




 本文介绍了关键短语提取的几种典型方法,包括TF-IDF、YAKE、TextRank、SIFRank和BERT-KPE。这些方法在无监督和有监督的场景下,通过不同的统计特征和模型,有效地从文本中抽取关键信息,应用于文档摘要、索引和分类等任务。
本文介绍了关键短语提取的几种典型方法,包括TF-IDF、YAKE、TextRank、SIFRank和BERT-KPE。这些方法在无监督和有监督的场景下,通过不同的统计特征和模型,有效地从文本中抽取关键信息,应用于文档摘要、索引和分类等任务。
随着互联网文本相关数据呈指数级增长,如何快速有效地抽取和整理相关关键信息成为一个重要的研究课题。与关键词不同,关键短语可能由多个词组成,其文本语义描述更为丰富,表达更为完整。除此之外,关键短语构成了一个简洁的概念性文档摘要,有助于语义索引、文档聚类和分类等多个任务的效果提升。
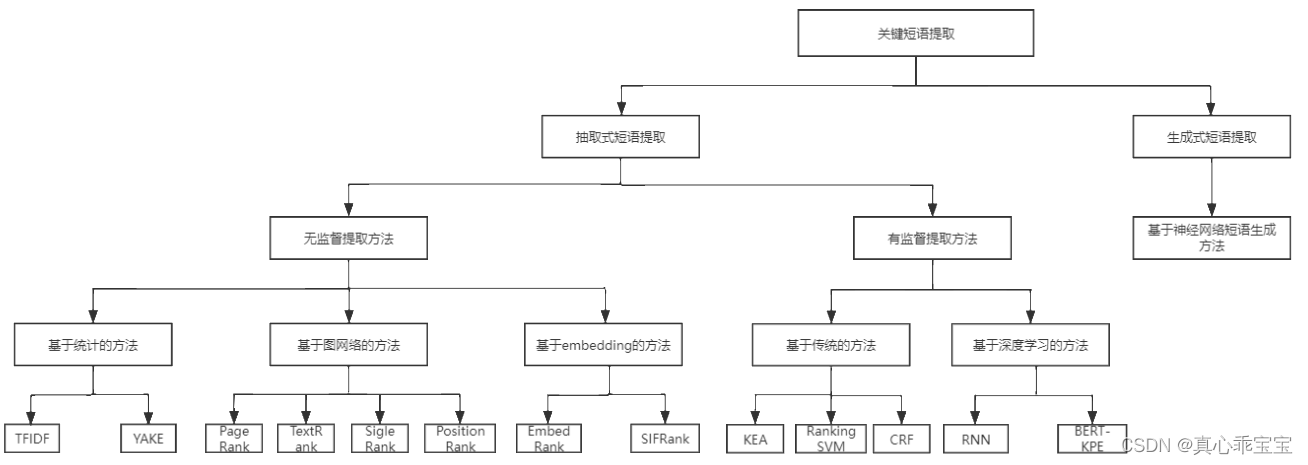
其中抽取式短语提取中,无监督提取方法比较典型的有TF-IDF、YAKE、TextRank、SIFRank等,有监督提取方法比较典型的有CRF、BERT-KPE等。
(1)TF-IDF:TF-IDF是一种很简单但却很有效的方法,常用于信息检索和文本挖掘的常用加权技术。用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
(2)YAKE:YAKE是一种关键字提取方法,它利用单个文档的统计特征来提取关键字,主要通过五个方面来计算关键词的重要度:是否大写、词的位置、词频、上下文关系、词在多个剧中出现的频率,其优势在于它不依赖与外部语料库、文本文档的长度、语言或领域。与TF-IDF相比,它在单个文档的基础上提取关键字,并且不需要庞大的语料库。
(3)TextRank:TextRank算法是基于PageRank算法,PageRank算法其中图的节点是网页,而TextRank是词。最原始的PageRank算法是无权重的图,而TextRank是有权重的图,其计算步骤如下:
a. 预处理:文本分词,然后用标注工具进行标注,获取重要的词性;
b. 构建图:将处理后的词作为图的节点,边根据这些词是否在一个滑动窗口共现,进行边的连接。初始各节点权重都为1,然后进行迭代;
c. 计算分值:所有节点权重分值计算完后,选取top个节点,再根据设置的窗口大小,计算更高的n-gram关键词分值,最后根据分值,获取top K个关键词。
(4)SIFRank:SIFRank比较适合短文本的关键词抽取,而SIFRank+大幅增加了长文本的关键词抽取效果。
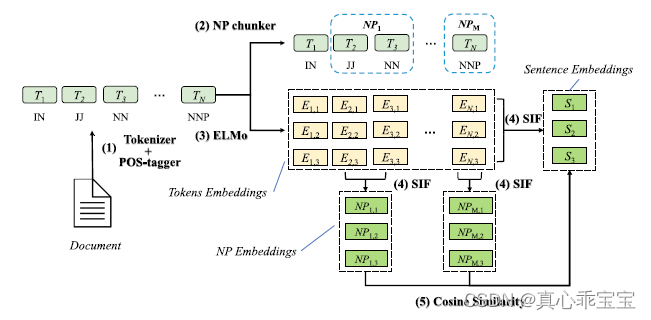
a. 人工标注:分词+标词性;
b. 获取候选关键词列表:利用正则表达式确定名词短语(例如:形容词+名词),将名词短语作为候选关键短语;
c. 通过预训练语言模型,得到关键词的embedding;
d. 同样地,得到句子或文档的embedding;
e. 计算c与d结果的余弦相似度,选取topN作为其最终提取的关键词。
(5)BERT-KPE:JointKPE 联合采用了两个子网络,一个是分块网络(chunking network)来识别高质量的短语,一个排名网络(ranking network)来学习短语的显著性。JointKPE尤其擅长预测长的关键词,并且擅长提取的这些关键词一部分不是实体,但却是有意义的短语。
a. 使用BERT将文档D编码成向量H,获得词表征,H=BERT{w1, w2, …,wn},H={h1, h2, …, hn};
b. 使用CNN融合k个字组成的embedding(上下文),得到相应的n-gram表达;
c. 使用Chunking network预测该n-gram是否是关键词短语候选;
d. 使用Ranking network对n-gram表达进行排序;
e. 对Chunking network和Ranking network进行联合训练
参考链接:
[1] https://wuwt.me/2021/11/12/unspervised-keyword-extract/
[2] https://zhuanlan.zhihu.com/p/126733456
[3] https://wenge.com/content/details_53_1886.html
[4] https://blog.csdn.net/BGoodHabit/article/details/108926383
[6] https://ieeexplore.ieee.org/abstract/document/8954611
[7] https://www.sciencedirect.com/science/article/pii/S0020025519308588
[8] https://aclanthology.org/W04-3252.pdf
[9] http://web.mit.edu/6.033/2004/wwwdocs/papers/page98pagerank.pdf


















 1273
1273


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








