







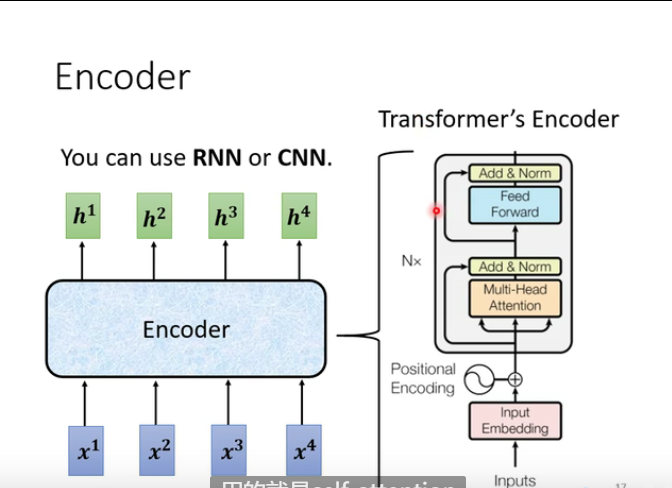
seq2seq的模型很多,输入一排向量,输出一排向量,可以使用self-attention,rnn,cnn,而transformer使用的就是self-attention
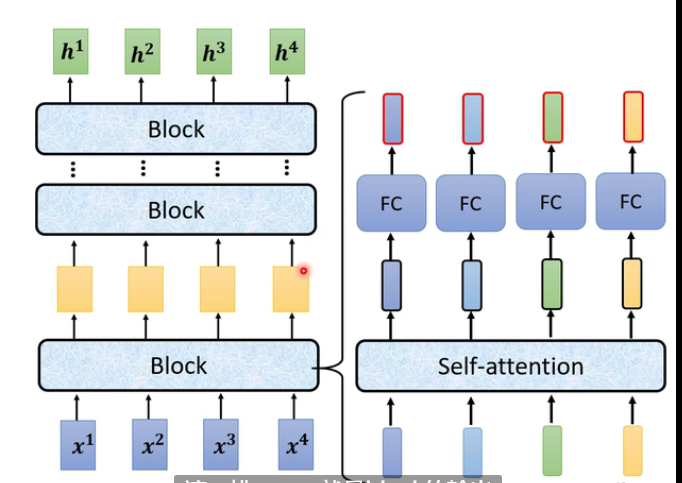
transformer 的Encoder结构
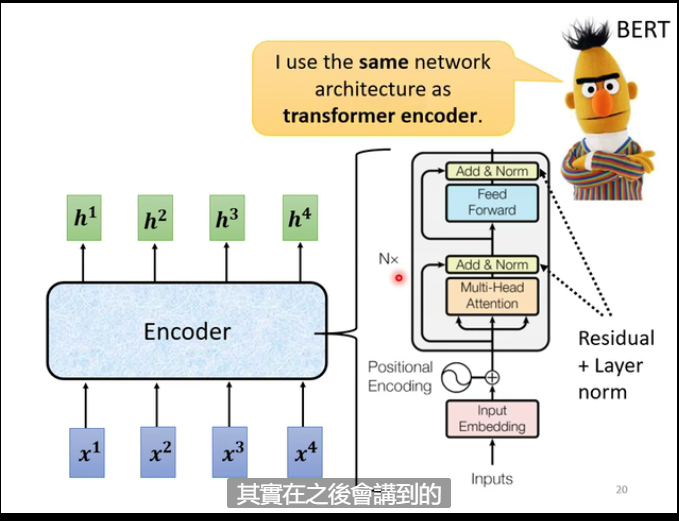
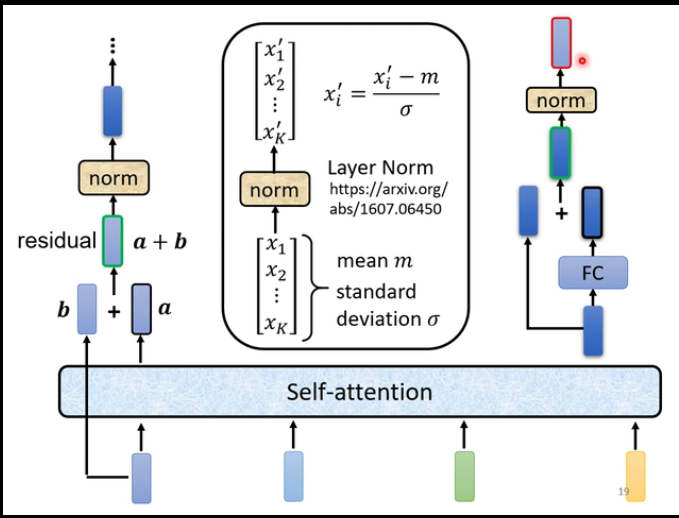
- residual
- norm (Layer Norm)
transformer的Decoder - Autoregressive结构

Autoregressive
这里有一个问题,Decoder的下一个输出为下一个的输入,会不会造成 Error Propagation的问题?
Self-attention ------> Masked Self-attention



transformer的Decoder Non-autoregressive结构

AT vs NAT

Encoder 和 Decoder的通信

在两部分的交汇处,即Cross attention的部分,有两块来自Encoder,一块篮子Decoder,
Cross attention的过程

1.输出BEGIN

2.输入第一个的输出

这是一篇用seq2seq做语音辨识的模型,采用了Cross Attention的机制,颜色越深的地方,代表这个位置算出的α的值就大,也就是更有主导的作用
transformer的training tips


因为像语音合成相关的任务,输出都从单调从左向右的,但是做predict的时候可能输出时的attention不是从左向右单调的,此时可以使用guided attention来强迫机器学习的时候 的attention时从左向右的。















 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









