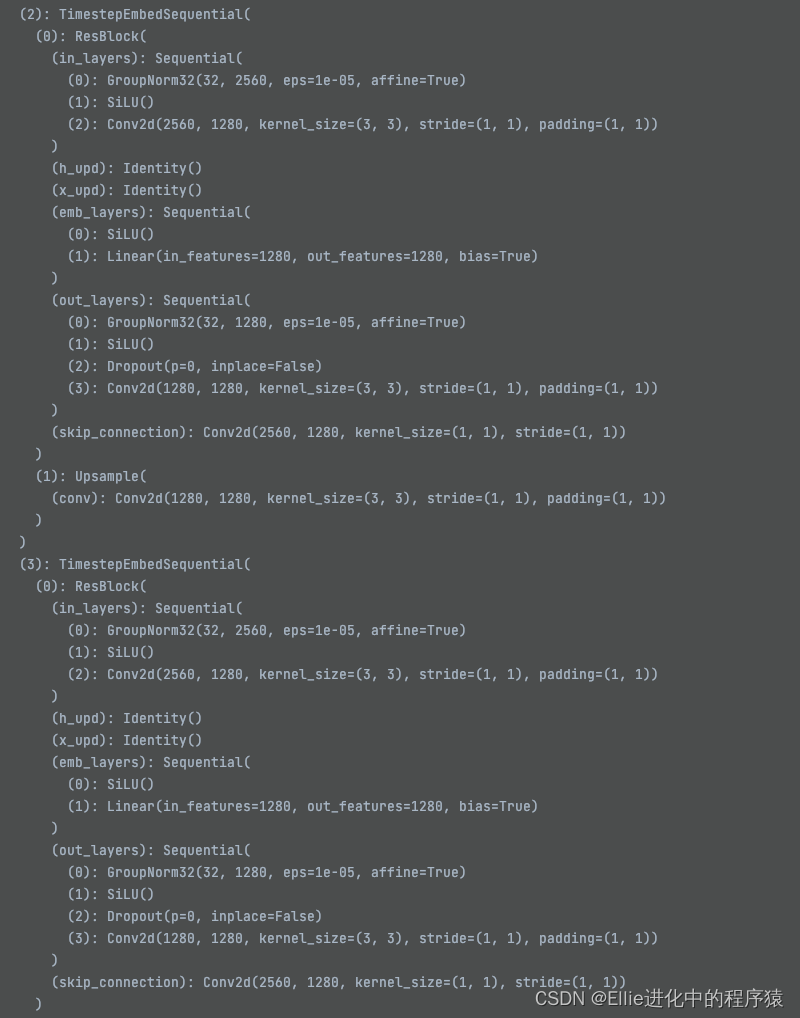
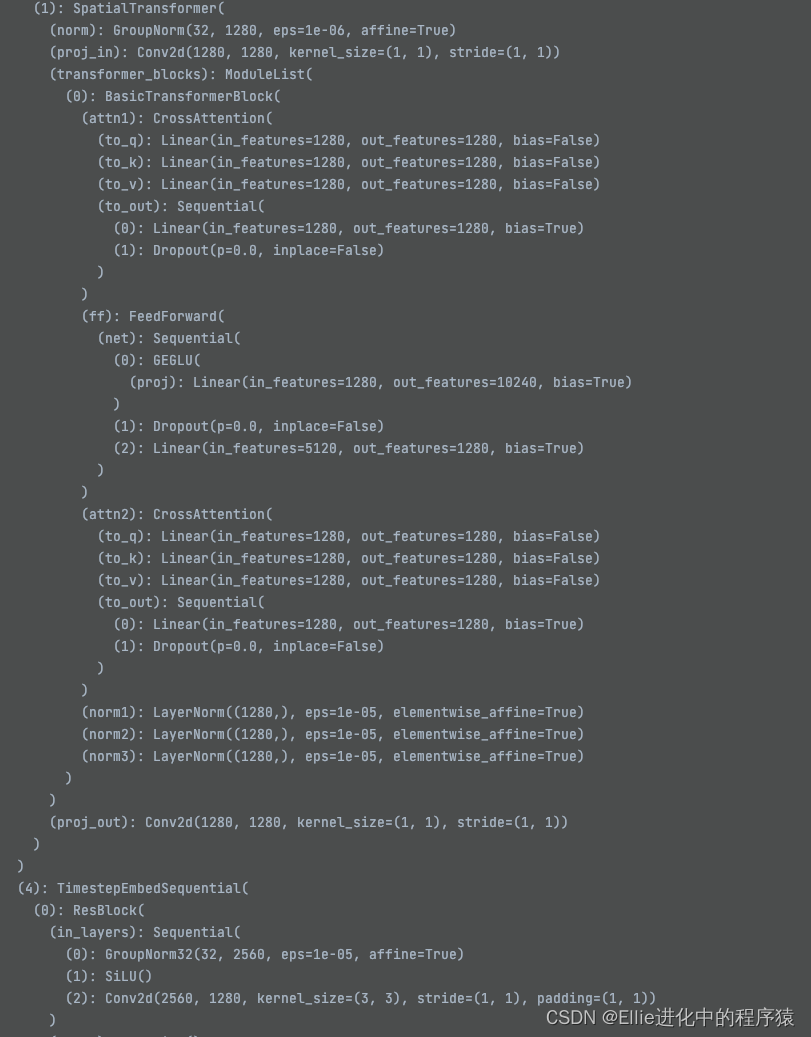
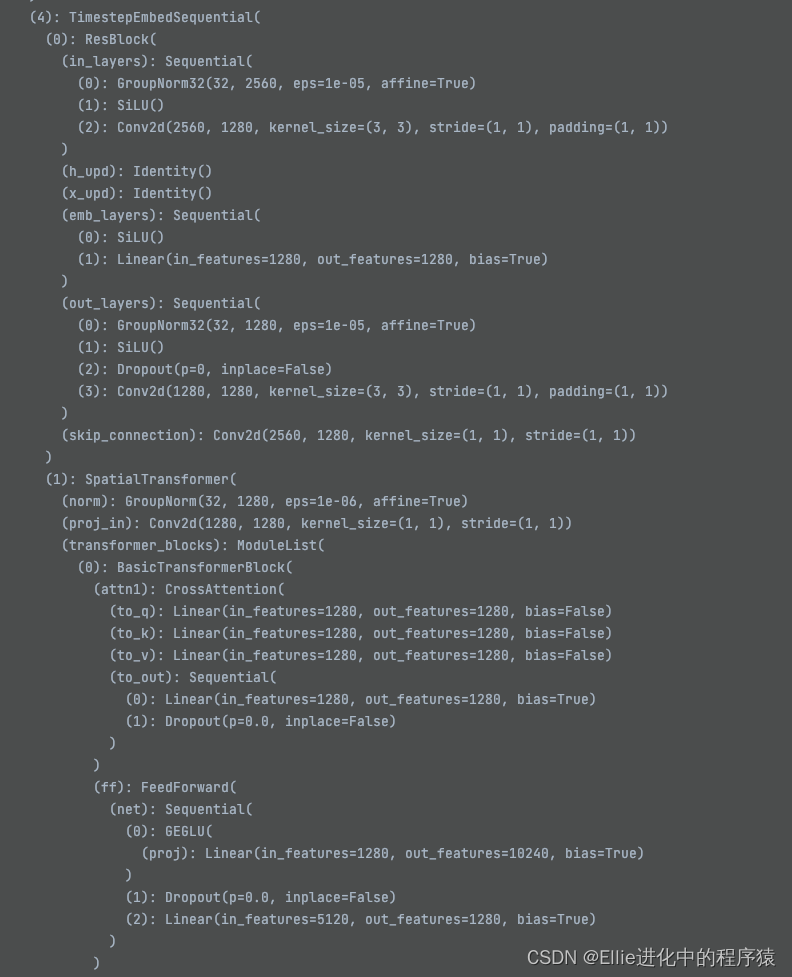
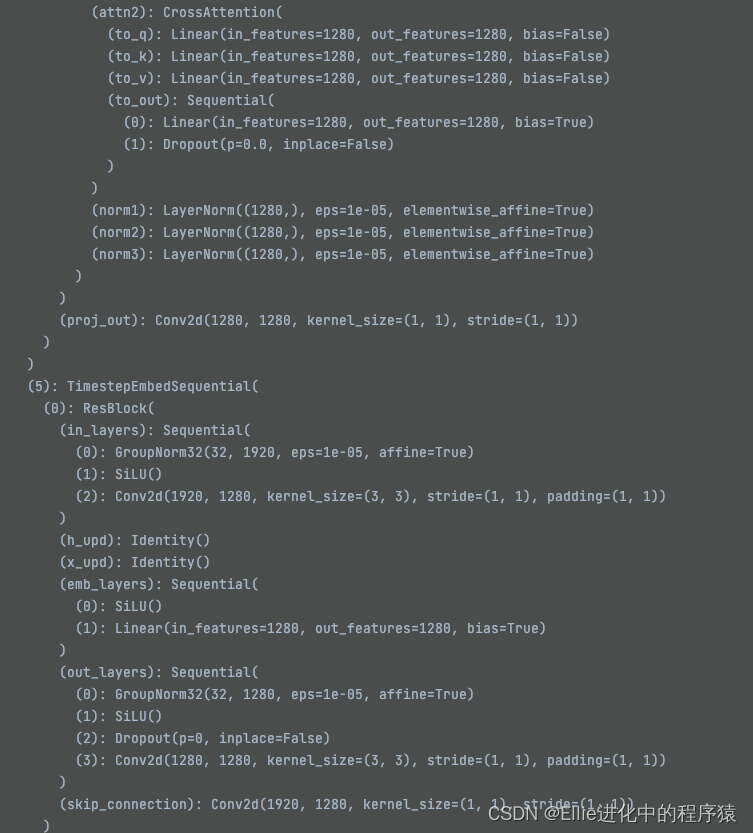
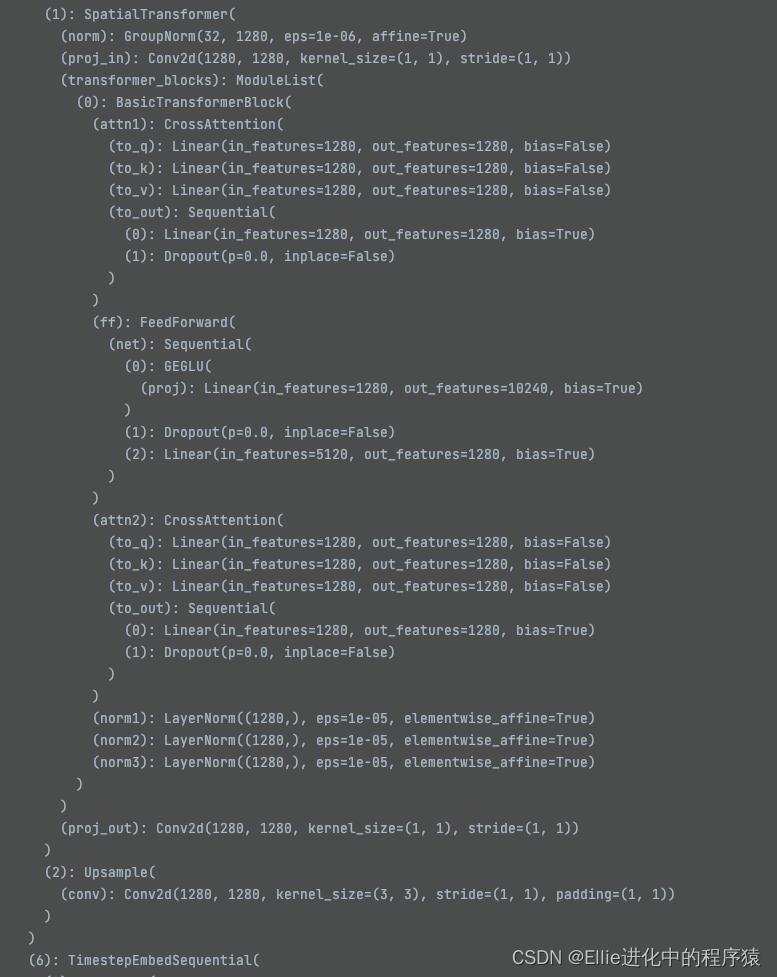
我放弃,这个也有11个
把断点放到openAImodel 中的682 self.out哪里
自己看去吧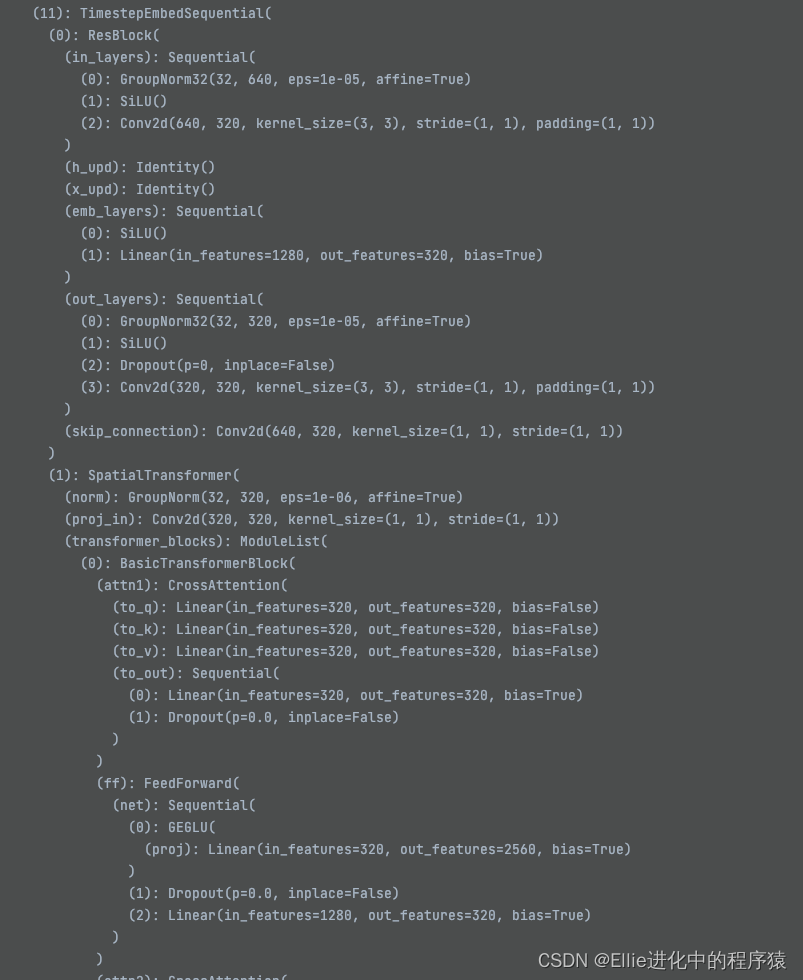

溜溜,明天继续整理
day02
taming transformer 直接看VQGAN1 的代码即可!
其中vqvae中 quantize 用到了einsu,,VectorQuantizer
矢量量化器














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









