







前言
FFM算法,全称是Field-aware Factorization Machines,是FM(Factorization Machines)的改进版。
来源:
最初的概念来自Yu-Chin Juan(阮毓钦,毕业于中国台湾大学,现在美国Criteo工作)与其比赛队员,是他们借鉴了来自Michael Jahrer的论文中的field概念提出了FM的升级版模型。通过引入field的概念,FFM把相同性质的特征归于同一个field。
1、 FFM原理
在CTR预估中,通常会遇到one-hot类型的变量,会导致数据特征的稀疏。未解决这个问题,FFM在FM的基础上进一步改进,在模型中引入类别的概念,即field。将同一个field的特征单独进行one-hot,因此在FFM中,每一维特征都会针对其他特征的每个field,分别学习一个隐变量,该隐变量不仅与特征相关,也与field相关。
1.1 引入field
以feed流推荐场景为例,我们多引入user维度用户年龄信息,其中性别和年龄同属于user维度特征,而tag属于item维度特征。在FM原理讲解中,“男性”与“篮球”、“男性”与“年龄”所起潜在作用是默认一样的,但实际上不一定。FM算法无法捕捉这个差异,因为它不区分更广泛类别field的概念,而会使用相同参数的点积来计算。
在FFM(Field-aware Factorization Machines )中每一维特征(feature)都归属于一个特定和field,field和feature是一对多的关系。如下表所示:
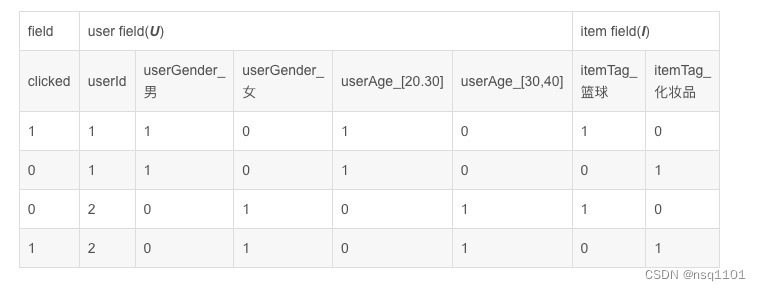

1.2 组合特征
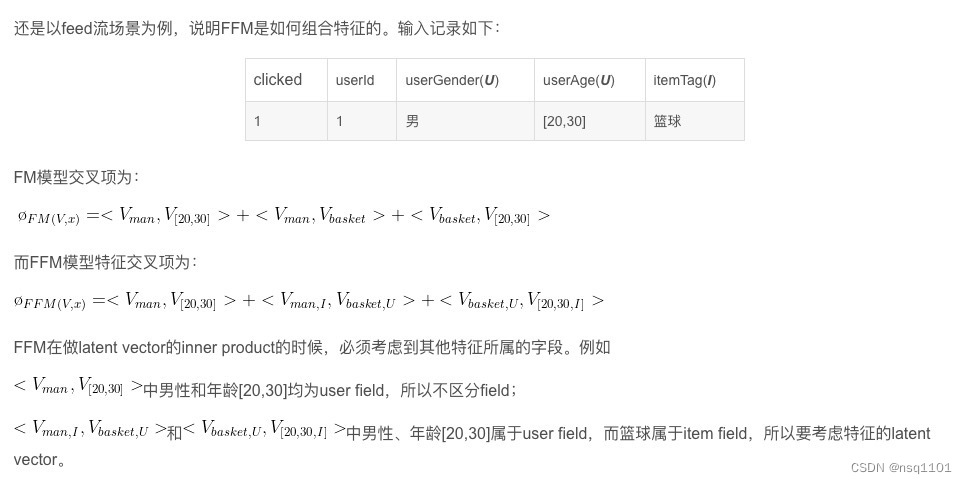
2、 实战例子
mac :
- pip install cmake
- 提示安装东西,点击同意
- pip install xlearn
- 成功后执行下面例子
import xlearn as xl
# 训练
ffm_model = xl.create_ffm() # 使用FFM模型
ffm_model.setTrain(r"./small_train.txt") # 训练数据
ffm_model.setValidate(r"./small_test.txt") # 校验测试数据
# param:
# 0. binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: accuracy
param = {'task': 'binary', 'lr': 0.2,
'lambda': 0.002, 'metric': 'acc'}
# 开始训练
ffm_model.fit(param, './model.out')
# 预测
ffm_model.setTest(r"./small_test.txt") # 测试数据
ffm_model.setSigmoid() # 归一化[0,1]之间
# 开始预测
ffm_model.predict("./model.out", "./output.txt")
xlearn 使用手册
https://xlearn-doc-cn.readthedocs.io/en/latest/python_api/index.html#id4
3、 FFM应用
3.1 场景介绍
在DSP或者推荐场景中,FFM主要用来评估站内的CTR和CVR,即一个用户对一个商品的潜在点击率和点击后的转化率。
CTR和CVR预估模型都是在线下训练,然后线上预测。两个模型采用的特征大同小异,主要分三类:
- 用户相关的特征
年龄、性别、职业、兴趣、品类偏好、浏览/购买品类等基本信息,以及用户近期点击量/购买量/消费额等统计信息 - 商品相关的特征
商品所属品类、销量、价格、评分、历史CTR/CVR等信息 - 用户-商品匹配特征
浏览/购买品类匹配、浏览/购买商家匹配、兴趣偏好匹配等
为了应用FFM模型,所有的特征必须转换成"field_id:feat_id:value"的格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值。
- 数值型特征比较容易处理,只需分配单独的field编号,如用户评分、商品的历史CTR/CVR等。
- categorical特征需要经过One-Hot编码转成数值型,编码产生的所有特征属于同一个field,且特征的值只能是0或1,比如用户的性别、年龄段、商品的品类等。
- 除此之外,还有第三类特征,比如用户浏览/购买品类,有多个品类id且用一个数值衡量用户浏览或购买每个品类商品的数量。这类特征按照categorical特征处理,不同的只是特征值不再是0或1,而是代表用户浏览或购买的数量。
- 按前述方法得到field_id后,再对转换后特征顺序编号,得到feat_id,特征的值也可以按照之前的方法获得。
CTR、CVR预估样本的类别是按不同方式获取的。CTR预估的正样本是站内点击的用户-商品记录,负#样本是展现但未点击的记录;CVR预估的正样本是站内支付(发生转化)的用户-商品记录,负样本是点击但未支付的记录。
3.2 细节点
训练FFM的过程中,小细节值得特别关注
-
第一,样本归一化。
FFM默认是进行样本数据的归一化,即 pa.normpa.norm 为真;若此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。 -
第二,特征归一化。
CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到 [0,1][0,1] 是非常必要的。 -
第三,省略零值特征。
从FFM模型的表达式可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
4、FFM vs FM
- FM是FFM的特例
- FFM在FM的基础上提出了field的概念,FM模型中每个特征只有一个隐向量,而FFM则有多个隐向量,点乘时根据对应field进行选择
- 从算复杂度来看,FM通过化简可以将复杂度降到O(kn),而FFM则是O(kn^2)
FFM优缺点
- FFM优点:
增加field的概念,同一特征针对不同field使用不同隐向量,模型建模更加准确 - FFM缺点:
计算复杂度比较高,参数个数为nfk,计算复杂度为O(kn2)
5、 总结
- 从理论上分析,FFM的参数因子化方式具有一些显著的优势,特别适合处理样本稀疏性问题,且确保了较好的性能;
- 从应用结果来看,站内CTR/CVR预估采用FFM是非常合理的,各项指标都说明了FFM在点击率预估方面的卓越表现。
















 2528
2528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











